
音楽AI開発を加速!Qlean Datasetが「日本語・1話者・音楽テーマトーク音声コーパス」提供開始
AI(人工知能)の進化は目覚ましく、私たちの生活やビジネスに大きな変化をもたらしています。そのAIが賢くなるためには、良質な「学習データ」が不可欠です。特に、音声や言語を扱うAIを開発するには、大量かつ多様な音声データやテキストデータが必要となります。
このたび、Visual Bank株式会社(東京都港区)は、傘下の株式会社アマナイメージズを通じて提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、AI開発を強力に支援する新たなデータセットの提供を開始しました。それが「日本語・1話者・音楽テーマトーク音声コーパスとトランスクリプト」です。
音楽分野に特化した新データセットが登場!

今回提供が始まったこのデータセットは、音楽やアーティスト、楽曲、音楽体験といったテーマに特化し、日本人の話者が一人語り形式で語る日本語音声と、その内容を忠実に書き起こしたトランスクリプト(文字起こしテキスト)を収録しています。
AIが音楽レビューを理解したり、音楽に関する質問に答えたり、あるいはユーザーの好みに合わせた楽曲を推薦したりするような、より高度な機能の開発に役立つことが期待されます。
AI開発を加速する3つの技術:ASR、NLP、LLMをわかりやすく解説
このデータセットは、主に以下の3つのAI技術の開発や評価を目的としています。AI初心者の方にもわかりやすいように、それぞれの技術を簡単に説明します。
ASR(自動音声認識)とは?
ASRとは「Automatic Speech Recognition」の略で、人間が話す音声をコンピューターが文字に変換する技術のことです。例えば、スマートフォンの音声アシスタントに話しかけて文字入力される機能や、会議の議事録を自動で作成するツールなどに活用されています。
音楽テーマトークのような、専門用語や固有名詞が多く含まれる音声でも正確に認識できるAIを開発するには、そのような音声で学習させる必要があります。
NLP(自然言語処理)とは?
NLPとは「Natural Language Processing」の略で、人間が日常的に使う言葉(自然言語)をコンピューターが理解し、処理する技術のことです。例えば、文章の要約、翻訳、感情分析、チャットボットなどがNLPの応用例です。
このデータセットのトランスクリプトは、音楽に関する複雑な表現や文脈を学習させるのに適しており、音楽レビューから要点を抽出したり、特定のアーティストに関する情報を理解したりするAIの開発に貢献します。
LLM(大規模言語モデル)とは?
LLMとは「Large Language Model」の略で、大量のテキストデータを学習することで、人間のように自然な文章を生成したり、質問に答えたりできるAIモデルのことです。ChatGPTなどがその代表例として知られています。
長時間の音声から得られたテキストデータは、LLMがより深い文脈を理解し、一貫性のある長文を生成する能力を高めるのに役立ちます。例えば、音楽に関する深い考察や解説を生成するAIの開発に応用できるでしょう。
データセットの具体的な内容と特長
