
Qlean Datasetが日本語・2話者・レジャーテーマトーク音声コーパスを提供開始
AI(人工知能)の技術は日々進化しており、私たちの生活に欠かせないものとなりつつあります。特に、音声認識や自然言語処理、そして近年注目されている大規模言語モデル(LLM)といった分野では、高品質な「学習データ」がAIの性能を大きく左右します。
そんな中、Visual Bank株式会社は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、新たなデータセットの提供を開始しました。それが「日本語・2話者・レジャーテーマトーク音声コーパスとトランスクリプト」です。

このデータセットは、ASR(自動音声認識)、NLP(自然言語処理)、LLMなどの音声・言語系AI開発を強力に支援するために開発されました。AI初心者の方にも分かりやすく、このデータセットがどのようなものなのか、そしてAI開発においてなぜ重要なのかを詳しくご紹介します。
AI開発を支える「音声コーパス」とは?
AIが人間の言葉を理解したり、話したりするためには、大量の「言葉のデータ」を学習する必要があります。この言葉のデータのことを「コーパス」と呼びます。特に、音声とそれに対応するテキスト情報が含まれるものを「音声コーパス」と呼びます。
Qlean Datasetが今回提供を開始したデータセットは、まさにこの音声コーパスの一種です。AIがより自然な日本語の会話を理解し、生成できるようになるためには、実際の人間が話す、多様なテーマの会話データが不可欠です。
「日本語・2話者・レジャーテーマトーク音声コーパスとトランスクリプト」の詳細
この新しいデータセットは、Qlean Datasetが展開する機械学習用データセットラインナップ『AIデータレシピ』に加わるものです。
データの内容と特長
このデータセットの最大の特長は、「レジャーや趣味、娯楽」をテーマに、2名の話者が対話形式で語り合う日本語音声と、その発話内容を正確に書き起こしたトランスクリプト(テキストデータ)が収録されている点です。
具体的な会話の題材としては、以下のような日常的な話題が含まれます。
-
ドラマやアニメなどの作品に対する感想や考察
-
ゲームやガジェットのレビュー
-
旅行や外出に関する体験談
収録は、台本に厳密に依存せずに行われています。これにより、参加者が作品や体験に対する感想や意見交換を、より自然な流れで交わす対話が実現されています。このような「生きた会話」のデータは、実際の会話シーンを想定した音声認識や対話処理といったAIの研究・開発において、非常に価値が高いと言えます。
データセットの概要
提供されるデータセットの具体的な仕様は以下の通りです。
-
データ種別: 音声、テキスト
-
被写体属性: 20代〜50代の男女
-
データ形式: 音声データはmp3またはwav形式、テキストデータはtxt形式
-
収録時間: 合計で約400時間(1つの音声ファイルは5分から60分程度)
-
音声レート: 44.1kHz
-
対象のシーン: 2名が趣味・娯楽テーマについて連続的に説明・解説・振り返りを行うシーン、または体験談や感想を交えながら自由に会話が展開される場面。
より詳しい情報やサンプルは、以下のリンクから確認できます。
このデータセットがAI開発にもたらす価値
この「日本語・2話者・レジャーテーマトーク音声コーパスとトランスクリプト」は、AI開発における様々な課題を解決し、新しい可能性を広げます。
研究用途での活用例
AIの研究者にとって、このデータセットは以下のような用途で活用できます。
-
日本語対話音声認識モデルの検証: 複数人が会話する音声を入力としたASR(自動音声認識)モデルでは、誰がいつ話しているのか、そしてその発話内容を正確に認識することが非常に重要です。このデータセットは、話者の切り替わりや、応答関係を含む発話の認識精度を検証するために利用できます。
-
対話文脈を考慮した言語モデル研究: LLM(大規模言語モデル)や対話モデルは、単語だけでなく、会話全体の流れや文脈を理解することが求められます。このデータセットに含まれる話題の展開や相互参照を含む日本語対話テキストは、モデルが文脈をどれだけ正確に理解し、適切な応答を生成できるかを評価する研究に役立ちます。
産業用途での活用例
企業がAI技術を製品やサービスに応用する際にも、このデータセットは大きな恩恵をもたらします。
-
音声UI・対話型AIの検証用途: スマートフォンやスマートスピーカーの音声アシスタント、あるいはチャットボットのような対話型インターフェースの開発において、日常会話に近い日本語対話音声は非常に貴重です。このデータセットは、実際のユーザーとの会話を想定した入力処理や対話制御のPoC(概念実証)検証に利用できます。
-
日本語LLMの対話性能評価・追加学習: 業務会話に限定されない、より自然で多様な対話テキストは、日本語LLMの対話性能を評価したり、特定の対話スタイルに特化させるためのファインチューニング(追加学習)用途に活用できます。これにより、より人間らしい自然な応答を生成できるLLMの開発が期待されます。
『Qlean Dataset(キュリンデータセット)』について
『Qlean Dataset』は、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。AI開発の現場では、学習データの収集や整備が大きな負担となることが少なくありません。Qlean Datasetは、こうした課題を解決し、開発者が安心してAI開発に集中できる環境を提供しています。
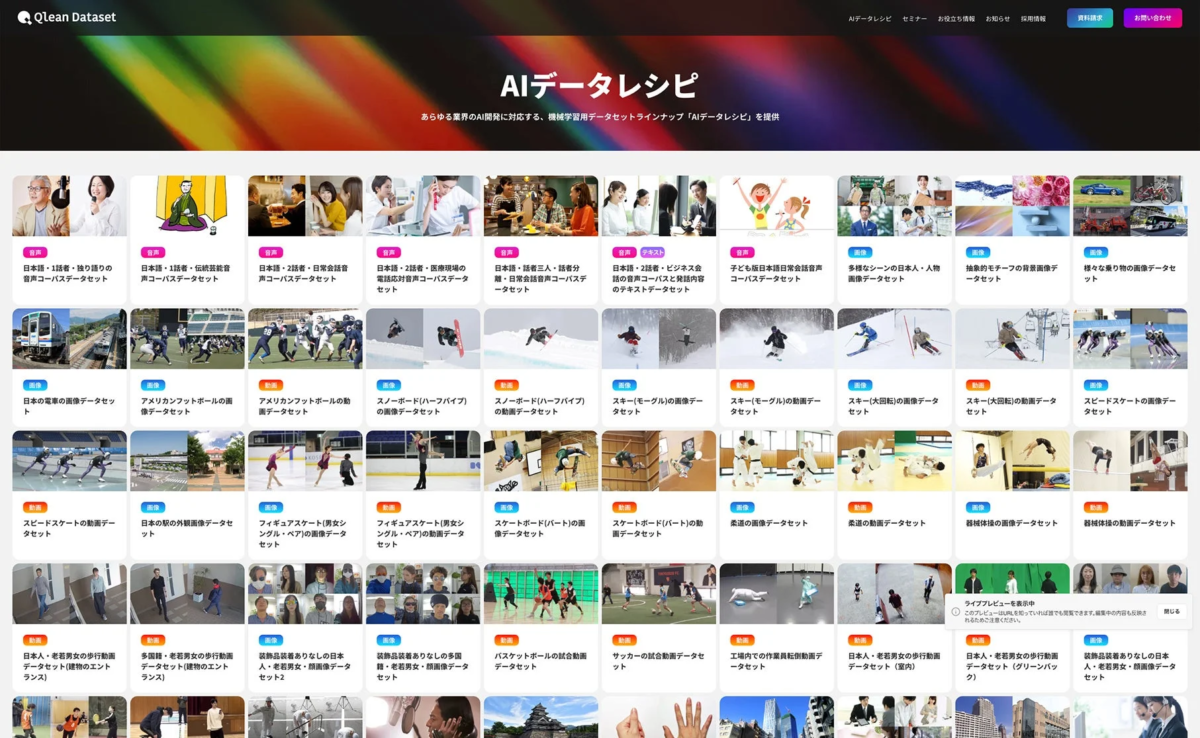
多様なデータ形式と安全な利用環境
Qlean Datasetは、画像、動画、音声、3D、テキストといった多様な形式のデータに対応しています。そして何よりも重要なのは、提供されるデータが研究用途から商用開発まで、いずれの用途でも安全に利用できるよう、権利処理や利用条件が明確に整理されている点です。これにより、著作権や肖像権といった法的リスクを心配することなく、AI開発を進めることができます。
『AIデータレシピ』によるデータラインナップの拡充
Qlean Datasetは、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社をはじめとする様々なデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータラインナップ『AIデータレシピ』を継続的に拡充しています。これにより、AI開発現場のニーズに応じた、多様なデータが提供され続けています。
Qlean Datasetについて、さらに詳しく知りたい方は、以下のサイトをご覧ください。
『Qlean Dataset』の主な特長
AI開発者がQlean Datasetを選ぶメリットは多岐にわたります。

