
- AI OCRの「90%の壁」を突破!Irwin&coの新「PDF構造化技術」が不規則PDFも99.9%高精度データ抽出で業務を劇的に効率化
- 多くの企業が抱えるAI OCRの課題とは?「期待外れ」の声が上がる背景
- 「PDF構造化技術」がAI OCRの常識を覆す!99.9%の高精度を実現する秘密
- 新技術「PDF構造化技術」の3つの画期的な特徴
- 【事例紹介】データ入力事務員を80%以上削減!不動産データの自動化を実現
- 貴社での導入を検討する方へ:Irwin&co株式会社のサポート体制
- Irwin&co株式会社とは:「成果を出すAI」を理念に掲げる企業
- まとめ:AI PDF構造化技術が切り拓くデータ入力業務の新たな時代
AI OCRの「90%の壁」を突破!Irwin&coの新「PDF構造化技術」が不規則PDFも99.9%高精度データ抽出で業務を劇的に効率化
近年、多くの企業で業務効率化の切り札として注目されているAI技術。特に、紙やPDFの情報をデジタルデータに変換する「AI OCR」は、データ入力業務の自動化に大きく貢献すると期待されています。しかし、実際に導入した企業からは「期待したほど効果がない」「結局、人の手による修正が必要になる」といった声も少なくありませんでした。
そんなAI OCRが抱える長年の課題を解決する、画期的な新技術が誕生しました。Irwin&co株式会社は、生成AIを活用した「PDF構造化技術」を正式にリリース。この技術は、これまで困難とされてきた不規則なPDFファイルからでも、驚異的な99.9%の精度でデータを自動抽出することを可能にします。これにより、データ入力業務の真の自動化と、大幅なコスト削減が期待されています。
多くの企業が抱えるAI OCRの課題とは?「期待外れ」の声が上がる背景
データ入力業務は、企業の日常業務において非常に大きな割合を占めます。請求書、契約書、顧客情報、アンケートなど、日々膨大な量の書類が処理されており、これらの手作業による入力は時間とコストがかかり、ミスも発生しやすいという課題がありました。そこで、AI OCR(光学文字認識)が導入され、文字を自動で読み取ることで業務効率化が図られてきました。
しかし、多くの企業がAI OCRを導入したものの、「期待したほど楽にならない」という声が聞かれるのはなぜでしょうか。その主な原因は、従来のAI OCR技術が抱える構造的な課題にありました。
1. 認識精度の限界「90%の壁」
従来のAI OCRは、PDFファイルを単なる「画像」として認識し、画像の中から文字を識別していました。この方法では、どれほど高性能なAI OCRであっても、読み取り精度は高くても90%程度にとどまることが一般的でした。残りの10%の誤認識は、どうしても発生してしまうのです。
2. 結局残る「手作業」と修正コスト
読み取り精度が90%であっても、ビジネスにおいては100%正確なデータが求められます。そのため、AI OCRで読み取った後も、残りの10%の誤読を修正するために、結局は人間がすべてのデータを一つ一つ目視で確認し、手作業で修正する必要がありました。これでは、コスト削減効果が限定的となり、真の業務効率化にはつながりません。
3. 形式が不揃いな書類への対応困難
特に課題となっていたのが、レイアウトが複雑で形式が不揃いな書類への対応です。例えば、不動産会社ごとにレイアウトが異なる「不動産マイソク(販売図面)」や、PowerPoint、ExcelからエクスポートされたPDFなど、定型フォーマットではない書類が混在する場合、従来のAI OCRでは「どの数値がどの項目に該当するのか」といった文脈を理解することができませんでした。そのため、正しくデータを抽出することが極めて困難だったのです。
Irwin&co株式会社は、これらの課題に直面する企業、そしてこれから失敗のないシステム導入を目指す企業のために、従来のAI OCRとは根本的に異なるアプローチで新たなシステムを開発しました。
「PDF構造化技術」がAI OCRの常識を覆す!99.9%の高精度を実現する秘密
Irwin&coが開発した「PDF構造化技術」は、従来のAI OCRがPDFを「画像(絵)」として読み取っていたのに対し、PDFを「意味と構造を持つ文書」として認識するという、全く新しいコンセプトに基づいています。
