AIが「上手に忘れる」世界初の新技術で信頼性向上へ
近年、AI(人工知能)の進化は目覚ましく、私たちの生活や社会のさまざまな場面で活用されています。特に、大量のデータから学習することで、人間には難しい高度な判断や予測を可能にする大規模なAIモデル(大規模視覚言語モデル:VLMなど)は、その汎用性の高さから多岐にわたる分野で注目を集めています。
しかし、この「なんでも知っている」とも言えるAIの汎用性が、時に予期せぬ問題を引き起こすことがあります。例えば、自動運転システムが、道路脇のポスターに描かれた車のイラストを「本物の車」と誤認識してしまうようなケースです。このような誤認識は、システムの信頼性を損ない、場合によっては深刻な事故につながるリスクもはらんでいます。
こうした課題に対し、東京理科大学と産業技術総合研究所の共同研究グループは、AIが学習した知識の中から、特定の「ドメイン」(データの表現形式や種類)だけを「上手に忘れる」ことができる世界初の新技術「近似ドメインアンラーニング(Approximate Domain Unlearning: ADU)」を開発しました。この技術は、AIの不要な誤認識を防ぎ、より安全で信頼性の高いAIシステムの実現に貢献すると期待されています。

なぜAIは「忘れる」必要があるのか?大規模AIモデルの課題
AI、特に大規模視覚言語モデル(VLM)は、膨大な画像とテキストのデータから学習することで、非常に高い精度でさまざまな物体を認識する能力を持っています。これにより、医療診断、製品検査、セキュリティ監視など、幅広い分野での応用が進んでいます。
しかし、この強力な汎化能力(どんな種類のデータでもうまく処理できる能力)が、かえって問題となることがあります。AIがあらゆる情報を区別なく認識してしまうことで、以下のような課題が生じるのです。
-
誤認識のリスク: 特定の用途においては不要な情報まで認識してしまうことで、誤った判断を下す可能性があります。前述の自動運転の例のように、広告の画像を本物と誤認すれば、交通状況の解析に重大な支障が出ます。
-
信頼性の低下: 不要な情報が混じることで、AIの判断の根拠が不明瞭になり、システム全体の信頼性が損なわれることがあります。
-
処理の非効率化: 必要のない知識まで保持していると、データの処理に余計な負荷がかかり、システムの効率が低下する原因にもなります。
これまでのAIにおける「忘却」技術としては、特定のデータ(サンプル単位)や特定のカテゴリ(クラス単位、例:「人」や「自動車」全体)を対象とするものが主流でした。しかし、同じ「自動車」の画像であっても、「実写」なのか「絵画」なのか「スケッチ」なのか、といった「ドメイン」の違いによって、その情報が持つ意味や重要性は大きく異なります。
例えば、交通監視システムにとって重要なのは「実写の車」の情報であり、「絵画の車」の情報は不要です。従来の技術では、「車」というクラス全体を忘却するか、あるいは個別の「絵画の車」のデータ一つひとつを忘却するしかなく、非常に柔軟性に欠けていました。ここで必要とされたのが、「特定のドメインだけ」を選択的に忘却する、より高度な知識制御技術だったのです。
世界初の新技術「近似ドメインアンラーニング(ADU)」とは
