
GMOインターネットグループのGMOインターネット株式会社が、NVIDIAテクノロジを駆使した高性能GPUクラウドサービス「GMO GPUクラウド」において、最新の「NVIDIA Blackwell Ultra GPU」を搭載した「NVIDIA HGX B300 AI インフラストラクチャ」(以下、HGX B300)のクラウドサービスを2025年12月16日より国内最速クラスで提供開始しました。

このサービスは、サーバー1台を専有する「ベアメタル構成」を採用しており、AI推論モデルに最適化されたHGX B300 AIインフラストラクチャの性能を最大限に引き出すことが可能です。これにより、大規模言語モデル(LLM)の高速推論や、エージェント型AIの開発など、最先端のAIワークロードに最適な高性能環境を国内から提供します。GMOインターネットは、AI・ロボティクス時代の研究開発だけでなく、その利活用を支える新たな計算基盤として、このサービスを展開していく方針です。
AI開発の進化と計算資源の需要増大
近年、企業による独自のLLM(大規模言語モデル)開発や、産業分野におけるAI・ロボティクスといった技術の急速な進化に伴い、高度な演算処理を可能にする大規模な計算資源の需要が飛躍的に高まっています。
AIモデルは日々巨大化し、推論処理にはリアルタイム性が求められ、さらには多様な生成形式への対応も必要とされています。これらの要求に応えるためには、クラウドインフラも常に進化し続ける「動的な技術基盤」であることが不可欠であり、最新技術へのアップデートが技術革新の鍵を握ると言えるでしょう。
GMOインターネットは、このような市場環境と技術的要請に応えるため、積極的に最新技術の導入を進めています。2024年4月15日には経済安全保障推進法に基づく特定重要物資「クラウドプログラム」の供給確保計画について経済産業省の認定を受け、同年11月22日からは国内最速クラスでNVIDIA Hopper GPU(NVIDIA H200)を提供しています。
-
経済安全保障推進法に基づく特定重要物資の安定的な供給の確保: https://www.meti.go.jp/policy/economy/economic_security/cloud/index.html
-
NVIDIA Hopper GPUについて: https://www.nvidia.com/ja-jp/data-center/h200/
そして今回、2025年5月14日に公表されたBlackwellアーキテクチャの最新世代である「HGX B300」への切り替えを決定しました。これにより、「GMO GPUクラウド」は、今後のAI開発・運用に求められる高い計算性能、拡張性、そして低レイテンシ(遅延の少なさ)通信に対応し、さらに進化したインフラ基盤として展開されます。
「GMO GPUクラウド(NVIDIA B300)」の全貌
「GMO GPUクラウド」のNVIDIA B300プランは、最先端のハードウェアとネットワーク構成により、AI開発に最適な環境を提供します。

1. GMO GPUクラウド概要
サービス名: GMO GPUクラウド ベアメタルプラン
提供開始日: 2025年12月16日
GPU構成: NVIDIA Blackwell Ultra GPU
GPUメモリ: 2.3 TB
CPU構成: Intel Xeon 6767P x2
メインメモリ: 3 TB
ローカルストレージ: 3.84TB NVMe Gen5 SSD x8
ネットワークストレージ: NFSファイルストレージ・オブジェクトストレージ(近日提供予定)
グローバル・ローカル・ストレージ回線(共用): NVIDIA BlueField-3 DPU 200Gbps x2
インターコネクト: NVIDIA Connect X-8 SuperNIC x8 合計6,400Gbps
ユースケース:
-
大規模言語モデルの高速学習とファインチューニング
-
AIのリーズニング(推論)と推論処理の高速化
-
コンピュータビジョンモデルの大規模データセットを用いた学習など
価格: 各社ごとにお見積り
2. NVIDIA Blackwell Ultra GPUの革新性
「NVIDIA Blackwell Ultra GPU」は、従来のNVIDIA H200と比較して大幅な性能向上を実現しています。