この「日本語・1話者・音楽テーマトーク音声コーパスとトランスクリプト」は、『AIデータレシピ』というQlean Datasetが提供する機械学習用データセットのラインナップに新しく加わりました。
特長としては、台本による厳密な制御を行わず、話者が自身の言葉で内容を整理しながら語る形式を採用している点が挙げられます。これにより、自然で連続的な発話構造が生まれ、説明的な語りや文脈の持続、語彙の使われ方を含めた、よりリアルな音声・テキストデータとして利用できます。
収録されているテーマは、作品やアーティストへの考察、音楽にまつわる体験談、ジャンルや時代背景に関する解説など、音楽領域に即した話題が中心です。対話ではなく一人語りであるため、長めの入力を前提としたAIの研究・開発用途に特に適しています。
収録データの詳細
このデータセットの具体的な仕様は以下の通りです。
-
データ種別: 音声、テキスト
-
被写体属性: 日本人、20代〜50代の男女
-
データ形式: 音声データ(mp3, wav)、テキストデータ(txt, json, csv)
-
収録時間: 計約210時間(1音声あたり約5分〜60分)
-
音声レート: 44.1kHz / 48kHz
-
対象のシーン: 話者が音楽や音楽に関連するテーマについて連続的に説明・解説するシーン
サンプルデータは以下のリンクから確認できます。
サンプル詳細
実際の利用シーン:多様なユースケース
このデータセットは、アカデミア(研究機関)から産業用途まで、幅広いAI開発シーンでの活用が想定されています。
研究機関(アカデミア)での活用
ドメイン固有の語彙を含む日本語音声認識モデルの検証に役立ちます。音楽、漫画、映画といったカルチャー領域に関する固有名詞や作品名を含む一人話者の連続発話音声を用いて、ASRモデルが説明的・評価的な語りをどの程度安定して認識できるかを検証する研究に利用可能です。
産業用途での活用
-
レビュー・解説型音声コンテンツを想定した言語理解モデルの評価
作品レビューやアーティスト解説など、個人の視点で語られる音声コンテンツを前提に、音声認識後のテキスト理解、要点抽出、要約生成といったNLP/LLM機能の検証に利用できます。 -
音声入力型レコメンド・検索機能の検証
発話内に含まれる作品名や人物名、評価表現をもとに、関連コンテンツの抽出や分類を行う音声入力型検索・推薦機能の検証データとして利用できます。
その他の実用的なニーズ
カルチャー系音声コンテンツの字幕生成や要約検証にも応用できます。映画、漫画、音楽に関する解説音声を想定し、字幕生成や概要文生成といった、教育・情報提供用途の音声処理機能の検証に利用可能です。
「Qlean Dataset」が提供するAI開発支援
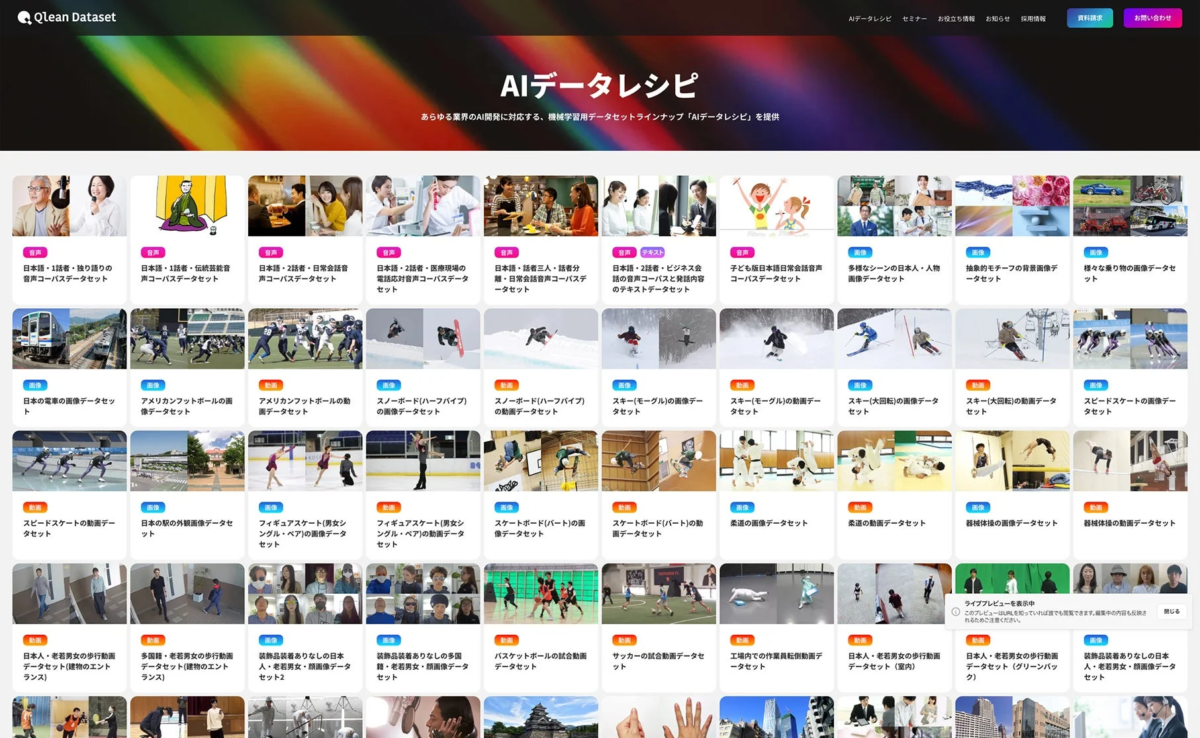
「Qlean Dataset」は、Visual Bank傘下のアマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。画像、動画、音声、3D、テキストなど、多様な形式のデータに対応しており、研究用途から商用開発まで、安全に利用できる環境を整備しています。
『AIデータレシピ』とは?
