
AI開発を加速!Qlean Datasetが「日本語・2話者・ビジネス会話の音声コーパスとテキストデータセット」を提供開始
AI技術の進化は目覚ましく、私たちのビジネスや生活に大きな変革をもたらしています。しかし、AIを開発するためには、膨大で質の高い学習データが不可欠です。特に、日本語の自然な会話を理解し、適切に処理できるAIを構築するには、実社会の多様な状況を反映したデータが求められます。
このような背景の中、Visual Bank株式会社が展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、AI開発者にとって非常に価値のある新たなデータセットの提供を開始しました。

「日本語・2話者・ビジネス会話の音声コーパスとテキストデータセット」とは?
今回提供が始まったのは、「日本語・2話者・ビジネス会話の音声コーパスと発話内容のテキストデータセット」です。これは、日本語を話す2人の人物がビジネスシーンで交わす会話を数百時間規模で収録し、その音声データに加えて、発話内容のテキスト、話者を区別する情報、そして発話の開始・終了時刻(タイムスタンプ)を詳細に付与したものです。
データセットの具体的な内容
このデータセットは、以下の要素で構成されています。
-
データ種別: 音声データとテキストデータ
-
被写体属性: 日本人男女の声
-
データ形式: 音声データはWAV形式、テキストデータはTXT形式
-
収録時間: 数百時間にも及ぶ膨大な量
-
対象のシーン: 商談、SaaS(ソフトウェア・アズ・ア・サービス)の問い合わせ対応、架電対応など、実際のビジネス環境における多様な会話が含まれています。
-
テキスト書き起こし構成: 各発話には、行番号、開始時間、終了時間、話者区分、そして発話内容が細かく付与されています。
このデータセットは、研究目的はもちろん、商用利用も可能であり、日本語の音声認識(ASR)、会話理解、要約生成AI、さらには顧客体験(CX)解析AIや会話型大規模言語モデル(LLM)の学習データとして幅広く活用できます。
サンプル詳細はこちらで確認できます。
https://qleandataset.visual-bank.co.jp/lineup/pn-013
このデータセットがAI開発にもたらす価値
この「日本語・2話者・ビジネス会話の音声コーパスとテキストデータセット」は、多岐にわたるAIアプリケーションの開発に貢献します。AI初心者の方にも分かりやすく、具体的なユースケースを見ていきましょう。

音声認識・話者分離AIの精度向上
私たちがスマートフォンに話しかけたり、会議の議事録を自動で作成したりする際に使われるのが「音声認識(ASR)」技術です。このデータセットには、オンライン会議や対面会話など、様々な環境で収録された音声が含まれています。ノイズが多い環境や、複数の人が同時に話す「被り発話」にも対応しているため、より実用的な音声認識AIや、誰がいつ話したかを区別する「話者分離モデル」の性能を大きく向上させることができます。これにより、リアルタイムで正確な議事録を作成するAIの開発も期待できます。
会話理解・要約生成AIのトレーニング
長い会議の議事録を自動で要約したり、カスタマーサポートの会話から重要なポイントを抽出したりするAIは、私たちの業務効率を飛躍的に向上させます。このデータセットは、開始・終了時刻や話者区分が精密に付与されたテキストデータを持っているため、長時間の会話の中から要点を抽出・要約するAIや、次にどのような発言が来るかを予測する「次発話予測型生成AIモデル」の学習データとして非常に適しています。
顧客体験(CX)・感情音声認識AIの開発
顧客満足度を高めるためには、顧客の声に耳を傾け、その感情を理解することが重要です。このデータセットには、声のトーンや応答の間合いなど、感情的なニュアンスを含む音声データが豊富に含まれています。これにより、顧客の満足度や対応品質を解析するCX向けAIモデル、コールセンターでのオペレーターの対応を自動評価するAIなどの開発に役立てることができます。
商談解析・セールスインテリジェンスAIの研究
営業活動において、商談の内容を分析し、成功パターンを見つけることは売上向上に直結します。このデータセットは、営業担当者と顧客の商談や、職業面談のような実務的な対話を網羅しています。発話パターンや相手の話を聞く姿勢(傾聴姿勢)などを数値化し、商談の質を解析するAIや、営業担当者のパフォーマンス向上を支援する「セールスコーチングAI」の基礎データとして利用できます。
コンタクトセンター自動応対AI・FAQ生成AIの構築
多くの企業で導入が進むチャットボットや音声応答システムは、顧客からの問い合わせに迅速に対応するために不可欠です。このデータセットには、カスタマーサポートや問い合わせ対応における実際の音声が含まれています。これにより、よくある質問(FAQ)を自動で生成するAIや、音声で応答するチャットボットの会話をより自然で効果的なものにするための「会話チューニングデータ」として活用できます。
音声UX・会話体験デザインの研究開発
AIアシスタントやスマートスピーカーなど、音声で操作するデバイスが普及する中で、より自然で快適な会話体験を提供することが求められています。このデータセットに含まれる自然な会話のテンポや相槌の表現は、AIアシスタントやスマートスピーカーなどの「音声UI/UX(ユーザーインターフェース/ユーザーエクスペリエンス)」設計において、人間とAIがより自然に対話するための学習に最適です。
感情変化検知AIによる“体験の質”評価
会話中の声のピッチ(音の高さ)、間合い、テンションの変化を分析することで、話者の心理状態の変化や満足度を推定するAIを研究できます。これは、顧客の体験を定量的に評価するCX定量化AIや、接客トレーニングAIへの応用が期待されます。
日本語LLM/マルチモーダル生成AIの会話学習
近年注目される「大規模言語モデル(LLM)」は、テキストだけでなく音声や画像など複数の情報を組み合わせて処理する「マルチモーダルAI」へと進化しています。このデータセットは、音声とテキストがペアになった構造を持つため、マルチモーダルLLMが音声を理解し、より自然な日本語での対話を生成するための学習を強化します。自然な日本語会話を再現する生成AIや、ボイスチャットLLMの研究用途にも適しています。
Qlean Datasetの特長:データ調達の課題を解決
Qlean Datasetは、AI開発現場が直面するデータ収集・整備の負担を軽減し、開発を加速するための独自の強みを持っています。

