企業法務におけるAI活用の最前線と新たな評価基準の必要性
近年、人工知能(AI)技術、特に大規模言語モデル(LLM)は、ビジネスのあらゆる分野で注目を集めています。その進化は目覚ましく、企業活動においても業務効率化や生産性向上への貢献が期待されています。中でも、専門性が高く複雑な業務を多く含む企業法務分野では、AIの活用が大きな可能性を秘めているとされています。
しかし、企業法務においてAIを導入する際、重要な課題が浮上していました。それは、「AIがどれだけ弁護士のように正確で、実務で通用する品質の回答を出せるのか」という評価基準が曖昧であるという点です。一般的な文章生成や情報検索とは異なり、法務業務は厳密な法的知識と実務経験が求められるため、AIの回答の正確性や実用性を客観的に評価する仕組みが不可欠でした。
この課題を解決するため、株式会社LegalOn Technologies(以下、LegalOn Technologies)は、日本の企業法務に特化した大規模言語モデル(LLM)の性能を評価するためのベンチマークデータセット「LegalRikai: Open Benchmark」を公開しました。このデータセットは、法務AIの評価基準に透明性をもたらし、その研究と開発を加速させることを目指しています。
「LegalRikai: Open Benchmark」とは?日本の法務AIを測る新たな物差し
「LegalRikai: Open Benchmark」は、日本の法規制に基づき、大規模言語モデル(LLM)が法的タスクを適切に解決・処理できるかを評価するためのベンチマークデータセット「LegalRikai」の一部を、よりオープンな形で公開したものです。

LegalOn Technologiesは、2025年3月11日に弁護士による評価基準を取り入れたベンチマークデータセット「LegalRikai」を開発・発表しました。そして今回、法務AIの分野における透明性の向上と研究の加速を目的として、「LegalRikai」の一部のタスクについて、そのデータセットの設計、評価基準、および実験の設定を「LegalRikai: Open Benchmark」として公開しました。これにより、AI開発企業や研究機関、そして法務AIのベンダーは、自社のLLMの性能を公正に比較・検証し、より実践的で高品質なモデルを効率的に開発できる環境が整えられます。
法務実務の複雑なタスクを網羅!4つの評価項目を徹底解説
「LegalRikai: Open Benchmark」では、LLMによる法的タスクにおいて、特に実務で重要となる以下の4つの項目を誰でも検証することが可能です。これらのタスクは、LLMの単なる知識量だけでなく、「実務適合性」を多角的に評価できるよう設計されています。
① 法改正の説明能力
法律は常に改正されるため、企業法務担当者には最新の法改正を正確に理解し、その内容を社内の関係者に分かりやすく伝える能力が求められます。このタスクでは、LLMが法改正の趣旨とそれが実務に与える影響を正確に把握し、社内向けに適切に要約できるかを検証します。例えば、「〇〇法の改正ポイントとそのビジネスへの影響を、非法務部門の社員にも理解できるように説明してください」といった指示に対し、LLMがどの程度適切に情報を提供できるかを確認します。
② 法令に準拠した契約書修正
法改正が行われた場合、それに合わせて既存の契約書を修正する必要があります。古い法令に対応した契約書を、現行の法令に準拠した契約書へと正確に修正できるかどうかが、このタスクの評価ポイントです。例えば、「民法改正に伴い、この請負契約書の〇条を改正民法に適合するように修正してください」といった具体的な指示に対し、LLMが法的整合性を保ちつつ、必要な修正を加えられるかを見極めます。
③ 契約書へ要望を反映
契約書の作成・レビュープロセスでは、取引先や社内関係者から様々な要望や意見が寄せられます。このタスクでは、LLMが関係者からの意見や要望を忠実に契約書に反映する能力を検証します。例えば、「取引先から受け取ったこの修正案を、契約書の該当箇所に適切に反映し、かつ法的リスクが生じないように調整してください」といった複雑な指示に対して、LLMが意図を正確に汲み取り、契約書の内容を調整できるかが評価されます。
