AI開発の新たな一歩!Qlean Datasetが「日本庭園の画像データセット」を提供開始
近年、私たちの生活の中にAI(人工知能)がますます浸透し、その進化のスピードには目を見張るものがあります。AIが賢くなるためには、たくさんの「学習データ」が必要不可欠です。まるで人間が勉強するために教科書や参考書が必要なように、AIも画像や音声、テキストといったデータを使って学習し、さまざまなタンスクをこなせるようになります。
Visual Bank株式会社が提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、このAIの「学習」を支える重要な役割を担っています。そしてこの度、Qlean Datasetから、生成AIやマルチモーダル基盤モデルの開発・検証に特化した「日本庭園の画像データセット」の提供が開始されました。これは、AIが日本の美しい文化や景観を理解し、さらに新たな価値を生み出すための、まさに「教科書」となるデータセットです。

AI学習用データセットとは?なぜ重要なのか
AIは、与えられたデータの中からパターンや特徴を見つけ出し、それを基に予測や判断を行います。例えば、AIに「猫」の画像をたくさん見せれば、AIは「猫とは何か」を学習し、新しい猫の画像を見てもそれが猫であると認識できるようになります。この「猫の画像」こそが学習データです。
学習データの質や量は、AIの性能を大きく左右します。データが少なかったり、偏っていたりすると、AIは正確な判断ができません。例えば、猫の画像ばかり学習したAIは、犬を見ても猫だと間違えてしまうかもしれません。そのため、様々な種類の、正確で高品質な学習データをAIに与えることが、高性能なAIを開発する上で非常に重要なのです。
特に、最近注目されている「生成AI」は、テキストから画像を生成したり、音楽を作ったりと、まるで人間のようにクリエイティブな能力を発揮します。また、「マルチモーダル基盤モデル」は、画像とテキスト、音声など複数の種類のデータを同時に理解し、より複雑なタスクをこなすことができます。これらの最先端のAIを開発するためには、膨大で多様な、そして質の高い学習データが不可欠となります。
日本庭園の多様な美をAI学習に活用
今回提供が開始された「日本庭園の画像データセット」は、日本各地に存在する枯山水庭園や回遊式庭園を対象に撮影された画像で構成されています。枯山水庭園は水を使わずに石や砂で山水の風景を表現し、回遊式庭園は池の周りを歩きながら景色の変化を楽しむ形式です。
このデータセットには、以下のような日本庭園を構成する様々な要素が収録されています。
-
池: 水の広がりや反射、水面に映る景色など、自然の要素が豊富です。
-
石組: 庭園の骨格を成し、力強さや安定感を表現します。石の形、配置、種類などがAIの学習対象となります。
-
苔: 緑の絨毯のように地面を覆い、湿度や時間の経過を感じさせます。苔の種類や状態も重要な情報です。
-
砂紋: 枯山水庭園に描かれる砂の模様は、水の流れや波紋を象徴し、繊細な美しさを持っています。そのパターン認識はAIにとって興味深い課題です。
-
植栽: 松や楓、ツツジなど、四季折々の表情を見せる植物が庭園に彩りを与えます。植物の種類、配置、季節による変化などが学習データとなります。
これらの要素は、池や石組、植栽といった自然由来のものと、意図的に配置された灯籠や橋などの構造物が混在する日本の景観を特徴づけています。このような複雑で文化的な背景を持つ景観をAIが学習することで、景観デザインや空間デザインといった領域における生成系AIの開発において、より洗練されたアウトプットが期待できるでしょう。

さらに、このデータセットの大きな特徴は、画像に撮影地や被写体に関する「メタ情報」が付随している点です。メタ情報とは、画像そのものではなく、その画像に関する追加情報のことです。例えば、「この画像は京都の〇〇寺の庭園で、枯山水である」「写っているのは石灯籠と池と紅葉した木」といった具体的な説明がテキストで付加されています。
このメタ情報があることで、AIは画像単体での学習だけでなく、テキスト情報と画像を組み合わせて学習する「Vision-Language Model(VLM)」や「マルチモーダル基盤モデル」の大規模学習データの一部として活用できます。これにより、AIは単に画像の内容を認識するだけでなく、「この日本庭園はどのような場所で、どのような特徴があるのか」といった、より深い意味を理解できるようになるのです。特定のプロダクト用途に限らず、基盤モデル開発における景観カテゴリのデータ拡充に貢献します。

