Qlean Datasetが「日本語・2話者・日常会話音声コーパスデータセット」を提供開始:AI開発の新たな一歩
AI技術の進化が目覚ましい現代において、その基盤となる「学習データ」の質と量は非常に重要です。特に、人間のような自然な会話を理解し、応答できるAI(対話AI)の開発には、リアルな会話データが欠かせません。この度、Visual Bank株式会社傘下の株式会社アマナイメージズが展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」が、この課題に応える新たなデータセットの提供を開始しました。
それが「日本語・2話者・日常会話音声コーパスデータセット」です。このデータセットは、日本人の日常会話をそのまま収録した高品質な音声データで、音声認識(ASR)や自然言語処理(NLP)、対話AIなど、多岐にわたるAI開発を強力に支援します。AI初心者の方にも分かりやすいように、その詳細と活用方法を徹底的に解説していきます。
「日本語・2話者・日常会話音声コーパスデータセット」とは?
このデータセットは、2人の日本人による実際の日常会話を収録した音声データです。特筆すべきは、その「リアルさ」。台本に基づいた会話ではなく、家族、友人、職場の同僚など、様々な関係性の人々が交わす自然な雑談が収められています。
なぜ「リアルな会話」が重要なのか?
私たちが普段話すとき、常に完璧な文章を話しているわけではありません。相づちを打ったり、話が被ったり、途中で話題が変わったり、時には言葉を省略したりします。このような人間の自然な会話の特性をAIに学習させるためには、同じように「生きた」会話データが必要です。
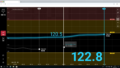
本データセットは、自然な会話のテンポ、相づち、そして発話が被ってしまうようなリアルな状況までを収録しています。さらに、左右のチャンネルに話者を割り当てる「ステレオLR収録」という高品質なWAV形式で提供されるため、それぞれの話者の声をクリアに分離して分析することが可能です。
データセットに含まれる会話の多様性
このデータセットには、恋愛相談、ペットに関する話題、地域のこと、食べ物の話など、非常に多様なトピックが含まれています。これにより、AIは幅広い分野の会話を理解し、それに応じた適切な応答を生成する能力を養うことができます。
データセットの詳しい内容
提供される「日本語・2話者・日常会話音声コーパスデータセット」の具体的な内容は以下の通りです。
-
被写体属性: 20代〜40代の男女が中心です。幅広い年齢層の会話パターンを学習できます。
-
データ形式: 高品質な音声データとして一般的なWAV形式で提供されます。
-
収録時間: 数百時間にわたる膨大な量の音声が収録されています。AIモデルの学習には、質の高いデータが大量に必要となるため、この収録時間は大きな強みとなります。
-
音声条件: LR分離(左右チャンネルに話者を割り当て)により、2人の話者の音声を明確に分離して扱えます。これにより、対話の解析精度が向上します。
-
対象のシーン: 家族、友人、職場の同僚など、身近な関係性の中で交わされる台本なしの自然な日常会話です。これにより、実社会でAIが遭遇するであろう多様な会話シーンに対応できます。
-
主な話題: 恋愛相談、ペットの相談、食べ物や地方についての雑談など、多岐にわたる話題が含まれており、AIの汎用性を高めます。
-
サンプル: 実際にどのような音声が収録されているか、以下のリンクからサンプル音声を確認できます。
このデータセットで何ができる?具体的な活用事例
この「日本語・2話者・日常会話音声コーパスデータセット」は、AI開発の様々なフェーズで役立ちます。具体的なユースケースを見ていきましょう。
1. 音声認識・自然会話理解AIの開発
自然発話に対応した音声認識モデルの学習
私たちが普段使うスマートデバイスや音声アシスタントは、話しかけた言葉を正確に聞き取る必要があります。しかし、実際の会話では、話すスピードが速くなったり、途中で言葉に詰まったり、他の人と同時に話したりすることがよくあります。
このデータセットは、そうした「被り発話(複数の人が同時に話すこと)」や「相づち」、話し方のイントネーションの揺れなど、非常に自然な日常会話の要素を豊富に含んでいます。これを学習データとして使うことで、AIはより現実世界に近い条件で音声認識(ASR)の精度を高めることができます。結果として、スマートデバイスや音声アシスタントが、よりスムーズで正確な会話を理解できるようになるでしょう。
会話文脈理解・発話意図推定AIの開発
AIが単語を認識するだけでなく、「何を言いたいのか」「どういう状況で話されているのか」といった会話の文脈や意図を理解することは非常に高度な技術です。このデータセットは台本がないリアルな対話データのため、話題の転換や、日本語特有の「省略表現」を含む文脈理解モデルの検証に最適です。
自然言語処理(NLP)の分野では、会話の要約、会話の中から重要な要素を抽出する「会話要素抽出」、そして話者の意図を推測する「発話意図推定」などの研究に非常に有効です。これにより、例えばカスタマーサポートのAIが顧客の問い合わせ内容をより深く理解し、適切な対応を提案できるようになることが期待されます。
2. 感情・コミュニケーション解析AIの研究
感情認識・発話行動分析
人間は声のトーンや話し方から相手の感情を読み取ることができます。AIも同様に、発話速度、声の抑揚、沈黙の長さといった特徴を分析することで、話者の感情を推定したり、心の状態を分類したりする感情理解AIの研究に活用できます。
さらに、笑い声や相づちを打つタイミングなど、人間らしい会話のリズムや間合いを解析することで、コミュニケーションの分析にも利用可能です。これにより、より人間らしい対話を行うAIの開発や、コミュニケーション支援システムの構築に役立つでしょう。
会話スキル評価・対話教育への応用
このデータセットを用いることで、発話内容と応答の流れを解析し、個人の対話能力を評価するAIシステムや、スピーキング教育を支援するAIなどの開発にも応用できます。例えば、外国語学習者が自然な会話を練習する際に、AIが適切なフィードバックを提供するといった使い方が考えられます。
3. 実環境データを用いたAI応用・社会実装
会話要約・自動議事録生成AIの検証
会議の議事録作成や、カスタマーサポートの通話記録の要約は、時間と手間がかかる作業です。このデータセットは、家庭、職場、友人同士など多様な会話内容を含んでいるため、対話の内容を要約したり、構造化したり、重要な情報を抽出したりするAIモデルの検証データとして非常に有効です。
これにより、カスタマーサポートにおけるコールログ解析や、会議の自動議事録生成といった業務効率化AIへの応用が期待されます。
ヒューマン・インタラクション研究
人間同士の会話では、相手の発言のタイミングに合わせて応答したり、表情やジェスチャーを伴ったりと、様々なインタラクション(相互作用)が行われます。このデータセットは、発話のタイミングや応答の傾向を分析することで、人間同士の会話特性を再現するインタラクションモデルの開発に活用できます。
ソーシャルロボティクス(人と関わるロボット)や教育支援AIなど、人とAIがより自然に対話できるように設計する研究において、このデータセットは貴重な資源となるでしょう。
Qlean Dataset(キュリンデータセット)とは?