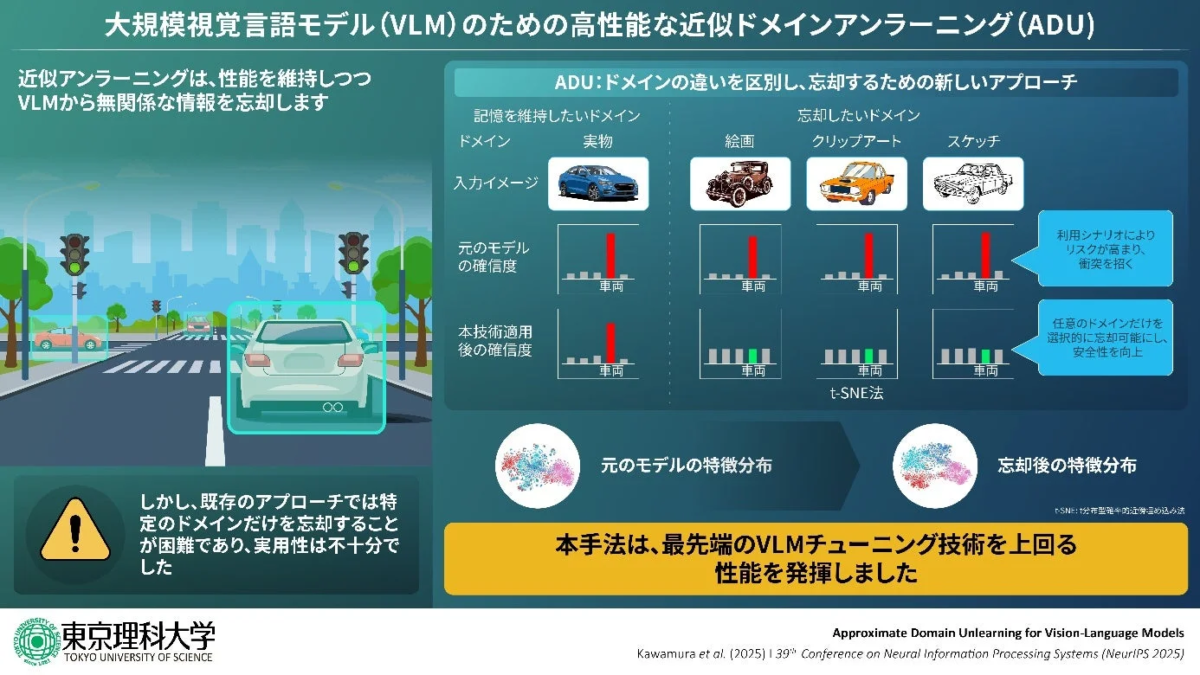
東京理科大学と産業技術総合研究所の共同研究グループが開発した「近似ドメインアンラーニング(ADU)」は、事前学習済み大規模視覚言語モデル(VLM)に対し、特定のドメインに属するデータだけを認識できないように「忘却」させることを可能にした、世界初の画期的な技術です。
この技術の最大のポイントは、「ドメイン単位」で忘却できる点にあります。例えば、「実写」「絵画」「クリップアート」「スケッチ」といった様々な表現形式の自動車画像があった場合、「実写以外を忘却する」と指定することができます。これにより、実写の自動車画像の認識精度は維持しつつ、他のドメインの自動車画像の認識精度を選択的に低下させることが可能になります。
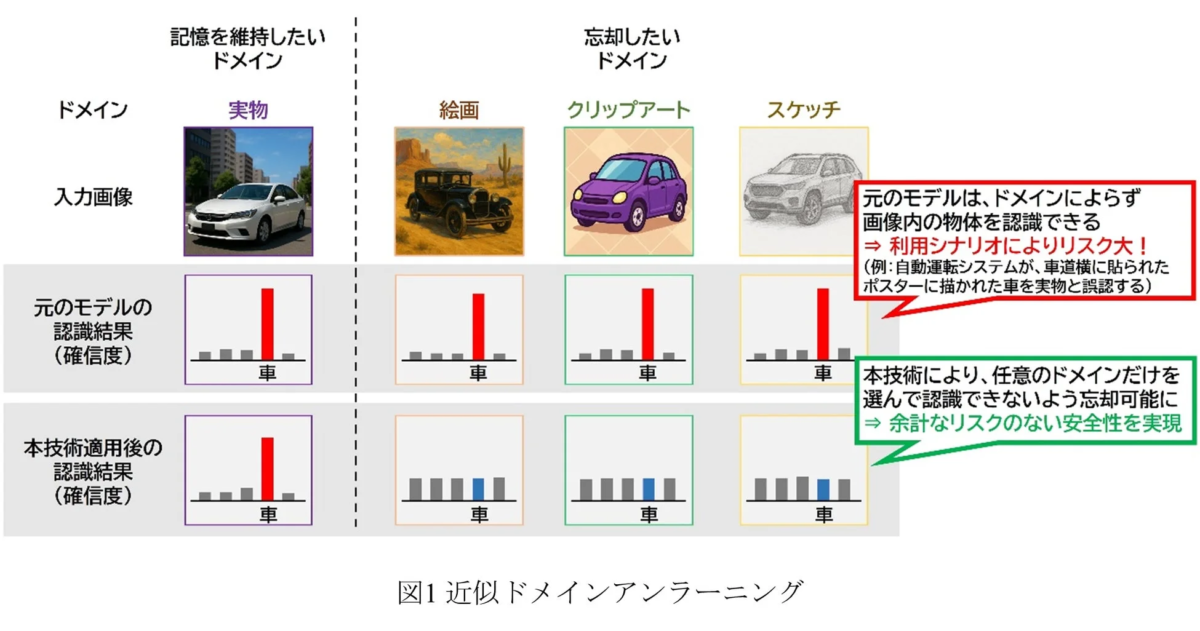
図1を見ると、元のモデルでは実物、絵画、クリップアート、スケッチのどの「車」も高い確信度で「車」と認識しています。しかし、本技術を適用すると、実物の「車」の認識精度は保ちつつ、絵画、クリップアート、スケッチの「車」に対する確信度が著しく低下していることがわかります。これにより、自動運転システムがポスターの車を誤認するリスクなどを効果的に低減できるのです。
従来のアンラーニング技術では、このような詳細かつ柔軟な知識制御は困難でした。VLMの高い汎化能力は、異なるドメインの画像であっても、内部で非常に似た特徴として扱ってしまうため、特定のドメインだけを区別して忘却することが極めて難しかったのです。この課題を解決するために、研究グループは二つの新しい技術を導入しました。
ADUを可能にした二つの核心技術
研究グループは、ドメイン単位での選択的忘却という困難な課題を解決するために、以下の二つの革新的な技術を導入しました。
1. Domain Disentangling Loss (DDL)によるドメイン分離
大規模VLMの内部では、異なるドメインに属する画像の特徴が複雑に絡み合っており、明確に区別することが難しい状態でした(図2a)。これが、特定のドメインだけを忘却しようとしても、他のドメインに影響を与えてしまう原因となっていました。
そこで導入されたのが、「Domain Disentangling Loss (DDL)」という新しい損失関数です。このDDLは、AIが学習を進める過程で、各画像のドメインをより正確に識別できるように誘導する役割を果たします。具体的には、「ドメインの分布が分離されている状態」と「ドメインを精度良く識別できる状態」が密接に関連しているという知見に基づき、AIにドメインごとの特徴を明確に分離するよう促します。
このDDLの導入により、元々は絡み合っていた異なるドメインの特徴分布を効果的に分離することに成功しました(図2b)。ドメインが明確に分離されることで、特定のドメインだけをターゲットとして忘却したり、あるいは維持したりすることが、より容易になったのです。

2. Instance-wise Prompt Generator (InstaPG)による適応的なドメイン特性把握
ドメインの表現は一様ではありません。例えば、「絵画」というドメインであっても、非常に写実的な絵もあれば、抽象画のように元の物体の形がほとんど分からないような絵もあります。このように、同じドメイン内でも表現の多様性が非常に大きいことが、AIがドメインの特徴を一律のルールで捉えることを難しくしていました。