主なスペック向上点:
-
メモリ容量は288GB:H200の204%に相当し、より大規模なデータやモデルを扱えるようになります。
-
新たにFP4演算精度に対応:FP4(4ビット浮動小数点フォーマット)は、NVIDIAが設計したもので、他のFP4フォーマットよりも高い精度を実現しつつ、VRAM(GPUメモリ)の使用量を削減し、スループット(データ処理量)を改善します。これは、特にAI推論において、より多くのモデルを効率的に動かす上で非常に重要です。
-
FP8 Tensor Core性能も最大2.25倍に向上:FP8(8ビット浮動小数点フォーマット)の演算性能が向上することで、AI学習や推論の速度がさらに加速します。
NVIDIA Blackwellアーキテクチャについて: https://www.nvidia.com/ja-jp/data-center/technologies/blackwell-architecture/
3. NVIDIA B300がもたらすメリット
HGX B300は、大規模なAIモデルの学習と推論において、これまでにない効率と速度を提供します。

大規模学習の効率化
-
学習性能は最大4倍:前世代のH200と比較して、学習にかかる時間が大幅に短縮されます。
-
GPUメモリ容量や帯域幅など、主要性能が大幅に強化:大量のデータを高速に処理できるため、複雑なモデルの学習もスムーズに行えます。
-
ワットあたりの性能も向上:電力効率が改善され、運用コストの削減にも貢献します。
推論処理の飛躍的強化
-
推論性能は最大11倍:リアルタイム性が求められるAIアプリケーションにおいて、圧倒的な速度を実現します。
-
FP4対応により、VRAM使用量を削減しつつスループットを改善:メモリを効率的に使うことで、より多くのAI推論タスクを同時に実行できます。
-
GPUメモリ容量が過去最大:2.3TBという大容量メモリにより、巨大なAIモデルの推論も余裕を持って行えます。
これらの特徴により、大規模モデルの学習をより高速かつ省電力で実行できるようになり、AI開発のサイクルが劇的に短縮されます。
4. 超高速ネットワーク構成
HGX B300 AIインフラストラクチャは、超高速な通信環境も大きな特徴です。

