医療現場の課題解決へ!Qlean Datasetが「日本語・2話者・医療現場の電話応対音声コーパスデータセット」を提供開始
近年、AI(人工知能)技術は私たちの生活のあらゆる場面で活用され始めています。特に医療現場では、人手不足の解消や業務効率化、診断精度の向上といった大きな期待が寄せられており、AIの導入が急務とされています。しかし、医療AIを開発するためには、膨大な量の「質が高いデータ」が不可欠です。
このたび、Visual Bank株式会社(以下、Visual Bank)傘下の株式会社アマナイメージズが展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」が、医療AI開発を強力に後押しする新たなデータセットを発表しました。それが「日本語・2話者・医療現場の電話応対音声コーパスデータセット」です。
この新しいデータセットは、実際の医療現場で交わされる電話応対の音声を忠実に再現しており、音声認識(ASR)や自然言語処理(NLP)、さらには高度な生成AI(Generative AI)といった医療分野のAI技術を、より高精度に進化させるための基盤データとして期待されています。
Qlean Datasetとは?AI開発を支える「データのプロ」
AIを開発するためには、コンピューターに「学習」させるためのデータが必要です。例えば、犬と猫を区別するAIを作るには、たくさんの犬と猫の画像を見せて「これは犬」「これは猫」と教える必要があります。この学習に使うデータのことを「学習用データ」と呼びます。
Qlean Datasetは、このAI学習用データを専門に提供するソリューションです。画像、動画、音声、3Dデータ、テキストなど、さまざまな形式のデータを豊富に取り揃えており、企業や研究機関が安全に、そして安心してAI開発を進められるようサポートしています。特に、データを使う上で重要な「権利処理」を適切に行っているため、法的なリスクを心配することなく利用できるのが大きな特長です。
AI開発において、学習データの収集や整備は非常に手間と時間がかかる作業です。Qlean Datasetは、この負担を軽減し、開発者がAIの核心部分に集中できる環境を提供することで、AI技術の社会実装を加速させています。
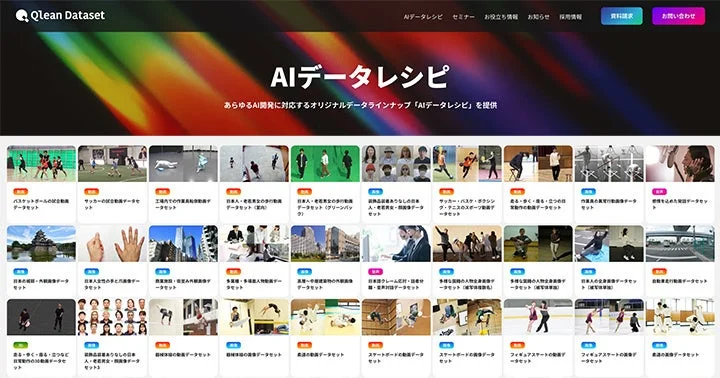
新データセットの全貌:「日本語・2話者・医療現場の電話応対音声コーパスデータセット」
今回提供が開始された「日本語・2話者・医療現場の電話応対音声コーパスデータセット」は、その名の通り、日本の医療現場における電話でのやり取りを再現した音声データです。具体的には、受付担当者と患者さんとの会話や、看護師同士の引き継ぎ(申し送り)の連絡など、多岐にわたるシーンを想定して収録されています。
なぜこのデータセットが重要なのか?
AIが実際の現場で役立つためには、学習データが「現実世界に近い」ものであることが非常に重要です。このデータセットは、単に会話を収録しただけでなく、以下のような特長を持っています。
-
自然なイントネーションと間合いの再現: 実際の会話では、声の抑揚や話すスピード、沈黙の間などが相手に与える印象や意味合いに大きく影響します。このデータセットは、そうした自然な会話のニュアンスを忠実に再現しているため、より人間らしい対話が可能なAIの開発に役立ちます。
-
実環境の言葉遣いを反映: 医療現場特有の専門用語や言い回し、患者さんの切実な声、看護師の迅速な情報共有など、現場で実際に使われる言葉の特徴が反映されています。これにより、開発されるAIは、より現実に即した状況で正確な判断や応答ができるようになります。
-
多様なシーンを網羅: 患者さんからの体調相談、症状確認、あるいは医療従事者間の業務連絡など、さまざまなシチュエーションが収録されています。これにより、幅広い医療業務に対応できるAIの開発が期待できます。
データセットの概要
| 項目 | 詳細 |
|---|---|
| 被写体属性 | 20代〜30代の男女(男性1名、女性5名)、受付担当、看護師、患者の役割 |
| データ形式 | wav形式 |
| 収録時間 | 1音声あたり約5分 |
| 対象シーン | 患者からの体調相談への電話応対、看護師間の患者状態に関する申し送り電話連絡 |
このデータセットは、音声認識(ASR)システム、医療対話理解モデル、さらには音声入力を含む生成AI基盤(例えば、人間のように自然な会話ができるAIや、複数の情報を組み合わせて処理するマルチモーダルAIなど)の学習や検証データとして、幅広く活用することができます。
このデータセットで実現できること:具体的なユースケース
この新しいデータセットは、多岐にわたる医療AIの開発や既存AIの精度向上に貢献します。AI初心者の方にも分かりやすいように、具体的な活用例をいくつかご紹介します。
1. 医療AI・音声モデル開発
-
音声認識(ASR)や自然言語処理(NLP)モデルの学習データ
-
ASR(Automatic Speech Recognition)とは、人の話す声を文字に変換する技術です。このデータセットを使えば、医療現場特有の専門用語や発音を正確に聞き取り、文字に起こす高精度なASRの開発が進みます。例えば、医師が口頭で話した診察内容を自動的にカルテに記録するシステムなどが考えられます。
-
NLP(Natural Language Processing)とは、人間が使う言葉(自然言語)をコンピューターが理解・処理する技術です。医療現場の会話を理解し、患者さんの症状や要望を正確に把握するAIの開発に役立ちます。これにより、医療従答者が患者さんの話をより深く理解し、適切な対応を迅速に行えるようになります。
-
-
感情認識・ストレス検知AIの開発