この課題に対処するため、研究グループは「Instance-wise Prompt Generator (InstaPG)」という機構をモデル内に導入しました。InstaPGは、入力される画像一つひとつに対して、その画像が持つドメインの特性を適応的にモデル化する役割を担います。これにより、AIは画像ごとのドメイン表現の微妙な違いや多様性に柔軟に対応できるようになり、より精度の高いドメイン単位での忘却が可能になりました。
飛躍的な性能向上と今後の応用
これらの新技術を組み合わせた「近似ドメインアンラーニング(ADU)」は、4種類の標準的な画像認識テストデータを用いて評価されました。その結果、従来のクラス単位での近似アンラーニング技術をドメイン単位の忘却に適用した場合と比較して、平均で約1.6倍もの性能向上が確認されました。特に、最も難易度の高い条件下では、約1.7倍という顕著な性能改善が見られ、本手法の有効性が実証されました。
この研究成果は、AIが不要な知識を抑制しつつ、必要な知識はしっかりと保持するという、新しいAIの知識制御の枠組みを提示しています。これは、AIモデルの安全性向上や、特定の目的に応じた効率的な再利用を可能にするものです。AIが「ちょうどよい」知識だけを持つようになることで、より信頼性が高く、使いやすいシステムが実現すると期待されています。
AIの安全性と信頼性を高める具体的な応用例
ADU技術がもたらす恩恵は、多岐にわたる分野で期待されます。
交通監視・自動運転システム
最も具体的な応用例として挙げられるのが、交通監視システムや自動運転システムです。これらのシステムでは、「実物の人」や「実物の自動車」を正確に認識することが極めて重要です。しかし、現状のAIは、街頭ディスプレイや広告に描かれた「人」や「自動車」のイラスト、アニメーションなども、実物と区別なく認識してしまうことがあります。
ADU技術を導入すれば、「実写」以外のドメイン(絵画、クリップアート、スケッチなど)の「人」や「自動車」の認識を意図的に忘却させることができます。これにより、AIが誤ってイラストを本物と認識することによる誤作動や解析結果の誤りを防ぎ、システムの安全性を大幅に向上させることが可能になります。
セキュリティ・プライバシー保護
特定のドメインの画像を忘却させる能力は、セキュリティやプライバシー保護の観点からも重要です。例えば、顔認識システムにおいて、特定の種類の画像(例:古い写真、特定の加工が施された画像)を認識しないようにすることで、プライバシー侵害のリスクを低減したり、特定の状況下での誤認を防いだりすることができます。
特定分野特化型AIの開発
汎用AIモデルは強力ですが、特定の専門分野に特化したAIを開発する際には、不要な知識が邪魔になることがあります。ADUを活用すれば、汎用モデルから特定の分野に不要なドメインの知識を効率的に削除し、その分野に最適化された軽量で高性能なAIモデルを構築することが可能になります。これにより、開発コストの削減や処理速度の向上が期待できます。
国際会議での発表と研究者の期待