8基の「NVIDIA ConnectX-8 SuperNICs」により、合計6,400Gbps(ギガビット/秒)という圧倒的な帯域幅を実現しています。さらに、複数のGPUを接続・拡張させる「NVIDIA Spectrum-X Ethernetスイッチ」との組み合わせにより、低レイテンシ(低遅延)設計が徹底されています。
-
NVIDIA ConnectX-8 SuperNICについて: https://www.nvidia.com/ja-jp/networking/products/ethernet/supernic/
-
NVIDIA Spectrum-X Ethernetスイッチについて: https://www.nvidia.com/ja-jp/networking/spectrumx/
この超高速通信環境は、大規模なAI学習時におけるデータ転送を劇的に高速化し、複数サーバーを組み合わせた分散学習環境においても安定した高性能を発揮します。AIモデルの学習には膨大なデータ転送が伴うため、このネットワーク性能はAI開発のボトルネックを解消する上で不可欠です。
5. NVIDIA B300とNVIDIA H200の徹底比較
NVIDIA HGX B300は、前世代のNVIDIA HGX H200と比較して、以下の点で大幅な進化を遂げています。
| NVIDIA HGX B300 | NVIDIA HGX H200 | |
|---|---|---|
| GPUメモリ | 計 2.3 TB(288GB HBM3e x8) | 計 1.1 TB(141GB HBM3e x8) |
| FP4 Tensor コア | 144PFLOPS/108PFLOPS | – |
| FP8 Tensor コア | 72PFLOPS | 32PFLOPS |
| FP16 Tensor コア | 36PFLOPS | 16PFLOPS |
| FP32 | 600TFLOPS | 540TFLOPS |
| 最大インターコネクト帯域 | 6,400Gbps | 3,200Gbps |
| NVLINK (GPU間帯域/GPU1基ごと) | 第5世代 (1,800GB/s) | 第4世代 (900GB/s) |
この比較表からもわかる通り、B300はGPUメモリ容量が約2倍、各種Tensorコアの演算性能も大きく向上しています。特に、FP4 Tensorコアの新規対応は、より効率的なAI推論を可能にする重要な進化です。また、GPU間の通信速度を示すNVLINKも第5世代へと進化し、帯域幅が2倍に拡大されたことで、GPU間のデータ連携がこれまで以上にスムーズになり、大規模な分散学習や推論のボトルネックを解消します。
ベアメタルプランの真価
今回提供が開始された「GMO GPUクラウド ベアメタルプラン」は、AI開発者にとって非常に大きなメリットをもたらします。
ベアメタルとは、仮想化ソフトウェアを介さずに、物理サーバーのハードウェアに直接アクセスできる環境のことです。これにより、GPUが持つ演算性能を最大限に引き出す「完全専有環境」が実現されます。仮想化によるオーバーヘッド(余分な処理)が発生しないため、AI推論処理に特化した演算能力を余すことなく活用できます。
この特性は、大規模言語モデルの高速推論や、エージェントAI開発といった、高い処理性能とリアルタイム性が求められる多様なワークロードに最適です。また、ベアメタル環境は高いセキュリティとカスタマイズ性を誇るため、特定の要件を持つAIプロジェクトにも柔軟に対応できます。
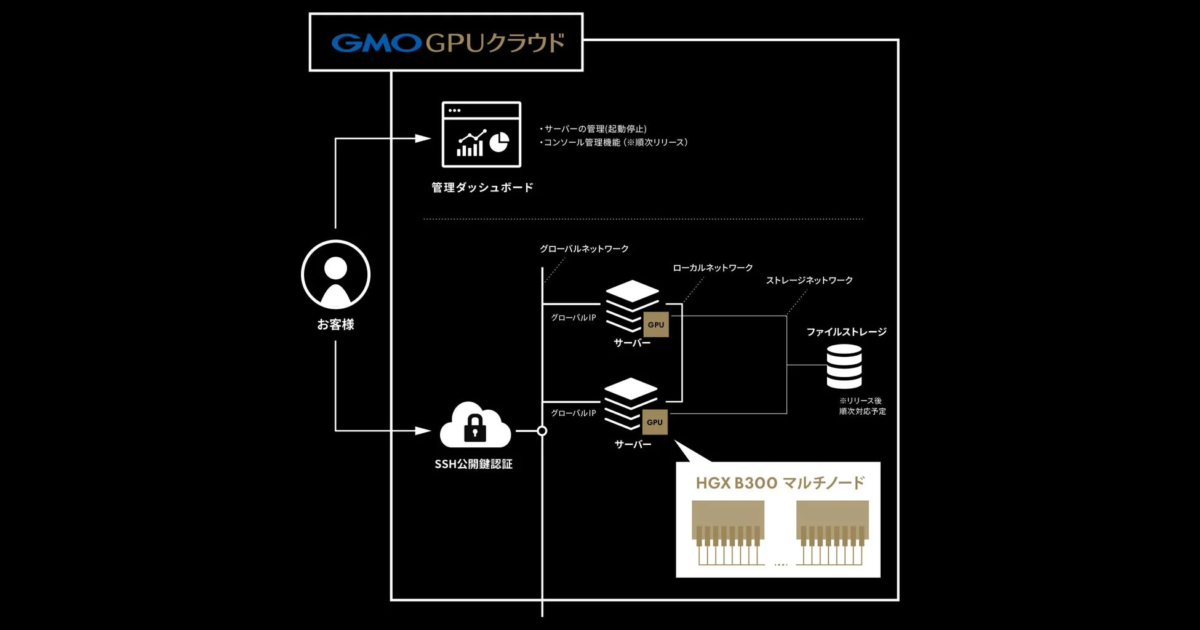
さらに、ベアメタルならではの自由度を保ちつつ、ユーザーがGPU環境を構築する際の手間を軽減する仕組みも備わっています。
主な特徴:
-
Ubuntu OS初期セットアップ済みで提供:OSのインストールや基本的な設定が不要で、すぐに開発を開始できます。
-
インターコネクトネットワーク設定済み(ローカルNWも利用可能):複数のGPUやサーバー間での高速通信に必要なネットワーク設定が完了しているため、複雑な設定作業が不要です。
-
管理ダッシュボードによるサーバー管理機能:サーバーの起動・停止などの基本的な管理操作を視覚的に行えます。
-
追加ストレージの利用が可能:必要に応じてストレージ容量を拡張できるため、大規模なデータセットも安心して扱えます。
これらの機能により、ユーザーは構築工数を抑えながら、高いパフォーマンスと柔軟なチューニング性を両立したGPU環境をすぐに利用できます。これにより、AI開発者はインフラ構築に時間を割くことなく、本来のAI開発に集中できるでしょう。
業界リーダーからの期待
今回のサービス提供開始にあたり、GMOインターネットとエヌビディアの両社からコメントが寄せられています。

