
AIの会話能力を飛躍させる!Qlean Datasetが「日本語・2話者・コメディテーマトーク音声コーパス」を提供開始
AI(人工知能)技術の進化は目覚ましく、私たちの日常生活やビジネスのあらゆる場面でその存在感が増しています。特に、人間と自然に会話する音声対話AIや、言葉の意味を理解する自然言語処理(NLP)技術は、スマートスピーカーやチャットボット、コールセンター業務の自動化など、多岐にわたる応用が期待されています。これらのAIがより賢く、より人間らしく振る舞うためには、高品質な「学習データ」が不可欠です。
そんな中、Visual Bank株式会社傘下の株式会社アマナイメージズが展開するAI学習用データソリューション『Qlean Dataset(キュリンデータセット)』が、AIの会話能力をさらに高めるための画期的なデータセット「日本語・2話者・コメディテーマトーク音声コーパスデータセット」の提供を開始しました。この新しいデータセットは、AIがより自然で人間らしい対話を学習するための強力なツールとなるでしょう。
AIの「耳」と「言葉の理解」を鍛える「音声コーパス」とは?
「音声コーパス」という言葉を初めて聞く方もいるかもしれません。これは、音声認識(ASR)や自然言語処理(NLP)といったAI技術を開発・学習させるために使用される、大量の音声データとそれに対応するテキスト情報(文字起こしなど)をまとめたものです。
人間が言葉を覚える際に、たくさんの人の話を聞き、その言葉の意味や使い方を学ぶように、AIも大量の音声データを学習することで、私たちの話す言葉を正確に聞き取り(音声認識)、その内容を理解し(自然言語処理)、適切な返答を生成する(音声対話AI)能力を身につけます。この学習の質を高めるためには、ただ音声を集めるだけでなく、どのような状況で、誰が、何を話しているかといった情報が豊富に含まれた、多様で高品質なデータが必要になります。
Qlean Datasetが提供する新しい「日本語・2話者・コメディテーマトーク音声コーパスデータセット」の全貌
今回Qlean Datasetが提供を開始した「日本語・2話者・コメディテーマトーク音声コーパスデータセット」は、『AIデータレシピ』という機械学習用データセットラインナップの一つとして登場しました。このデータセットの最大の特徴は、以下の点に集約されます。

1. リアルな日常会話を再現する「コメディテーマトーク」
このデータセットは、20代から50代の男女2名による自然な日本語の対話音声を収録しています。特筆すべきは、ユーモアや笑いを交えた軽快な掛け合いを中心とした雑談形式の会話である点です。台本を用いずに自由に進む会話には、即興的な反応、会話のテンポの変化、話題の脱線、そして「ボケ」と「ツッコミ」といった、人間らしい自然な対話要素が豊富に含まれています。
このような会話は、単なる情報伝達だけでなく、感情の表現や相手への配慮、場の空気感など、より複雑なコミュニケーションの側面を含んでいます。AIがこれらの要素を学習することで、より人間らしい、感情豊かな対話が可能になることが期待されます。
2. 多様なAIモデル学習に貢献する「2話者構成」と「豊富な収録時間」
データセットには、2話者構成による発話の交替や重なりも含まれています。これは、会話の中で誰がいつ話しているのかを識別する「話者識別」や、会話の区切りを認識する「ターンテイキング解析」、さらには会話全体の構造を理解するためのモデル学習や検証に非常に有用です。
総収録時間は約330時間にも及び、1音声あたり約5分から60分と、多様な長さの会話が収録されています。これだけ膨大な量の高品質なデータは、AIモデルが多岐にわたる会話パターンやニュアンスを深く学習するために不可欠です。
3. 実運用に近い環境での開発を可能に