本研究成果は、機械学習分野の最高峰の国際会議の一つである「Neural Information Processing Systems (NeurIPS 2025)」にて、Spotlight論文として発表される予定です。これは、研究の質の高さと、その成果が学術界において高く評価されていることを示しています。
本研究を主導した東京理科大学の入江豪准教授は、「高性能なAIモデルを誰もが自由に利用できる時代において、これらのモデルをいかに効果的に活用するかが大きな関心事となっています。持続的な実運用には、状況や目的に応じてAIの機能や性能を適切に制御できる仕組みが不可欠です。AIがドメインを区別せず汎化的に認識する性質が、応用上の障壁となり得るという問題意識から、前例のない『近似ドメインアンラーニング』という技術の創出に挑戦しました。本研究成果は、オーバースペックになりがちなAIモデルを『ちょうどよいもの』へと転換し、より安全で使いやすく、信頼性の高いAIモデルの実現に貢献するものと期待しています」とコメントしています。
このコメントからは、単に性能を追求するだけでなく、AIが社会で安全かつ適切に機能するための基盤技術を確立しようとする強い意志が感じられます。
AIの未来を拓く「上手に忘れる」能力
「近似ドメインアンラーニング」技術は、AIの能力を単に高めるだけでなく、その「使い方」をより賢く、安全にするための重要な一歩です。AIが不必要な情報を適切に忘却できるようになることで、誤認識によるリスクを減らし、特定の目的に特化した、より信頼性の高いAIシステムを構築することが可能になります。
この技術の発展は、自動運転、医療、セキュリティなど、AIの応用が期待されるあらゆる分野において、AIモデルの安全性向上と効率的な再利用を促進し、私たちの社会にさらなる恩恵をもたらすことでしょう。AIが「上手に忘れる」能力を身につけることで、AIはより人間にとって「信頼できるパートナー」へと進化していくに違いありません。
用語解説
視覚言語モデル (Vision-Language Model: VLM)
視覚情報(画像や動画など)と言語情報(テキスト)を同時に理解し、処理できるAIモデルのことです。例えば、画像の内容を説明する文章を生成したり、テキストの指示に基づいて画像を検索したりすることができます。
クラスとドメイン
-
クラス: AIが認識する対象の「カテゴリー」を指します。「何を認識するか」を表し、例えば「犬」「猫」「自動車」といった具体的な物体がクラスに該当します。
-
ドメイン: データの「出所」や「表現スタイル」を指します。「どのような形式・表現で存在するか」を表し、例えば「実写」「絵画」「スケッチ」「クリップアート」などがドメインに該当します。同じクラスの「自動車」でも、実写の自動車とスケッチの自動車では異なるドメインに属すると考えられます。
t-SNE法
高次元の複雑なデータを、人間が理解しやすい2次元または3次元のグラフに圧縮して可視化するための統計的手法です。AIが内部でどのように情報を処理し、異なる種類のデータがどのように分布しているかを視覚的に理解するのに役立ちます。
関連リンク
- 東京理科大学WEBページ: https://www.tus.ac.jp/today/archive/20251202_8376.html