この技術の最大の秘密は、PDFの種類に応じて最適な処理を使い分ける「ハイブリッドなアプローチ」にあります。
-
テキストデータを含むPDF: WordやExcel、PowerPointなどから直接作成されたPDFのように、内部にテキスト情報を持つファイルに対しては、画像解析を行わず、テキスト情報を直接抽出し構造化します。これにより、約100%という極めて高い精度でのデータ抽出が可能になります。
-
スキャンデータ等の画像PDF: 紙媒体をスキャンして作成されたPDFのように、画像として認識する必要があるファイルに対してのみ、従来の画像解析技術を適用します。
この二つのアプローチを組み合わせることで、全体として99.9%という圧倒的なデータ読み取り精度を達成しました。これにより、従来のAI OCRでは避けられなかった「目視チェックと手修正」の手間をほぼ解消し、データ入力業務の真の自動化を実現します。
従来のAI OCR技術とPDF構造化技術の比較
| 項目 | 本技術(PDF構造化技術) | 従来のAI OCR技術 |
|---|---|---|
| 技術概要 | PDFを「意味と構造を持つ文書」として理解 | PDFを「画像」として扱い、文字を読み取る |
| 精度 | 約100%(ハイブリッド処理により全体で99.9%) | 90%程度(10%の誤りが発生) |
| 理解力 | 見出し・項目・数値の関係性を理解し、文脈から推論が可能 | 文字を正しく読むことがゴール(関係性は理解しない) |
| 実務耐性 | 不規則なフォーマットや複数形式が混在する文書にも対応 | フォーマットが崩れると精度が落ちる |
| 成果 | 入力作業・人的コストを大幅削減、真の自動化を実現 | 人による確認・修正作業がかなり残る |
新技術「PDF構造化技術」の3つの画期的な特徴
Irwin&coのPDF構造化技術は、その高精度だけでなく、業務現場での使いやすさや汎用性においても大きな特徴を持っています。
1. AI OCRの限界を超えた「意味理解」による高精度読み取り
この技術の最大の強みは、単に文字を認識するだけでなく、生成AIが「見出しと数値の関係」や「表の構造」といった文書の文脈を深く理解する点にあります。これにより、「この数値は何の項目か」といった情報を人間と同等、あるいはそれ以上の精度で推論し、正確にデータベース化することが可能です。誤認識が大幅に減るため、データ入力の品質が飛躍的に向上します。
2. あらゆる不規則フォーマットに柔軟に対応
従来のAI OCRが苦手としていた、レイアウトが不規則な文書や、複数のファイル形式が混在するケースにも強力に対応します。例えば、不動産会社ごとに異なるフォーマットの「マイソク(販売図面)」や、Word、Excel、PowerPointからエクスポートされたPDF、さらには「登記簿謄本」のような定型外の書類でも、AIが自動でファイル形式と内容を判別し、必要な情報を正確に抽出することができます。これにより、多様な業務フローに柔軟に組み込むことが可能になります。
3. データ入力コストを大幅に圧縮
高精度な読み取りと意味理解により、従来のAI OCRでは必須だった「全件目視チェック」や「手修正」の作業がほぼ不要になります。これにより、データ入力にかかる人的コストを大幅に削減できるだけでなく、作業時間の短縮、従業員の負担軽減にもつながります。結果として、企業全体の生産性向上に大きく貢献します。
【事例紹介】データ入力事務員を80%以上削減!不動産データの自動化を実現
Irwin&coのPDF構造化技術は、すでに実際の業務現場でその効果を発揮しています。特に、不動産データ(マイソクやデベロッパーから受領する不規則な不動産データなど)の読み取りにおいて、その威力を発揮しました。
この事例では、不動産資料の99%がスキャンデータではなくテキストデータで構成されているという前提に基づいています。
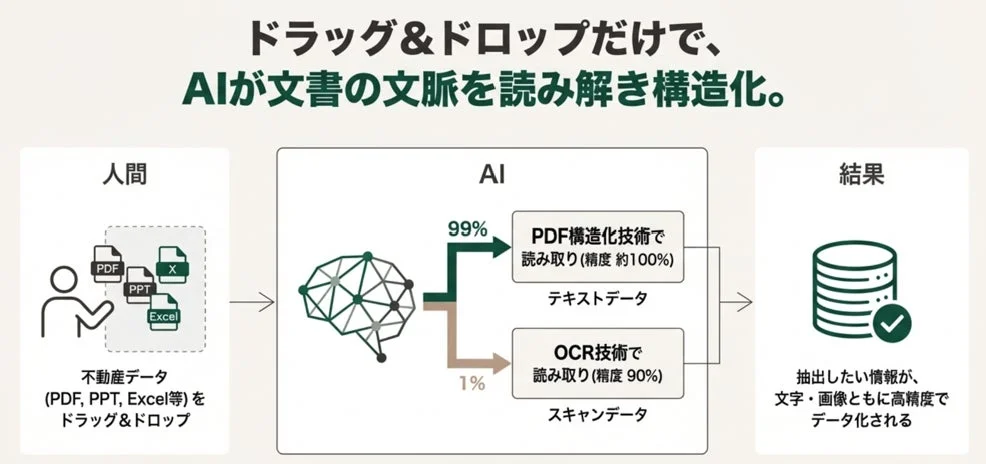
1. ドラッグ&ドロップによる入力と判別