④ 契約書に潜むリスク検出および修正文生成
契約書には、将来的に企業に不利な状況をもたらす潜在的なリスクが潜んでいることがあります。このタスクでは、LLMが契約書に隠れたリスクを検出し、そのリスクを低減するための具体的な修正文案を提案できるかを検証します。例えば、「この秘密保持契約書の中に、自社にとって不利になりうる条項があれば指摘し、そのリスクを回避するための修正案を複数提示してください」といった高度な分析と提案能力が求められます。
これらの多角的な検証を通じて、AI開発企業や研究機関は、自社のLLMが法務実務においてどの程度の「実用性」を持つのかを客観的に評価し、改善点を見出すことが可能になります。
主要LLMの実力は?GPT-5、Gemini-2.5-pro、Claude Opus 4.1の分析結果
LegalOn Technologiesは、「LegalRikai: Open Benchmark」を用いて、現在主要な大規模言語モデルとされるGPT-5、Gemini-2.5-pro、Claude Opus 4.1の性能を分析しました。この分析により、各モデルの得意分野や特徴が明らかになりました。特に複雑性の高いタスクである「現行法令に準拠した契約書を出力するタスク」の検証結果は注目に値します。
このタスクは、単に情報を参照するだけでなく、以下に示す複数の複雑なステップを要します。
- 改正前の法令の把握
- 改正前後の差分の把握
- 契約書へ影響する改正箇所の特定
- 既存契約書の構造と内容の理解
- 編集が必要な条項の特定と修正
LegalOn Technologiesの法務部門による人手評価の結果、各LLMの特性が明確に示されました。
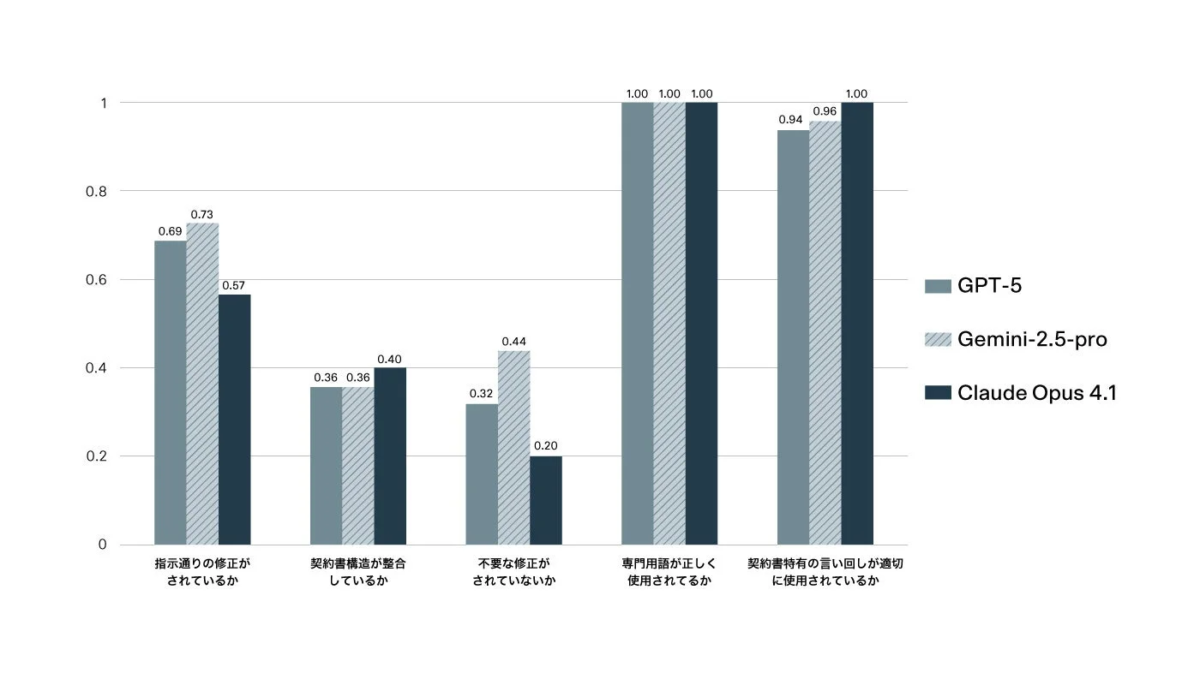
Gemini-2.5-proの評価
Gemini-2.5-proは、「指示通りの修正が行われているか」で0.73、「不要な修正がされていないか」で0.44と、他のモデルよりも高いスコアを記録しました。この結果は、Gemini-2.5-proが、与えられた指示を網羅的に理解し、正確にタスクを遂行する能力に優れていることを示唆しています。つまり、必要な修正を漏れなく行い、かつ余計な変更を加えないという点で高いパフォーマンスを発揮したと言えます。
Claude Opus 4.1の評価
Claude Opus 4.1は、「契約書構造が整合しているか」で0.40、「契約書特有の言い回しが適切に使用されているか」において1.0と最高スコアを記録しました。これは、Claude Opus 4.1が契約書としての体裁や専門的な言い回しを維持する能力に長けていることを示しています。しかし、「不要な修正がされていないか」のスコアは0.20と最も低く、指示にない余分な変更を行う傾向があることが明らかになりました。これは、創造性や柔軟性が高い一方で、厳密な指示遵守には課題がある可能性を示しています。
GPT-5の評価
GPT-5は、Gemini-2.5-proとClaude Opus 4.1の両者の中間的な性能結果となりました。特定の項目で突出したスコアは見られませんでしたが、全体的にバランスの取れた性能を発揮したと言えるでしょう。
共通して見られた点
興味深いことに、全モデルが「専門用語が正しく使用されているか」において最高スコアの1.0を記録しました。これは、主要なLLMが法務分野の専門用語を正確に理解し、適切に使用する能力においては、すでに高い水準に達していることを示しています。
これらの分析結果は、法務実務においてLLMを選定する際には、単一の総合スコアだけで判断するのではなく、タスクの性質(例えば、厳密な正確性が求められるか、体裁の維持が重要かなど)と、各モデルの得意な側面を考慮する必要があることを強く示唆しています。他の3つのタスクの検証結果については、以下の論文で詳細を確認できます。
法務AIの未来を切り拓く「LegalRikai: Open Benchmark」の貢献
