
FuriosaAIがNeurIPS 2025で「持続可能なAI」を推進するRNGD NPUを披露
2025年12月2日から7日にかけて、米国カリフォルニア州サンディエゴで開催された「NeurIPS(Neural Information Processing Systems Conference)2025」は、神経ネットワークと人工知能分野における世界最大規模の学術会議です。1987年に神経ネットワーク研究を目的として始まったこの会議は、現在ではGoogle Scholarのコンピュータサイエンス/AI分野でNatureやScienceといった最高峰の科学誌と同等の影響力を持つと評価されています。
今年のNeurIPSには、合計2万1,575本の論文が投稿され、そのうち24.52%にあたる5,290本が採択されました。過去には、データマイニングと機械学習の起点とされるAlexNet、自然言語処理に革命をもたらしたWord2Vec、そして大規模言語モデル(LLM)の中核技術であるTransformerモデルなど、画期的な研究がNeurIPSで発表されてきました。
今年の主要キーワードは、OpenAIのo1モデルに代表される段階的思考を行う推論(Reasoning)能力、クラウド接続なしでスマートフォンやノートPC上で動作するオンデバイスAI、そしてAI倫理に関わる安全性およびアライメントでした。このような最先端の議論が交わされる中、AI半導体技術企業のFuriosaAIが「シルバー・パビリオン」として参加し、その革新的な技術を披露しました。
AI半導体の電力効率が直面する課題
FuriosaAIの最高研究責任者(CRO)であるカン・ジフン氏は、NeurIPS 2025で「シリコンからモデルまでのAI効率最適化(Optimizing AI Efficiency from Silicon to Model)」をテーマにスポットライト発表を行いました。

カンCROは、データセンターが処理できるデータ量は電力消費量と密接に関連していると指摘しました。ハイパースケーラーやAIデータセンター運営企業が発電所への投資を検討するのも、最終的にはデータセンターの処理能力を拡大するためです。この状況から、「同じ電力消費でより多くの処理を行えるようにすること」がAI業界全体の喫緊の課題であることが浮き彫りになります。
さらに、半導体の設計方法にも言及がありました。ハードワイヤード(半導体設計時に回路が物理配線として固定され、後から変更できない方式)で半導体を設計すると、製造コストが高くなり、開発期間も長くなる傾向があります。そのため、性能最適化の観点から、データバッチを並列処理するGPU(Graphics Processing Unit)を使うのか、あるいは大規模な行列演算(シストリックアレイ)に特化した専用半導体を使うのか、という選択が求められてきました。
GPUの特性と課題
GPUは、複数のメモリ階層構造を持ち、柔軟なデータフローを提供することが特徴です。グローバルメモリからローカルメモリへの移動など、多様な処理に適している点が強みとされています。これにより、高帯域幅メモリ(HBM)から内部メモリ(SRAM)へのデータ移動が自由に行えます。この柔軟性は、特にAIモデルの学習(トレーニング)において有利に働きます。複雑なモデルの学習には、大量のデータを柔軟に扱い、多岐にわたる演算を効率的に処理する能力が不可欠だからです。
しかし、この自由なデータ移動や柔軟性には、追加の実行時間と消費電力が必要となるという側面もあります。そのため、AIモデルの推論(学習済みのモデルを使って予測や判断を行うプロセス)用途では、投入コストに対して効率が相対的に低いという課題を抱えています。