本データセットの音声は、リラックスしたコミュニケーション環境下での会話を想定して収録されています。そのため、実際のサービスでAIを運用する際と同じような条件で、音声認識(ASR)や自然言語処理(NLP)を基盤技術とする対話型AIや音声アシスタントなどの研究・開発に活用できます。これにより、開発されたAIが実社会でよりスムーズに機能することが期待されます。
データセットの概要
| 概略 | ユーモアのある雑談などを中心に 2名が軽快に話し合う日本語対話音声データセットです。 |
|---|---|
| データ種別 | 音声 |
| 被写体属性 | 20代〜50代の男女 |
| データ形式 | mp3 / wav |
| 収録時間 | 計約330時間(1音声約5分〜60分) |
| 音声レート | 44.1kHz |
| 対象のシーン | ・2名が笑いやユーモアを交えながら軽い掛け合いを行うシーン ・即興的な反応やテンポの変化がそのまま反映される会話 ・台本のない自由な雑談形式で進む対話 ・ボケ・ツッコミ、話題の脱線などが自然に生じる場面 ・リラックスしたコミュニケーションが中心となる対話シーン |
| サンプル詳細 | https://qleandataset.visual-bank.co.jp/lineup/pn-020 |
このデータセットで何ができる?具体的な活用事例
この「日本語・2話者・コメディテーマトーク音声コーパスデータセット」は、AI開発の様々なフェーズでその真価を発揮します。具体的なユースケースを見ていきましょう。
研究用途:AIが会話の「構造」と「意味」を深く理解するために
-
対話構造解析モデルの研究
- 2話者間の発話交替や話題の移り変わりを対象に、会話の「ターン」を検出するターンテイキングや、対話の単位を分割する手法の検証に利用できます。これにより、AIがよりスムーズに会話の主導権を交代したり、適切なタイミングで応答したりする能力を向上させることが可能です。
-
雑談対話を対象とした自然言語処理研究
- 台本に依存しない自由な雑談対話を用いることで、特定の目的を持たない「非タスク指向対話」における話題の展開や、AIが自然な応答を生成する挙動を評価する研究に活用できます。AIがまるで人間のように雑談できる能力は、ユーザーエンゲージメントの向上に直結します。
産業用途:ビジネス現場で活躍するAIを開発するために
-
音声対話AIの応答生成・理解モデル開発
- 音声アシスタントや対話型サービスにおいて、自然な会話の流れを前提とした応答生成モデルや、ユーザーの発言意図を正確に理解するモデルの学習・評価に利用できます。例えば、コールセンターのAIオペレーターが、顧客の感情やニュアンスを汲み取った上で、より適切な対応をできるようになるでしょう。
-
話者識別・ターンテイキング技術の検証
- 2話者による会話音声を用いることで、話者の交替を検出する技術や、発話の区間を正確に推定する技術など、対話制御に関わる技術の検証に活用できます。これにより、複数の人が同時に話すような状況でも、AIが混乱せずに会話を継続できるようになります。
教育用途:次世代のAIエンジニアを育成するために
-
音声処理・対話AI教育用データ
- 大学や専門教育機関における音声認識や対話AIの演習用データとして、対話特有の処理課題を扱う教材に利用できます。学生が実際の人間らしい会話データに触れることで、理論だけでなく実践的なスキルを習得し、より高度なAI開発に挑戦できるようになるでしょう。
『Qlean Dataset(キュリンデータセット)』とは?AI開発のデータ課題を解決するソリューション
『Qlean Dataset』は、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。AI開発の現場では、高品質な学習データの収集と整備が大きな負担となることがあります。Qlean Datasetは、この課題を解決するために、多様な形式のデータを提供しています。
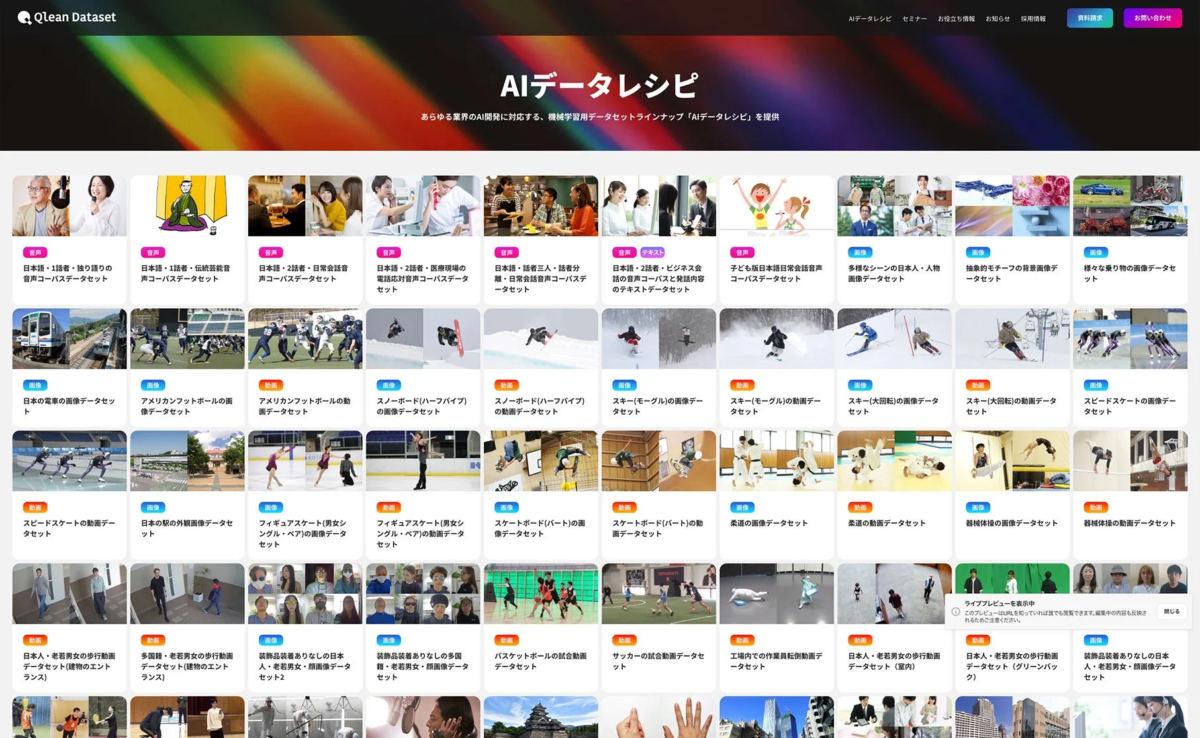
多様なデータ形式と安全な商用利用環境