「LegalRikai: Open Benchmark」の公開は、日本の法務AI分野に大きな一歩をもたらします。これまで明確な評価基準がなかった法務AIの性能に対し、客観的で実践的な評価の枠組みが提供されることで、以下のような貢献が期待されます。
-
公正な比較・検証の促進: AI開発企業や研究機関は、この公開されたデータと基準を用いて、自社のLLMの性能を他と比較し、公正に検証できるようになります。これにより、より良いモデルを開発するための競争が促進されます。
-
実践的で高品質なモデル開発の効率化: 法務AIベンダーは、「LegalRikai: Open Benchmark」を利用することで、実際の法務業務に即した、より実践的で高品質なモデルを効率的に開発できる環境を構築できます。これにより、開発期間の短縮やコスト削減にもつながるでしょう。
-
法務AIにおける透明性の向上と研究の加速: 評価基準が明確になることで、法務AIの性能や限界がより透明化されます。これは、AI技術の信頼性向上に繋がり、学術界や産業界における法務AIの研究をさらに加速させる原動力となります。
LegalOn Technologiesは、「LegalRikai: Open Benchmark」の継続的な改善と検証を通じて、法務AIの進化をリードし、企業がより安全で、より効果的なAIを法務業務に実装できるよう貢献していくと表明しています。
LegalOn Technologiesの展望と「LegalOn: World Leading Legal AI」
LegalOn Technologiesは、AI分野における高度な技術力と法律・契約の専門知識を兼ね備えたグローバルリーガルAIカンパニーです。同社は、2017年の設立当初からAIを活用したリーガルAIサービスの開発に注力し、現在は「LegalOn: World Leading Legal AI」を展開しています。
「LegalOn: World Leading Legal AI」は、国境を越えて非効率な法務業務を一掃し、お客様の法務チームが思考と決断にフォーカスし、全社の成長を牽引することを可能にするサービスです。LegalOn Technologiesの法務コンテンツとAI(エージェント)は、お客様の競争力強化と成長に貢献し、より優れた法務プロセスを通じて、お客様のビジネスを迅速に進めることを目指しています。
このサービスには、法務相談やリーガルリサーチ、論点整理、契約書レビュー、契約書作成など、高度かつ複雑な法務業務に対応するAIエージェント「LegalOn Agents」が搭載されています。「LegalOn Agents」は、弁護士監修コンテンツや外部情報とも連携しながら自律的に各法務業務を処理し、法務チームを強力にバックアップします。さらに、「LegalOn」を活用するだけで、自然とナレッジが蓄積され、AIエージェントによる業務遂行に反映される仕組みも実現しています。
LegalOn Technologiesは、法務チームのために開発された「世界水準の法務AI」として、お客様の法務チームを強力にバックアップし続けています。
まとめ
LegalOn Technologiesが公開した「LegalRikai: Open Benchmark」は、日本の企業法務における大規模言語モデル(LLM)の性能を客観的に評価するための画期的なツールです。法改正の説明、契約書修正、要望反映、リスク検出といった4つの実務的なタスクを通じて、LLMの「実務適合性」を多角的に検証できるこのデータセットは、法務AIの透明性を高め、その研究開発を加速させる重要な役割を担います。
主要LLMの分析結果からは、各モデルの得意分野や弱点が明らかになり、LLM選定においてはタスクの性質とモデルの特性を考慮することの重要性が示されました。これにより、企業は自社のニーズに最も合った法務AIを、より賢く選択できるようになるでしょう。
「LegalRikai: Open Benchmark」は、法務AIの進化を促し、企業がより安全で効果的なAIを導入するための基盤を築くものです。この取り組みを通じて、日本の企業法務はさらなる効率化と高度化を遂げ、ビジネス全体の成長を牽引していくことが期待されます。AI初心者の方も、この「物差し」が法務の世界をどのように変えていくのか、ぜひ注目してみてください。