GMOインターネットがNVIDIA B300 GPUのAI性能を実証!「GMO GPUクラウド」で最適なGPU選びをサポート
AI技術の進化が目覚ましい現代において、その基盤となるGPU(Graphics Processing Unit)の性能は、開発のスピードと成果を大きく左右します。GMOインターネット株式会社は、同社が提供する「GMO GPUクラウド」において、最新の「NVIDIA HGX B300 AI インフラストラクチャ」(以下、B300 GPU)と「NVIDIA H200 Tensor コアGPU」(以下、H200 GPU)の性能実証を行い、その結果を公開しました。この検証は、生成AIの開発から運用まで、さまざまなAIワークロードにおけるGPUの最適な選択肢を見つけるための重要な情報を提供します。
「GMO GPUクラウド」とは?AI開発を支える国内最速クラスの計算基盤
「GMO GPUクラウド」(https://gpucloud.gmo/)は、NVIDIA H200 Tensor コアGPUを搭載し、国内で初めて高速ネットワークNVIDIA Spectrum-Xと高速ストレージを実装したGPUクラウドサービスです。
このサービスは、2024年11月に発表された世界のスーパーコンピュータ性能ランキング「TOP500」で世界第37位、国内第6位にランクインするなど、商用クラウドサービスとして国内最速クラスの計算基盤を提供しています。さらに、2025年6月には電力効率を競う世界ランキング「Green500」で世界第34位、国内第1位を獲得し、その高性能と省電力性が国際的に評価されています。2025年12月には、NVIDIAの次世代GPU「NVIDIA Blackwell Ultra GPU」を搭載した「NVIDIA HGX B300」のクラウドサービス提供も開始されており、常に最先端の技術を提供し続けています。
なぜ性能検証が必要なのか?AIワークロードに合わせたGPU選びの重要性
AI、特に生成AIの開発や運用では、GPUに求められる性能が多岐にわたります。例えば、AIモデルを学習させる際には膨大な計算能力が、学習済みのモデルを使って推論を行う際には高速な処理スループットが、そして科学技術計算のような高精度な数値計算では正確な演算能力がそれぞれ重要になります。
GMOインターネットは、これらの異なるニーズに応えるため、B300 GPUとH200 GPUがどのような特性を持つのかを深く理解する必要があると考え、以下の3つのベンチマークテストを実施しました。これにより、お客様が自身のAIワークロードに最適なGPUを選択できるよう、具体的な参考情報を提供することを目的としています。