- 会話の中には、言葉だけでなく、声のトーンや速さ、間合いから伝わる感情があります。このデータセットは、そうした発話速度やイントネーションの変化を解析することで、患者さんの不安やストレスレベル、あるいは医療従事者の疲労度などを推定するAIの開発にも活用できます。これにより、患者さんに寄り添ったきめ細やかな医療サービスの提供や、医療従事者のメンタルヘルスサポートにも繋がるでしょう。
2. 実環境検証・最適化
-
遠隔通話環境下でのロバスト性(頑健性)評価
- VoIP(Voice over Internet Protocol)とは、インターネット回線を通じて音声通話を行う技術で、電話会議などで広く使われています。このデータセットは、VoIP環境特有の音質の変化やノイズを再現したデータも含まれるため、実際のインターネット通話環境下でも問題なく機能するAI(例えば、オンライン診療での音声認識システムなど)の性能を評価し、最適化するために役立ちます。
-
会話要約・自動記録生成AIの評価
- 問診や電話応対の内容を、重要なポイントに絞って要約したり、自動で記録を作成したりするAIの開発にも利用できます。例えば、患者さんとの長い会話の中から、症状や治療方針といった重要な情報を自動で抽出し、簡潔なレポートを作成するシステムなどが考えられます。これにより、医療従事者の書類作成業務の負担を大幅に軽減し、より患者さんとの対話に時間を割けるようになるでしょう。
3. 教育・倫理・安全性分野
-
医療接遇・教育トレーニングAIの教材
- 医療現場では、患者さんとのコミュニケーション能力が非常に重要です。このデータセットは、医療従事者向けのコミュニケーション研修や、AIによる発話評価、自動フィードバックを提供するトレーニングAIの構築にも応用できます。これにより、新人医療従事者の教育や、既存スタッフのスキルアップを効率的に支援することが可能になります。
-
匿名化・話者変換AIの研究
- 医療データは、非常に機密性の高い個人情報を含んでいます。このデータセットは、音声データに含まれる個人情報を特定できないように匿名化したり、話者の声を別の声に変換したりするプライバシー保護技術の研究・検証にも利用できます。これにより、医療データの安全な活用とプライバシー保護の両立を目指すAI技術の発展に貢献するでしょう。
Qlean Datasetの強み:安心と高品質のデータ提供
Qlean Datasetが提供するデータセットは、単にデータ量が多いだけでなく、その品質と信頼性において多くの強みを持っています。


-
すべての被写体から同意取得・国際法規(GDPR/CCPA)準拠
- AI学習用データにおいて最も重要なのが、データの利用に関する「権利」です。Qlean Datasetのデータは、すべての被写体(写っている人や声の主など)から正式な同意を得て収録されており、世界的な個人情報保護のルールであるGDPR(一般データ保護規則)やCCPA(カリフォルニア州消費者プライバシー法)にも準拠しています。これにより、利用者は法的なリスクを心配することなく、安心してデータを活用できます。
-
既存データは最短1日で納品可能
- AI開発はスピードが求められる分野です。Qlean Datasetでは、すでに用意されているデータセットであれば、最短1日で納品が可能。これにより、開発期間を大幅に短縮し、迅速なAIモデルの構築を支援します。
-
カスタム撮影・収録・収集による独自データ構築にも対応
- 特定のAIを開発するためには、既存のデータだけでは不十分な場合があります。Qlean Datasetは、顧客のニーズに合わせて、新たなデータ(画像、音声、動画など)を撮影、収録、収集し、独自のデータセットを構築するサービスも提供しています。これにより、他にはない、より専門性の高いAIの開発も可能になります。
-
データパートナーとの協業による「AIデータレシピ」の拡充
- 千葉ロッテマリーンズや東洋経済新報社といった多様な業界のパートナー企業と協力し、業界特化型や最新トレンドに即したデータセット「AIデータレシピ」を継続的に拡充しています。これにより、常に最新かつ高品質なデータを提供し続けることが可能です。
Visual Bankとアマナイメージズ:AI時代のデータインフラを構築
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラの構築・提供を目指すスタートアップ企業です。漫画家をサポートするAI補助ツール『THE PEN』の開発や、本記事で紹介した『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持ち、幅広い分野でAI技術の発展に貢献しています。
同社は、国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。これにより、日本のAI技術の発展と社会課題の解決に大きく寄与することが期待されています。
まとめ:医療AIの未来を拓く、重要な一歩
「日本語・2話者・医療現場の電話応対音声コーパスデータセット」の提供開始は、医療AIの発展にとって非常に重要な一歩となります。この高品質な実環境データを用いることで、音声認識、自然言語処理、生成AIといった基盤技術の精度が飛躍的に向上し、より実用的で信頼性の高い医療AIが開発されることでしょう。
これにより、医療現場の効率化、医療従事者の負担軽減、そして何よりも患者さんへのより質の高い医療サービスの提供が期待されます。AI初心者の方々も、このデータセットが日本の医療の未来をどのように変えていくのか、ぜひ注目してみてください。
関連リンク
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
-
「日本語・2話者・医療現場の電話応対音声コーパスデータセット」詳細: https://qleandataset.visual-bank.co.jp/lineup/pn-033
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/