「日本庭園の画像データセット」が拓くAI活用の未来
このデータセットは、AI開発において様々な分野での活用が期待されています。具体的なユースケースをいくつか見てみましょう。
【研究用途】日本文化を対象とした画像理解モデルの評価
AIが日本文化特有の視覚的特徴をどの程度識別し、表現できるかを検証する研究に利用できます。
- 具体的な活用シナリオ: 例えば、AIに日本庭園の画像と、西洋庭園の画像を学習させ、それぞれの庭園の構造や景観要素(石の配置、水の表現、植物の種類など)を区別できるか、あるいはそれぞれの庭園の特徴をテキストで的確に説明できるかをテストします。これにより、AIが文化的な背景を持つ画像をどれだけ深く理解できるかを評価し、より高度な画像分類モデルや画像キャプション生成モデルの開発に役立てることが可能です。
【産業用途】観光・文化領域向け画像認識AIの検証
観光案内アプリや文化財関連サービスにおいて、日本庭園を含む景観画像を自動認識・分類する機能の開発や精度検証に利用できます。
- 具体的な活用シナリオ: 観光客がスマートフォンで日本庭園の写真を撮ると、その庭園の名前や歴史、見どころ、季節ごとの情報などをAIが自動で認識して案内してくれるアプリを開発できます。また、文化財のデジタルアーカイブシステムにおいて、膨大な庭園画像を効率的に分類・検索したり、損傷箇所の自動検出などにも応用できるでしょう。これにより、観光客の利便性向上や文化財の保護・活用に貢献します。
【その他実需要】マルチモーダル教材向けAIの試作
画像とテキストを組み合わせた教育用AIやデジタルアーカイブ向けシステムにおいて、日本庭園の画像を用いた説明生成や検索機能の検証に利用できます。
- 具体的な活用シナリオ: 子供たちが日本庭園について学ぶためのインタラクティブなデジタル教材を開発できます。庭園の画像を見せると、AIがその庭園の歴史や特徴をわかりやすい言葉で説明したり、クイズを出したりする機能が考えられます。また、研究者が日本庭園に関する情報を検索する際に、キーワードだけでなく、画像からも関連情報を効率的に探し出せるようなシステムを構築することも可能です。これにより、教育分野や学術研究の効率化が期待されます。
これらのユースケースは、いずれも日本文化の奥深さをAIが理解し、それを社会に役立てるための重要な一歩となるでしょう。
AI開発を強力に支援するQlean Datasetとは
Qlean Datasetは、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、AI学習用データソリューションです。AI開発の現場では、高品質な学習データを収集・整備することが大きな課題となることが少なくありません。Qlean Datasetは、この課題を解決し、研究用途から商用利用を見据えたAI開発までを強力に支援します。
このソリューションの大きな特徴は、画像・動画・音声・3D・テキストなど、多様な形式のデータに対応している点です。これにより、様々な種類のAIモデル開発ニーズに応えることができます。また、提供されるデータはすべて「権利クリア」であり、著作権や肖像権などの法的リスクを気にすることなく、安全に研究・商用利用できる環境が整備されています。これは、AI開発者が安心して開発に集中できる上で非常に重要な要素です。
Qlean Datasetは、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界に特化したり、最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。
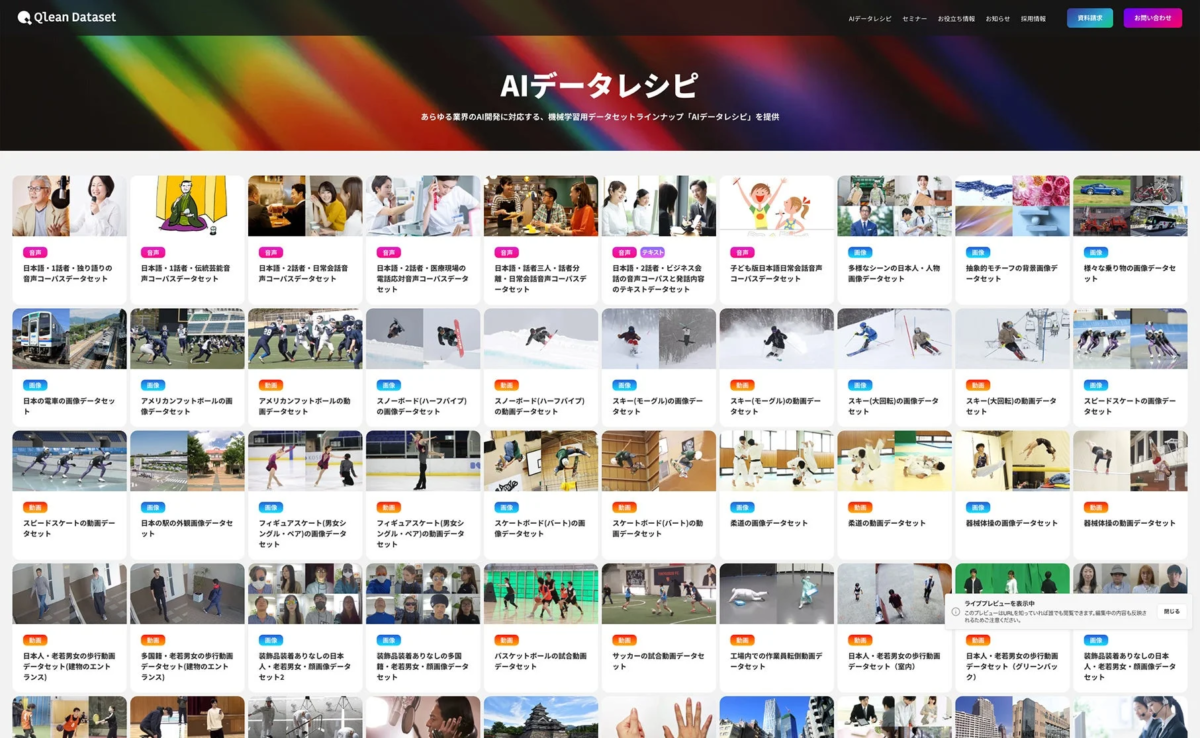
これにより、AI開発現場におけるデータ収集・整備の負荷を軽減し、法的リスクのないAI開発環境の構築を支援しています。
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
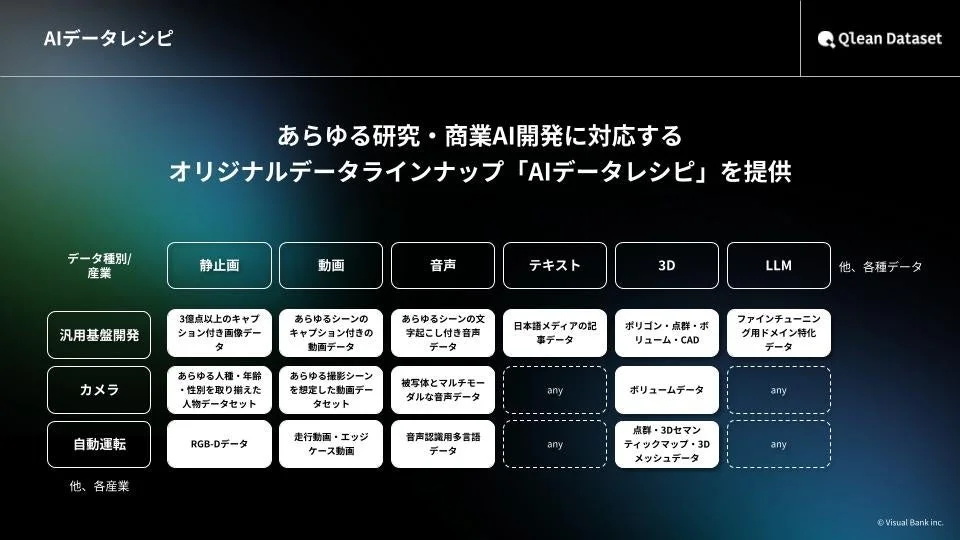
Qlean Dataset「AIデータレシピ」の3つの強み
Qlean Datasetが提供する「AIデータレシピ」には、AI開発をスムーズに進めるための大きな強みがあります。
1. すべての被写体から同意取得
AI学習用データにおいて、写っている人物や建物の所有者など、被写体からの同意取得は非常に重要です。同意がないデータを使用すると、後々著作権や肖像権などの法的問題に発展する可能性があります。Qlean Datasetでは、提供されるすべてのデータについて、被写体からの同意が適切に取得されており、利用者は安心して商用利用まで見据えたAI開発を進めることができます。
2. 既存データは最短1日で納品可能
AI開発はスピードが求められる場面が多く、必要なデータがすぐに手に入らないと開発が滞ってしまいます。Qlean Datasetでは、すでに用意されているデータセットであれば、最短1日で納品が可能です。これにより、開発者はデータ調達にかかる時間を大幅に短縮し、開発効率を向上させることができます。
3. カスタム撮影・収録・収集による独自データ構築にも対応
既存のデータセットでは対応できない、特定の要件やニッチな分野に特化したAIを開発したい場合もあります。Qlean Datasetは、そのようなニーズにも対応し、カスタムでの撮影・収録・収集を行い、独自のデータセットを構築することが可能です。これにより、他にはない、より専門性の高いAIの開発も実現できます。