実施された3つのベンチマークとその結果を詳しく解説
1. 大規模言語モデル(LLM)の学習ベンチマーク:AIの「賢さ」を育む時間効率
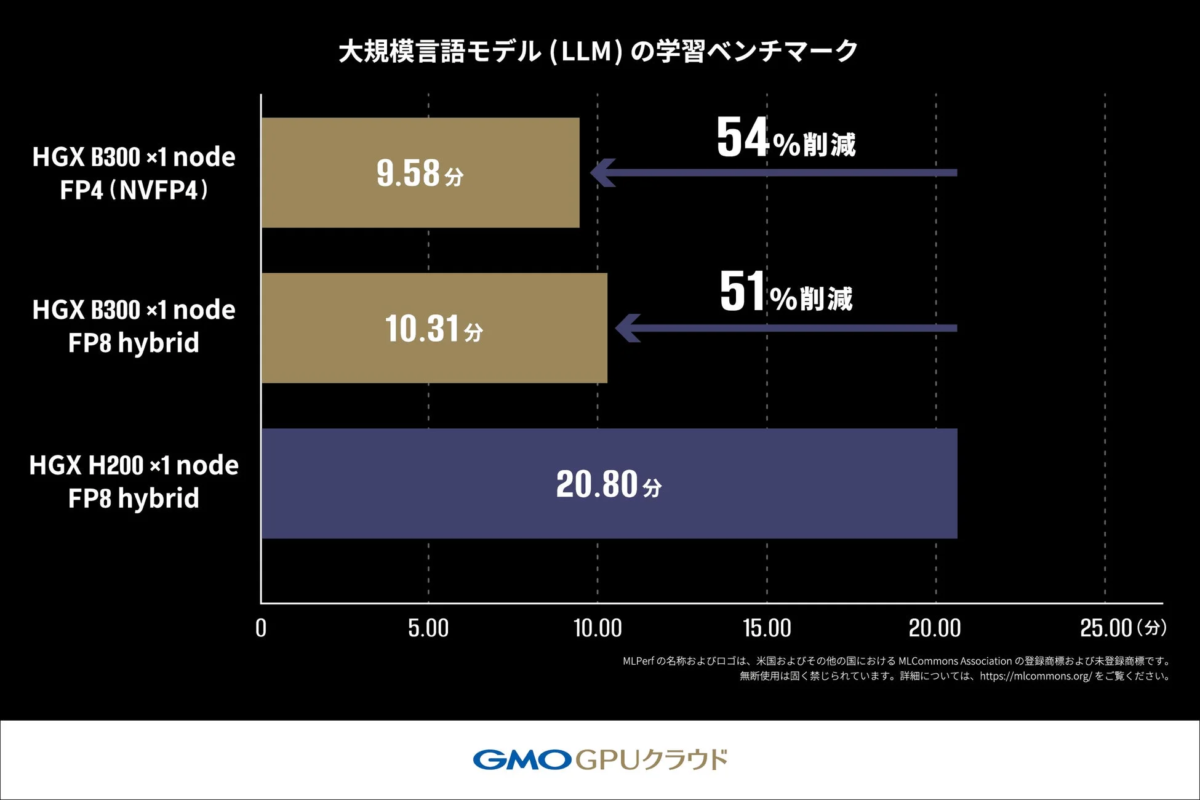
大規模言語モデル(LLM)の学習は、AIが人間のような言葉を理解し、生成するための基盤を構築する非常に重要なプロセスです。このベンチマークでは、LLMを実際に学習(ファインチューニング)させ、目標の品質に到達するまでの学習完了時間を測定することで、「学習効率」と「演算速度」を評価しました。
具体的には、機械学習システムの性能測定における国際的なベンチマーク標準であるMLPerf® Training v5.1のルールに従い、Llama2 70Bモデルを用いたLoRAファインチューニングにかかる学習時間を測定しています。評価指標には、AIモデルの予測精度を測る「クロスエントロピー損失」を用い、目標値(0.925)に達するまでの時間を比較しました。

この結果、H200 GPU搭載機材では20.80分かかっていた学習時間が、B300 GPU搭載機材では10.31分で完了し、約2倍の速度で処理が完了することが確認されました。さらに、NVIDIA Blackwellアーキテクチャから新たに対応した「FP4(4ビット浮動小数点演算)」を用いた測定では、従来のFP8 hybrid(8ビット浮動小数点演算と高精度演算を組み合わせた混合精度学習手法)よりも短い時間で処理が完了しており、FP4の高い演算性能が学習にも大きな恩恵をもたらす可能性が示唆されています。
これは、より少ないデータ量で高速に計算できるFP4が、AIモデルの学習時間を大幅に短縮し、開発効率を向上させる可能性を秘めていることを意味します。MLPerf®については、MLCommons Associationが管理しており、その詳細についてはhttp://www.mlcommons.org/をご覧ください。
2. vLLM bench throughputによる推論ベンチマーク:AIの「応答速度」と「処理能力」
AIモデルが学習を終えた後、実際にユーザーからの質問に答えたり、画像を生成したりする際に必要となるのが「推論」です。このベンチマークでは、単位時間あたりに生成可能な「トークン量(処理スループット)」を評価することで、AIサービスの応答性能や処理能力を測りました。
具体的には、大規模言語モデル推論エンジン「vLLM」のベンチマークツールであるOffline Throughput Benchmarkを用い、Llama-3.1-405B-Instructモデルの推論スループットを測定しました。これは、LLM推論のバッチ処理において、H200 GPUおよびB300 GPUが1秒あたりに生成できる出力トークン数(output tokens/s)の最大処理能力を比較するものです。