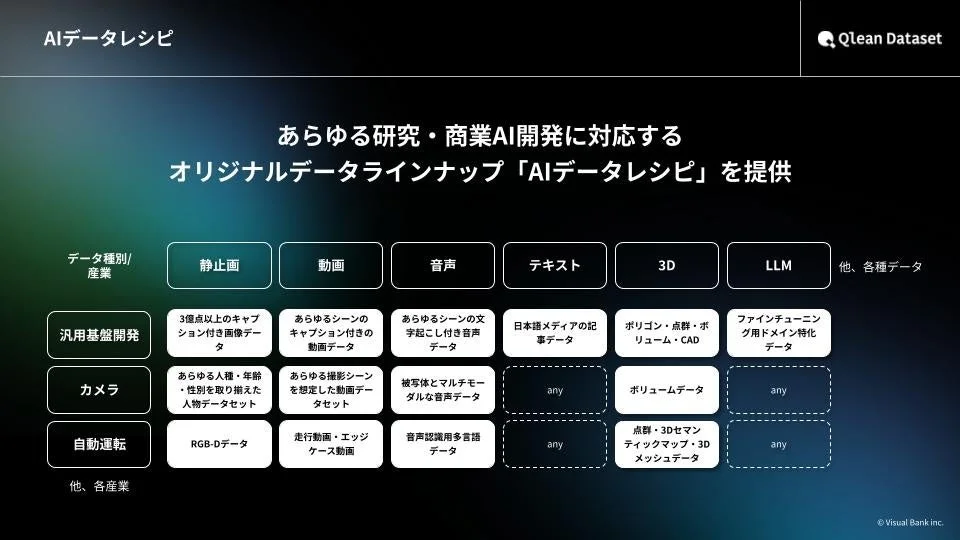


今回提供が開始されたデータセットは、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する「Qlean Dataset」の一部です。Qlean Datasetは、AI開発に必要な学習データを商用利用可能な形で提供するソリューションであり、研究用途から商用用途まで、あらゆるAI開発者が安心して利用できる環境を整えています。
Qlean Datasetの特長
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多岐にわたる形式のデータに対応しています。その大きな特長は以下の通りです。
-
権利クリアで法的リスクなし: すべての被写体から同意を取得しており、GDPR(EU一般データ保護規則)やCCPA(カリフォルニア州消費者プライバシー法)といった国際的な法規制にも準拠しています。これにより、AI開発者はデータの権利に関する心配なく、開発に集中できます。
-
迅速なデータ提供: 既存のデータセットであれば、最短1日で納品が可能。AI開発のスピードアップに貢献します。
-
カスタムデータ構築にも対応: 既存のデータではニーズを満たせない場合でも、個別の要望に応じたカスタム撮影、収録、収集による独自のデータセット構築にも対応しています。
-
「AIデータレシピ」による充実したラインナップ: 株式会社千葉ロッテマリーンズや株式会社東洋経済新報社など、様々なデータパートナーとの協業を通じて、業界に特化したり、最新トレンドに対応したデータラインナップ「AIデータレシピ」を継続的に拡充しています。
Qlean Datasetは、AI開発現場におけるデータ収集や整備にかかる負担を大幅に軽減し、法的リスクのないAI開発環境の構築を支援する、まさにAI開発者の心強い味方と言えるでしょう。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家向けのAI補助ツール「THE PEN」の提供や、AI学習用データセット開発サービス「Qlean Dataset」を提供する株式会社アマナイメージズを100%子会社に持つなど、多角的に事業を展開しています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、AI技術の社会実装に向けた取り組みを加速させています。
まとめ:リアルな会話データがAIの未来を拓く
Qlean Datasetが提供を開始した「日本語・2話者・日常会話音声コーパスデータセット」は、AIがより人間らしいコミュニケーション能力を身につけるための重要な一歩となるでしょう。リアルな日常会話を網羅したこの高品質なデータセットは、音声認識、自然言語処理、対話AI、感情解析など、多岐にわたるAI技術の研究開発を加速させます。
AI開発におけるデータ収集の課題を解決し、権利面でも安心して利用できるQlean Datasetの登場は、AI技術の社会実装をさらに推進し、私たちの生活をより豊かにするAIサービスの創出に貢献するはずです。AI開発に携わる企業や研究者にとって、このデータセットは強力なツールとなるでしょう。