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多岐にわたる形式のデータに対応しています。これらのデータは、研究用途はもちろん、ビジネスにおける商用利用においても安全に利用できるよう、厳格な権利処理が行われています。AI開発において、著作権や肖像権といった法的リスクは非常に重要であり、権利クリアなデータを提供することは、開発者が安心してAI開発に専念できる環境を構築する上で不可欠です。
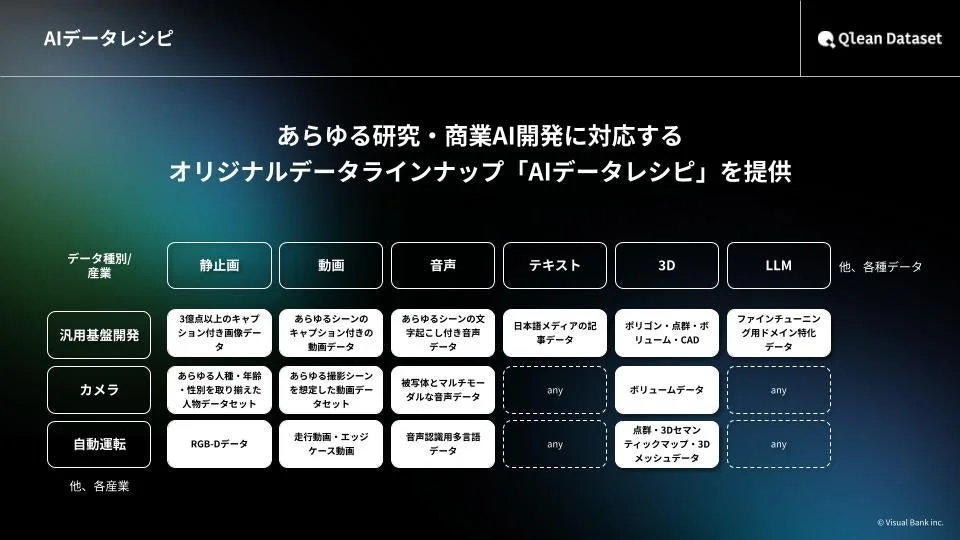
『AIデータレシピ』でデータラインナップを継続的に拡充
Qlean Datasetは、機械学習用データセットラインナップを『AIデータレシピ』として展開しています。株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータセットを継続的に拡充しており、AI開発の多様なニーズに応えています。

Qlean Datasetの強み
Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援するために、以下の強みを持っています。
-
すべての被写体から同意取得:個人情報保護や肖像権の問題をクリアにしています。
-
既存データは最短1日で納品可能:迅速なデータ調達により、開発期間の短縮に貢献します。
-
カスタム撮影・収録・収集による独自データ構築にも対応:特定の要件に合わせたオーダーメイドのデータセットも提供可能です。
-
権利処理済みで商用利用も安心:著作権や肖像権など、すべての権利がクリアされているため、安心して商用利用できます。
▶ Qlean Datasetサイト:https://qleandataset.visual-bank.co.jp/
▶ AIデータレシピ:https://qleandataset.visual-bank.co.jp/lineup

Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家の創作活動を支援するAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社として擁しています。
同社は、国の研究開発プログラム「GENIAC」にも採択されており、その技術力と社会実装に向けた取り組みは高く評価されています。このような背景を持つVisual Bankが提供するQlean Datasetは、AI開発の未来を支える重要な役割を担っています。
-
代表取締役CEO:永井 真之
-
所在地:〒107-0062 東京都港区南青山7-1-7 C-Cube南青山ビル6F
-
Visual Bank企業URL:https://visual-bank.co.jp/
-
アマナイメージズ企業URL:https://amanaimages.com/about/
まとめ:より人間らしいAIとの対話へ
Qlean Datasetが提供を開始した「日本語・2話者・コメディテーマトーク音声コーパスデータセット」は、AIが人間らしい、自然で感情豊かな会話を学習するための画期的な一歩です。
AI初心者の方にとっては、AIがどのように言葉を学び、私たちと対話するようになるのか、その裏側にある学習データの重要性を理解する良い機会になったのではないでしょうか。このデータセットを活用することで、音声認識の精度向上はもちろんのこと、AIが会話の意図や感情をより深く理解し、ユーモアを交えた応答を生成するといった、まるで人間と話しているかのような体験が実現する日も近いかもしれません。
AI技術が社会に深く浸透していく中で、このような高品質な学習データは、AIの発展を加速させ、私たちの生活をより豊かにする新たなサービスやアプリケーションの創出に貢献していくことでしょう。Qlean Datasetの今後のデータラインナップの拡充にも注目が集まります。