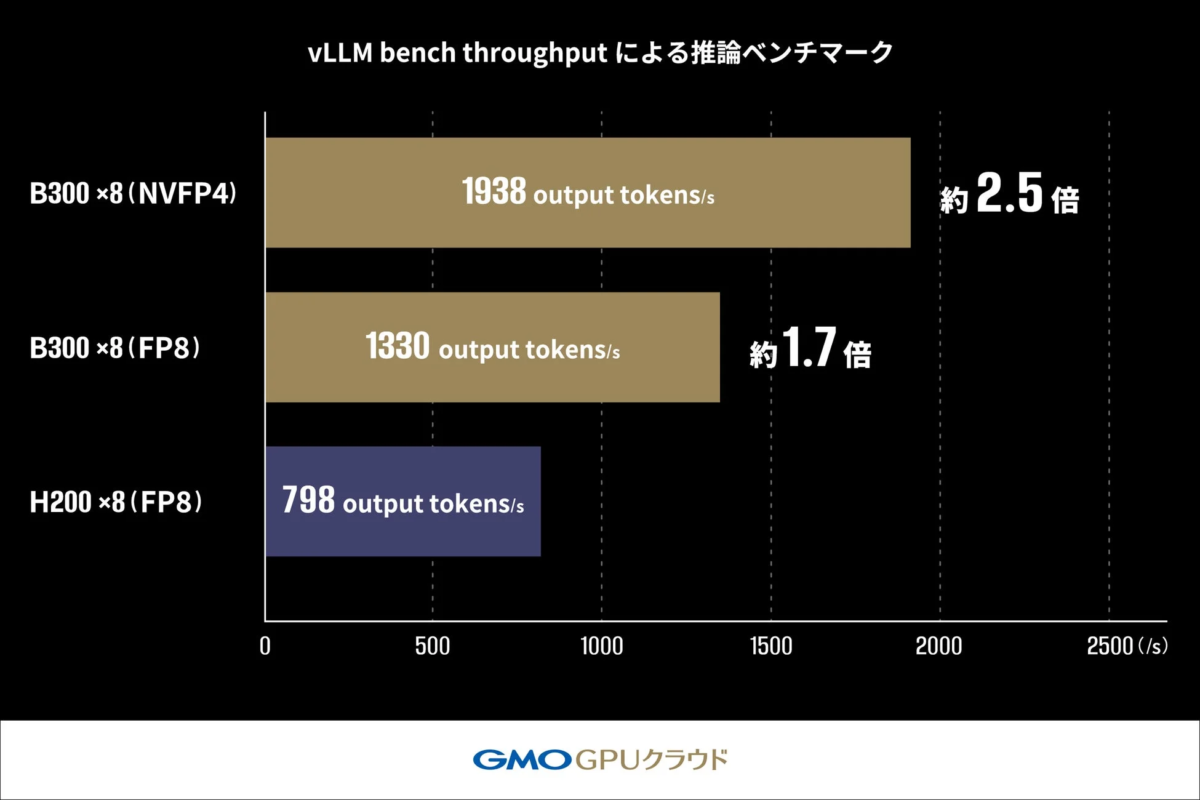
このベンチマークにおいて、H200 GPU(FP8)構成では798 tokens/sであったスループットが、B300 GPU(FP8)構成では約170%(約1.7倍)の1330 tokens/sまで向上しました。さらに、FP4(NVFP4)を適用した構成では1938 tokens/sを達成し、H200 GPU構成に対し約250%(約2.5倍)もの性能向上が確認されました。この結果は、FP4の活用が大規模モデルの推論パフォーマンスを劇的に向上させるための、非常に有力な手段の一つであることを示しています。
3. HPL Benchmarkによるベンチマーク:スーパーコンピュータ級の「高精度計算能力」
AIの分野だけでなく、科学技術計算や気象予測、創薬研究など、わずかな誤差も許されない高精度な数値計算を必要とする分野も多く存在します。このベンチマークでは、スーパーコンピュータの性能評価に用いられる国際標準ベンチマークであるHPL Benchmarkを用いて、B300 GPU搭載機材とH200 GPU搭載機材のLINPACK性能を比較しました。
HPL Benchmarkでは、浮動小数点演算性能を測定し、1秒間に実行できる演算回数をGFLOPS(10億回の浮動小数点演算/秒)という単位で算出します。この値が高いほど、複雑な数式を正確に解く計算能力が高いことを示します。
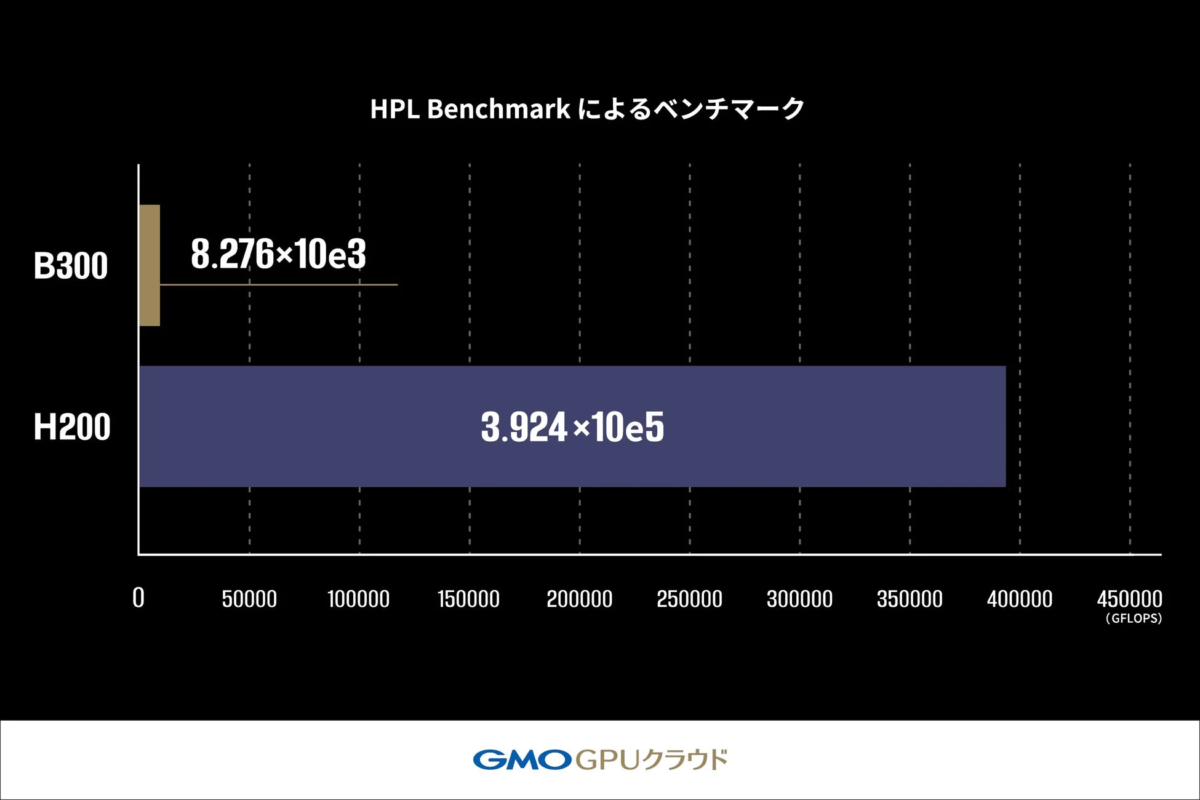
その結果、B300 GPU搭載機材の性能はH200 GPU搭載機材のわずか2.1%(約47分の1)に留まりました。これは、B300 GPUが生成AIワークロードに最適化された設計である一方、HPL Benchmarkで測定されるような高精度演算(FP64)には、依然としてH200 GPUが優れていることを示しています。つまり、B300 GPUは生成AIに最適な低精度演算(FP4/FP8)に特化しているため、高精度な数値演算を必要とする科学技術計算の場面ではH200 GPUがより有用であると考えられます。
ベンチマーク結果から見えてくる最適なGPU選びのヒント
今回の検証結果から、B300 GPUとH200 GPUには明確な性能特性の違いがあることが明らかになりました。
-