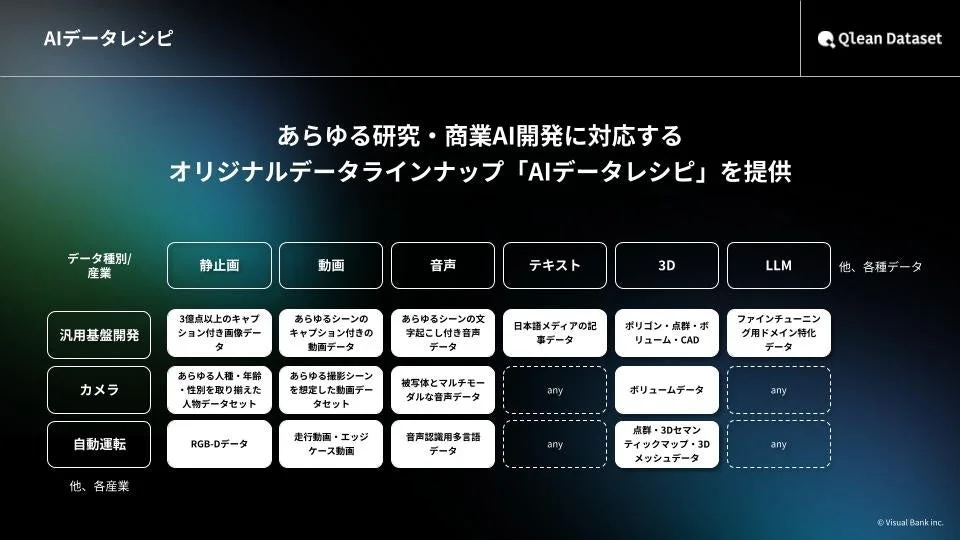
『AIデータレシピ』は、Qlean Datasetが提供する機械学習用データセットのラインナップです。株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータが継続的に拡充されています。
AI開発現場におけるデータ収集や整備の負荷を軽減し、権利がクリアで法的リスクのないAI開発環境の構築を支援することを目指しています。
Qlean Datasetの強み

Qlean Datasetは、AI開発に必要なデータセット(データ素材、アノテーション、キャプションなど)を、商用利用可能なオリジナルデータラインナップ「AIデータレシピ」として提供しています。その主な強みは以下の通りです。
- 安価かつスピーディーなデータ提供
初期投資を抑えつつ、必要なデータを迅速に調達できます。 - 多様なデータ形式や構成にカスタマイズ対応
画像、動画、音声、3D、テキストなど、幅広いデータ形式に対応し、柔軟なカスタマイズが可能です。 - 『AIデータレシピ』にないデータも拡充
独自性の高いデータや特定の要件に応じたデータも、準備・提供に対応しています。 - 権利処理済みで商用利用も安心
著作権や肖像権などの権利処理が完了しており、研究用途から商用利用まで安心して利用できます。AI倫理や法制度の最新状況にも対応しています。

これらの強みにより、AI開発者はデータの準備にかかる手間を大幅に削減し、より本質的なAIモデルの開発に注力できるようになります。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。
同社は、漫画家の創作活動をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持っています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
Visual Bank企業URL
アマナイメージズ企業URL
まとめ:音楽とAIの未来を拓くデータセット
今回Qlean Datasetが提供を開始した「日本語・1話者・音楽テーマトーク音声コーパスとトランスクリプト」は、音楽という魅力的な分野におけるAI開発を大きく前進させる可能性を秘めています。
ASR、NLP、LLMといった最新のAI技術を活用し、音楽コンテンツの新たな楽しみ方や、よりパーソナルな音楽体験の提供に貢献するAIが今後登場することでしょう。
AI開発におけるデータセットの重要性は増すばかりです。Qlean Datasetのような高品質で権利処理済みのデータは、開発者の負担を軽減し、安全かつ効率的なAI開発を後押しします。音楽とAIの融合がどのような新しい価値を生み出すのか、今後の展開に注目が集まります。