-
すべての被写体から同意取得済み: 提供されるデータに含まれる人物など、すべての被写体から事前に同意が取得されています。これにより、肖像権などの問題を気にすることなく、安心してデータを利用できます。
-
既存データは最短1日で納品可能: 必要なデータが既存のラインナップにあれば、最短1日というスピードでデータが手元に届きます。これにより、AI開発のサイクルを大幅に短縮できます。
-
カスタム撮影・収録・収集による独自データ構築にも対応: もし既存のデータセットでは要件を満たせない場合でも、Qlean Datasetは顧客の要望に応じて、独自のデータ撮影、収録、収集を行うことで、オーダーメイドのデータセットを構築して提供することが可能です。
これらの特長は、AI開発におけるデータ調達の障壁を低減し、より効率的かつ法的に安全な開発環境を実現するためのものです。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。

同社は、漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持っています。
さらに、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、AI技術の社会実装に向けた取り組みを加速させています。このような背景を持つ企業が提供するデータセットは、信頼性と品質の面で非常に高い水準にあると言えるでしょう。
まとめ:日本語AI開発の未来を拓くデータセット
今回Qlean Datasetが提供を開始した「日本語・2話者・レジャーテーマトーク音声コーパスとトランスクリプト」は、日本語の音声・言語系AI開発、特に自然な対話能力を持つAIの開発において、非常に重要な基盤となるデータセットです。
台本に縛られない自然な会話データは、現実世界の多様な会話シーンに対応できるAIを育成するために不可欠です。研究者から企業まで、幅広いAI開発者がこのデータセットを活用することで、より高度で実用的な音声認識AI、対話型AI、そしてLLMの開発が加速されることでしょう。
Qlean Datasetは、法的リスクのない高品質なデータを提供することで、AI開発の障壁を取り除き、日本のAI技術の発展に大きく貢献していくことが期待されます。
AI開発に携わる方々、あるいはこれからAI技術の導入を検討されている方々にとって、この新しいデータセットは、きっと新たな可能性を切り開く鍵となるはずです。