NVIDIA B300 GPU: 生成AIの学習においてはH200 GPUの約2倍、推論においては約2.5倍の処理性能を発揮することが確認されました。特にFP4のような低精度演算を活用することで、生成AIワークロードにおける高速化と効率化に大きく貢献します。生成AIの開発や運用、高速なAI応答が求められるサービスなどに最適と言えるでしょう。
-
NVIDIA H200 GPU: 大規模言語モデルの学習においても高い性能を発揮しますが、特にHPL Benchmarkで示されたように、科学技術計算やシミュレーションなど、極めて高い数値計算の正確性が求められるユースケースにおいて、依然としてその真価を発揮します。
GMOインターネットのプロジェクト統括チーム エグゼクティブリードである佐藤嘉昌氏は、「今回のベンチマーク結果は、B300 GPUとH200 GPUの性能特性の違いを示す一つのデータとしてご参考いただけると考えています。『GMO GPUクラウド』は、お客様の開発目的や利用用途に寄り添い、より効率的に計算資源を活用いただけるよう、技術協力を継続的に行い、AI開発環境における技術向上に寄り添ってまいります。」とコメントしています。
この結果は、AI開発者が自身のプロジェクトの目的や必要な計算の種類に応じて、適切なGPUを選択することの重要性を示しています。闇雲に最新のGPUを選ぶのではなく、その特性を理解し、ワークロードに合わせたGPUを選ぶことが、開発期間の短縮とコスト削減、そしてより良い成果につながる鍵となるでしょう。
今後の展開:AI産業の発展を支える「GMO GPUクラウド」
GMOインターネットは、今回の性能検証結果を踏まえ、「GMO GPUクラウド」を通じて、生成AI分野に取り組む企業や研究機関に対し、ワークロード特性に応じて最適なGPUクラウドサービスを選択できる柔軟な計算環境を提供していく方針です。生成AIの学習・推論に強みを持つB300 GPUと、高精度な数値計算に適したH200 GPUを、お客様のユースケースに合わせて柔軟に組み合わせ、最適な環境を提案します。
単なるGPUリソースの提供にとどまらず、お客様の開発目的や利用用途に応じた環境のカスタマイズから運用最適化まで、技術面・コスト面の両面で伴走支援を提供することで、国内AI産業の発展に貢献していくことを目指しています。
まとめ:GPUの特性を理解し、AI開発を次のステージへ
GMOインターネットによるNVIDIA B300 GPUとH200 GPUの性能実証は、AI開発者にとって非常に価値のある情報です。生成AIの進化が加速する中で、GPUの選択はプロジェクトの成否を分ける重要な要素となります。今回の検証結果を参考に、ご自身のAIワークロードに最適なGPUを見つけ、効率的かつ高性能なAIシステム開発を実現してください。GMO GPUクラウドは、これからも日本のAI産業の発展を強力に後押ししていくことでしょう。