シストリックアレイ方式の特性と課題
一方、シストリックアレイ方式は、Google TPU(Tensor Processing Unit)やAWS Trainiumのように、特定用途向けに設計された専用半導体を指します。最近では、Googleの生成AIモデルであるGemini 3.0 ProがTPUで学習されたことで、再び注目を集めています。この方式の最大の特徴は、データフローが固定されている点です。
データフローが固定されているため、個々の演算効率は非常に高いですが、行列積など特定の演算に用途が限定されるという制約があります。これにより、汎用性には欠けるものの、特定のタスクにおいては高いパフォーマンスを発揮します。また、企業の特定の用途に合わせて設計されることが多いため、特定企業で大規模に採用されるケースが多い傾向にあります。
FuriosaAIのRNGD NPU:GPUとシストリックアレイの「良いとこどり」
FuriosaAIが開発したRNGD(Reconfigurable No-Gene Dataflow)は、テンソル縮約プロセッサ(TCP:Tensor Contraction Processor)を通じて、GPUとシストリックアレイの中間に位置するバランスの取れたソリューションを提供します。カンCROは、TCPではSRAMが複数のスライスに分割され、それぞれのスライスからデータが抽出される形でルーティングされると説明しました。データパケットはそのまま転送されることもあれば、複数のスライスに分配されることもあります。
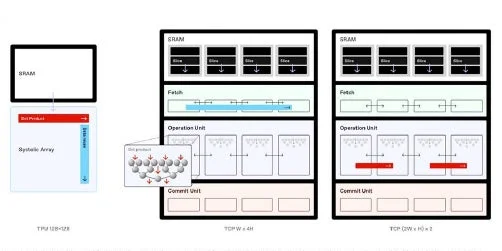
より分かりやすく言えば、シストリックアレイが一方向の固定されたデータフローを前提とするのに対し、RNGDはデータフローの方向を柔軟に構成できるという大きな違いがあります。SRAMを複数スライス単位で管理し、データを順次送るだけでなく、2枚から最大8枚まで同時に分配することが可能です。これにより、従来のシストリックアレイが固定サイズの行列しか処理できなかったのに対し、RNGDは任意サイズの行列演算を分割処理することで、ハードウェア資源を最大限に活用できます。
このRNGDのデータフローの柔軟性は、処理効率の向上だけでなく、ソフトウェア管理の面でも大きなメリットをもたらします。PyTorchのような高水準かつ集約的な演算をアーキテクチャに直接マッピングできるため、開発者は成果を確認しやすくなります。結果としてFuriosaAIは、LLMサービスを含む独自構築のソフトウェアスタックを提供しています。
このソフトウェアスタックは、LLMエンジン、LLMサービング、モデル並列化、コンパイラとランタイム、モデルコンプレッサー、プロファイラー、クラウドネイティブツールキット、NPUオペレーター、デバイスプラグイン、フィーチャーディスカバリー、メトリックエクスポーター、インフラ管理ツール、デバイスドライバーなど、多岐にわたるコンポーネントで構成されており、AI開発者がRNGD NPUの性能を最大限に引き出せるよう設計されています。
RNGD NPUが実現する「持続可能なAI」
TCPの技術的説明に続き、カンCROは来年1月から2万枚規模のRNGDチップを量産する計画を明らかにしました。そして、その電力効率についても具体的な数値を示しました。