GMOインターネット株式会社 代表取締役 社長執行役員 伊藤 正氏のコメント
「『GMO GPUクラウド』は、2024年11月のサービス開始以来、最先端のAI開発インフラを支えてまいりました。最先端で高性能な技術への取り組みと、安定した運用環境、きめ細かな技術サポートに一貫してこだわり続け、お客様のAI開発を支援することに挑み続けてまいりました。NVIDIA B300を国内最速で提供することは、日本発のAIイノベーションを次のステージへ加速させる取り組みにつながると確信しています。今後もNVIDIA様との技術連携を深め、エンジニアの挑戦を支えるAI開発基盤を磨き上げ、世界に通用する次世代AIの創出を力強く後押ししてまいります。」

エヌビディア 日本代表 兼 米国本社副社長 大崎 真孝氏のコメント
「日々、AI開発に挑む開発者・研究者にとって、莫大な計算資源にアクセスできる高性能かつ拡張性の高いコンピューティング環境は不可欠です。高効率な学習と高速推論を可能にするNVIDIA HGX B300を搭載した『GMO GPUクラウド』を国内で提供されることは、日本のAIインフラストラクチャをリードする大きな一歩と言えます。」
両氏のコメントからは、本サービスが日本のAI開発、ひいては産業全体に与えるポジティブな影響への期待の大きさが伺えます。
日本のAI産業を支える未来戦略
GMOインターネットは、「GMO GPUクラウド」を中核としたAIインフラ戦略を通じて、急速に進化するAI・ロボティクス分野の技術革新に貢献していくとしています。今後も最新のAI計算基盤の提供と、お客様のニーズに応じた柔軟なクラウド環境の構築により、日本のAI産業に不可欠な国産AI基盤として、社会と産業のAIイノベーション創出に貢献していく方針です。
「GMO GPUクラウド」とは
「GMO GPUクラウド」(https://gpucloud.gmo/)は、NVIDIAテクノロジ上で構築された国内最速クラスのGPUクラウドサービスです。2024年11月には高性能な「H200 GPU」を採用したサービスを開始しました。
今回導入されたNVIDIAの最新アーキテクチャ「Blackwell Ultra」を搭載した「NVIDIA B300」インスタンスは、以下の特長を持つ超大規模AIファクトリー構築向けのGPUです。
-
「NVFP4」に対応した第5世代Tensor Core:「NVFP4」はNVIDIAが設計した4ビット浮動小数点フォーマットで、高い精度を保ちながらもデータサイズを削減し、処理効率を向上させます。
-
2.3TBに達するHBM3eメモリ:「HBM3e」は高帯域メモリの最新規格で、従来のHBM3と比較して帯域幅が大幅に向上しており、大規模AIモデルの学習・推論処理を高速化します。
-
第5世代のNVIDIA NVLinkとNVLink Switchによる高速通信:GPU間のデータ転送速度が飛躍的に向上し、複数のGPUを連携させた大規模なAI学習環境でのボトルネックを解消します。
これらの技術により、従来のH200と比較して大規模言語モデルの学習時間を大幅に短縮し、AI開発の効率を大きく向上させることが期待されます。
GMOインターネットは、本サービスを通じて、生成AI分野に取り組む企業や研究機関に対し、最適化されたインフラ基盤と、お客様のワークロードに応じた柔軟でカスタマイズ可能な計算環境を提供することで、開発期間の短縮とコスト低減に貢献し、国内AI産業の発展を促進していきます。
まとめ
GMO GPUクラウドが国内最速クラスで提供を開始した「NVIDIA HGX B300」は、NVIDIA Blackwell Ultra GPUの革新的な性能とベアメタル構成のメリットを組み合わせることで、AI開発における新たな地平を切り開きます。大規模言語モデルの高速推論やエージェント型AI開発など、これからのAIワークロードに不可欠な高性能・高効率な計算環境を提供し、日本のAIイノベーションを力強く推進していくでしょう。
サービスに関するお問い合わせは、GMOインターネット株式会社 ドメイン・クラウド事業本部 GPUクラウド事業部までご連絡ください。
- お問い合わせ: https://gpucloud.gmo/form/