AI初心者向け用語解説
-
GPU(Graphics Processing Unit): 本来は画像処理に使われる半導体ですが、並列計算能力が高いため、AIの学習や推論に広く利用されています。
-
大規模言語モデル(LLM): 大量のテキストデータを学習し、人間のような自然な文章を生成したり、質問に答えたりできるAIモデルです。ChatGPTなどが代表的です。
-
ファインチューニング: あらかじめ学習済みの大きなAIモデルを、特定のタスクやデータに合わせてさらに学習させることです。これにより、より専門的な用途に特化したAIモデルを作成できます。
-
LoRA(Low-Rank Adaptation): 大規模言語モデルのファインチューニングを効率的に行うための技術の一つです。モデル全体を再学習するよりも少ない計算量で、高い性能を発揮できます。
-
クロスエントロピー損失: AIモデルの予測がどれくらい「間違っているか」を示す指標の一つです。この値が小さいほど、モデルの予測精度が高いことを意味します。
-
FP4(4ビット浮動小数点演算): データを4ビットという少ない情報量で表現する計算方式です。メモリ使用量を大幅に削減し、処理速度を向上させることで、AIモデルの学習や推論を高速化します。NVIDIA Blackwellアーキテクチャから新たに対応しました。
-
FP8 hybrid(8ビット浮動小数点演算): 8ビットの浮動小数点演算と、より高精度な演算を組み合わせた学習手法です。計算速度と精度のバランスを取ります。
-
FP64(64ビット浮動小数点演算): データを64ビットという非常に多くの情報量で表現する計算方式です。極めて高い精度が求められる科学技術計算などで使用されます。
-
vLLM: 大規模言語モデルの推論を高速化するためのオープンソースライブラリです。効率的なメモリ管理などにより、高いスループットを実現します。
-
vLLM bench throughput: vLLMの性能を測定するためのベンチマークツールで、特に1秒あたりに生成できるトークン数(スループット)を評価します。
-
HPL Benchmark: スーパーコンピュータの性能評価に用いられる国際標準ベンチマークの一つです。大規模な連立一次方程式を解くことで、浮動小数点演算性能を測定します。
-
LINPACK性能: HPL Benchmarkで測定される計算能力で、複雑な数式を正確に解く能力を示します。科学技術計算など、わずかな誤差も許されない分野での性能指標となります。