これらの強みは、AI開発者が直面するデータに関する様々な課題を解決し、より効率的で信頼性の高いAI開発を可能にします。

Visual Bank株式会社とAI開発への貢献
Qlean Datasetを提供するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、漫画家の創作活動をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。
Visual Bankは、国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。これは、同社の技術力と社会貢献への意欲が高く評価されている証です。アマナイメージズは、長年にわたり高品質なビジュアルコンテンツを提供してきた実績があり、その知見がQlean Datasetのデータ品質にも活かされています。
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/
まとめ:日本文化とAIが織りなす新たな可能性
Qlean Datasetが提供を開始した「日本庭園の画像データセット」は、AI開発におけるデータ不足という大きな課題に対し、高品質で権利クリアなソリューションを提供します。枯山水や回遊式庭園といった日本独自の美しい景観をAIが深く学習することで、日本文化の理解を深めるAIモデルや、観光・文化領域における革新的なAIサービスの開発が加速することでしょう。
AI初心者の方も、このデータセットがどのようにAIの賢さを支え、私たちの未来を豊かにしていくのか、その可能性を感じていただけたのではないでしょうか。良質な学習データがAIの進化を牽引し、最終的には私たちの生活や社会に新たな価値をもたらします。日本庭園の画像データセットは、まさに日本文化とAI技術が融合し、新たな可能性を切り拓く象徴的な一歩と言えるでしょう。
AI開発にご興味のある方は、ぜひQlean Datasetの提供するデータセットやサービスについて詳細をご確認ください。