現在、データセンターで使用されるラックは、平均18kWを超えることが難しいとされており、特に空冷方式ではほぼ上限に達しています。しかし、RNGDは15kWラックを基準とした場合、NVIDIA H100システムと比較して、3.5倍も多くのトークンを生成できるとされています。
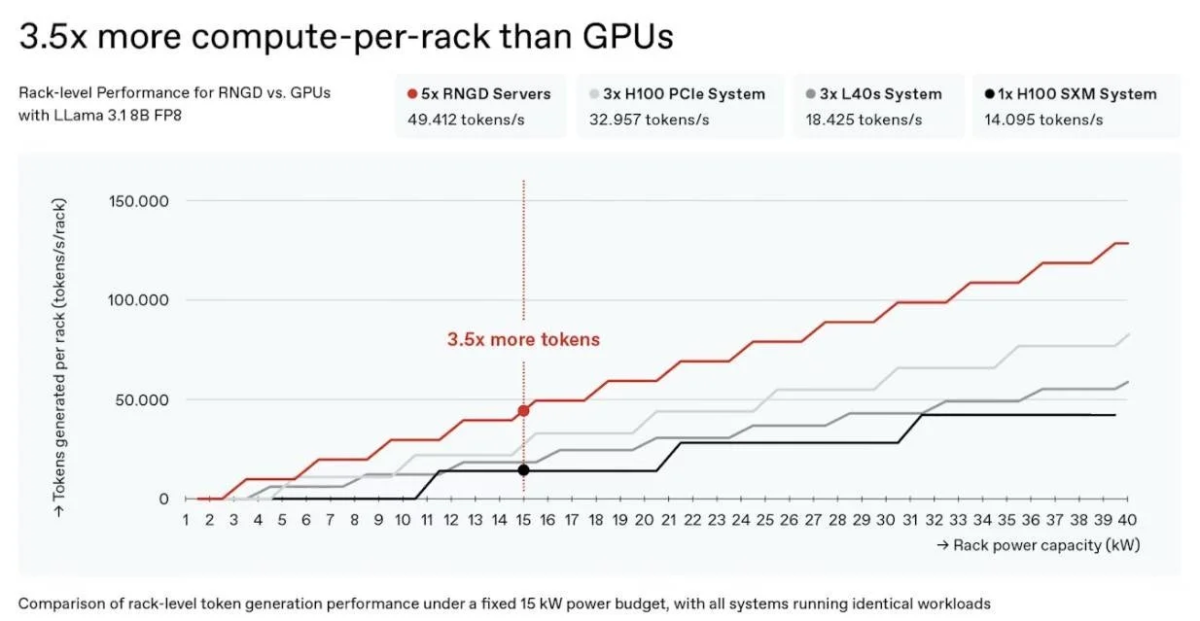
このデータは、RNGDがいかに優れた電力効率を持っているかを示しています。電力効率を高めることは、データセンターの電力密度をさらに引き上げ、限られた電力資源でより多くのAI処理を可能にすることを意味します。次世代製品では、現在の180WのTDP(Thermal Design Power:熱設計電力)を超える400W級となる見込みであり、さらなる性能向上が期待されます。
また、RNGDはクラウド環境での効率的な管理と配備を想定しており、Kubernetesをサポートしています。Kubernetesはコンテナ化されたアプリケーションのデプロイ、スケーリング、管理を自動化するためのオープンソースシステムであり、これによりRNGDは大規模なAIインフラストラクチャに容易に統合できます。さらに、低レベルアクセスAPIを提供することで、専門開発者が独自に最適化されたコンパイラやシステムを構築できる柔軟性も備えています。
これらの特徴は、RNGDが単に高性能なだけでなく、運用面でも「持続可能なAI」を実現するための重要な要素であることを示唆しています。
AI業界の新たな潮流「持続可能なAI演算」
NeurIPSがAI業界最大の学術イベントとして位置づけられる中、AI倫理に関する責任ある議論も活発に行われています。その代表的な例として、「機械学習による気候変動への対応」をテーマとしたワークショップでは、従来の機械学習を用いて気候問題の解決策を探るだけでなく、AIモデルを構築する過程における気候的利益とコストを議論し、より効果的なAIアプローチを導き出す試みが行われました。
関連論文には、エネルギーや気候予測に関する研究が多い一方で、データセンターの持続可能性向上や炭素排出量削減を目的としたワークロード分散、大規模な炭素削減を見据えたLLMアプローチなど、従来のAI構築手法そのものを見直す研究も数多く発表されました。これらの議論の結論は、「AI構築に必要な電力消費をいかに効率化するか」に集約されており、その中核にAI半導体の効率向上が位置づけられています。
FuriosaAIのようなNPU(Neural Processing Unit)企業がNeurIPSに参加する理由も、まさにこうした解決策を提示するためです。来年1月からはRNGDの本格量産が始まり、韓国のみならず世界各国のAIデータセンターに導入されることで、炭素排出削減とAI推論効率の向上の両立に寄与する見通しです。「持続可能なAI演算」というテーマへの関心が高まるほど、RNGDのような高効率AI半導体への注目度も一段と高まることでしょう。
まとめ
FuriosaAIがNeurIPS 2025で発表したRNGD NPUは、AI時代の電力効率と性能の最適化という、業界が直面する大きな課題に対する革新的な解決策を提供します。GPUの柔軟性とシストリックアレイの効率性を両立させるTCPアーキテクチャ、そして優れた電力効率は、AIデータセンターの運用を劇的に改善し、持続可能なAIの実現に大きく貢献することが期待されます。
2025年1月からのRNGDチップの量産開始は、AI技術の発展と環境負荷低減の両面において、世界中のAIインフラに大きな影響を与えることでしょう。今後、RNGDのような高効率AI半導体が、どのようにAIの未来を形作っていくのか、その動向に注目が集まります。