まず、不動産データ(PDF、PowerPoint、Excelなど)をシステムにドラッグ&ドロップで投入します。システムは投入されたファイルが「テキストデータを保持したファイル形式」なのか、それとも「紙をスキャンしたような画像データ」なのかを瞬時に判断します。
2. 構造化技術による高精度読み取り(全体の99%)
全体の99%を占めるテキストデータを保持しているファイルに対しては、画像認識ではなく、データ内部のテキスト構造を直接解析します。このPDF構造化技術により、約100%の精度で読み取りが可能となり、抽出したい情報を文字・画像のまま高精度でデータ化します。
3. OCR技術による読み取り(全体の1%)
残りの1%にあたる、紙をスキャンしたような画像データに対しては、従来のOCR技術を用いて読み取ります。この場合、精度は90%程度となり、一部に誤った情報が含まれる可能性があります。
全体の精度算出と効果
スキャンデータ(全体の1%)に含まれる微細な読み取りミス(10%)が全体に及ぼす影響は、計算上わずか0.1%(1% × 10%)です。結果として、残り99.9%のデータにおいて正確な読み取りを実現しています。
この導入事例では、データ入力事務員を従来の6名から1名へと大幅に削減することに成功しました。これは、データ入力業務における人的コストを80%以上削減できたことを意味し、業務の劇的な効率化とコスト削減効果を明確に示しています。
貴社での導入を検討する方へ:Irwin&co株式会社のサポート体制
Irwin&co株式会社は、この革新的なPDF構造化技術を、企業の具体的な課題解決に役立てるためのサポート体制を整えています。
導入までの流れ
- ヒアリング・デモ実施: 貴社の具体的な課題や、対象となる帳票(PDF)の種類を確認し、システムのデモンストレーションを実施します。
- トライアル検証: 実際のデータを用いて、PDF構造化技術の読み取り精度を体験していただきます。
- 本導入・運用開始: システム連携や運用フローの構築をサポートし、スムーズな導入を支援します。
詳細については、Irwin&co株式会社まで直接お問い合わせください。
Irwin&co株式会社とは:「成果を出すAI」を理念に掲げる企業
Irwin&co株式会社は、「導入するだけのAIではなく、成果を出すAI」を理念に掲げ、生成AIを活用した受託開発を主力事業として展開しています。顧客企業の真の課題解決に貢献するため、最先端のAI技術を駆使したソリューションを提供しています。
-
社名: Irwin&co株式会社
-
代表者: 代表取締役 アーウィン海
-
所在地: 〒150-0004 東京都渋谷区円山町5丁目5号
-
設立: 2025年6月
-
社員数: 20名(業務委託含む)
-
事業内容: 生成AIに係るシステム開発・コンサルティング・講習会
本件に関するお問い合わせ先
-
代表取締役: アーウィン海
-
取締役/広報担当: 田中康太郎
-
E-mail: kotaro.tanaka@irwin-and-co.com
-
Tel: 090-1545-1708
まとめ:AI PDF構造化技術が切り拓くデータ入力業務の新たな時代
Irwin&co株式会社が正式リリースした「PDF構造化技術」は、従来のAI OCRが抱えていた「精度90%の壁」や「手修正の負担」といった長年の課題を根本から解決する、画期的なソリューションです。PDFを「意味と構造を持つ文書」として理解し、テキストデータと画像データをハイブリッドに処理することで、不規則なPDFファイルからでも99.9%という驚異的な精度で情報を自動抽出することを可能にしました。
これにより、データ入力業務における「目視チェックと手修正」がほぼ不要となり、人的コストの大幅な削減と、真の業務効率化が実現します。不動産データの自動化事例が示すように、この技術は企業の生産性向上と競争力強化に大きく貢献する可能性を秘めています。
AI導入を検討しているものの、従来のAI OCRの精度に不満を感じていた企業や、これからデータ入力業務の自動化を進めたい企業にとって、Irwin&coのPDF構造化技術は、まさに待望のソリューションと言えるでしょう。データ活用の新たな時代を切り拓くこの技術に、今後も注目が集まります。