安心して利用できる権利処理済みデータ
AI開発において、データの著作権や肖像権、プライバシーポリシーへの対応は非常に重要です。Qlean Datasetが提供するデータセットは、すべての被写体からデータ取得およびAI開発への利用に関する同意書を取得しており、各国のプライバシーポリシーにも対応しています。これにより、研究・商用利用を問わず、安心してデータを利用することができます。
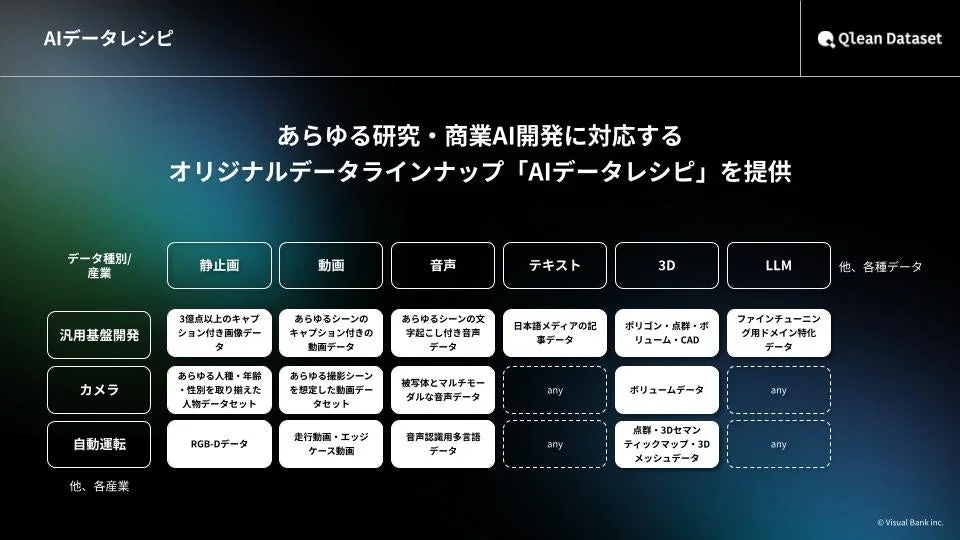
「AIデータレシピ」による柔軟なデータ提供
Qlean Datasetの「AIデータレシピ」は、商用利用可能なオリジナルデータラインナップです。用途や必要な精度、納期に応じて、すぐに使えるデータ素材を柔軟に組み合わせられるのが特長です。一部アノテーション(タグ付けや注釈付け)済みのデータや、まだアノテーションが付与されていないデータ、さらには個別の要件に応じた構成変更や拡張にも対応しています。これにより、初期投資を抑えつつ、スピーディーにデータ調達を行うことが可能です。
Qlean Datasetのサービスサイトはこちらです。
https://qleandataset.visual-bank.co.jp/
個別要件への対応力
「AIデータレシピ」のラインナップにない、独自性の高いデータセットが必要な場合でも、Qlean Datasetは個別要件に従った作成・構築が可能です。これにより、特定のニーズに最適化されたデータセットを提供し、AI開発の可能性を広げます。
データに関するお問い合わせはこちらのフォームから行えます。
https://qleandataset.visual-bank.co.jp/contact
Visual Bank株式会社とQlean Datasetについて
Qlean Datasetは、Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之)の傘下である株式会社アマナイメージズを通じて展開されているAI学習用データソリューションです。
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家の「もっと描きたい!」をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持つなど、多岐にわたる事業を展開しています。
同社は、国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
-
Visual Bank株式会社 企業URL:https://visual-bank.co.jp/
-
株式会社アマナイメージズ 企業URL:https://amanaimages.com/about/
AI開発を支えるデータパートナーシップ
Visual Bank株式会社は、AI開発を支える多様なデータ提供体制を強化するため、音声・画像・動画・3Dなどの各領域でデータパートナーシップの拡大を進めています。信頼できるパートナーとの連携を通じて、AI時代に対応した知的財産保護とデータの価値最大化の両立を目指しており、研究機関・企業・クリエイターとの協力を積極的に求めています。
データパートナーシップに関する詳細はこちらです。
https://qleandataset.visual-bank.co.jp/partner
パートナーシップに関するお問い合わせはこちらから行えます。
https://qleandataset.visual-bank.co.jp/contact-partner
まとめ
Qlean Datasetが提供を開始した「日本語・2話者・ビジネス会話の音声コーパスと発話内容のテキストデータセット」は、日本語AI開発における重要な一歩となるでしょう。高精度な音声認識や会話理解、感情分析、そして日本語LLMのトレーニングまで、幅広いAIアプリケーションの可能性を広げます。
AI開発の現場において、質の高いデータは成功の鍵となります。この新しいデータセットは、その鍵を握る存在として、多くの開発者の皆様にとって強力な味方となるはずです。AI開発に携わる企業や研究機関は、この機会にQlean Datasetの活用を検討してみてはいかがでしょうか。

