
AI(人工知能)の進化は目覚ましく、私たちの生活やビジネスに革新をもたらしています。特に、音声認識(ASR)や大規模言語モデル(LLM)といった音声・言語系のAI技術は、スマートスピーカー、自動翻訳、チャットボットなど、さまざまな分野でその存在感を増しています。これらのAIがより賢く、より自然に人間とコミュニケーションを取るためには、高品質な「学習データ」が不可欠です。
そんな中、AI学習用データソリューション「Qlean Dataset(キュリンデータセット)」が、新たに「日本語・1話者・台本朗読音声コーパスとトランスクリプト」の提供を開始しました。このデータセットは、日本語の音声・言語AI開発を強力に支援し、AIのさらなる発展に貢献すると期待されています。

新たな日本語音声データセットの概要
Qlean Datasetが提供を開始した「日本語・1話者・台本朗読音声コーパスとトランスクリプト」は、AIが日本語の音声とテキストの関係性を正確に学習するための、非常に整理されたデータセットです。
「1話者・台本朗読」とは?
このデータセットの大きな特徴は、「1話者」が「台本を朗読」している点にあります。具体的な内容としては、日本人男性話者が事前に用意された日本語の台本を読み上げた音声と、その発話内容を一字一句忠実に書き起こした「トランスクリプト」(テキストデータ)がセットになっています。
通常の会話では、人は「えー」「あのー」といった「言い淀み」や、話の途中で話題が逸れてしまう「話題の逸脱」がよく起こります。しかし、このデータセットは台本に基づいた朗読形式であるため、そうした自然発話特有の「乱れ」が極力抑えられています。これにより、音声とテキストの対応関係が非常に明確になり、AIが「この音声は、このテキストを意味する」という学習を効率的かつ正確に行うことが可能になります。
収録内容とデータ形式
データセットには、以下の情報が含まれています。
-
データ種別: 音声データ、テキストデータ
-
被写体属性: 日本人、男性
-
データ形式:
-
音声データ:mp3形式
-
テキストデータ:txt, json, csv形式
-
-
音声レート: 44.1kHz / 48kHz
多様な形式で提供されるため、開発者は自身のAIモデルやシステムに合わせて最適な形式を選択できます。また、44.1kHz / 48kHzという高音質な音声レートは、より繊細な音声特徴をAIに学習させる上で有利に働きます。
サンプル詳細については、以下のリンクから確認できます。
なぜこのデータセットがAI開発に重要なのか?
音声・言語系のAI、例えばASR(自動音声認識)、NLP(自然言語処理)、LLM(大規模言語モデル)を開発する際には、膨大で高品質な学習データが不可欠です。しかし、そのようなデータを自社で収集・整備するには、多大な時間、コスト、そして専門知識が必要となります。さらに、データの権利処理や利用条件の整理も大きな課題となります。
ASR(自動音声認識)とは?
ASRは、人間の音声をテキストに変換する技術です。スマートフォンの音声アシスタントや議事録作成ツールなどに利用されています。ASRの精度を高めるには、さまざまな話し方、環境で録音された音声と、それに対応する正確なテキストデータのペアを大量に学習させる必要があります。
NLP(自然言語処理)とは?
NLPは、人間が話したり書いたりする「自然言語」をコンピューターが理解し、処理する技術です。翻訳、要約、感情分析などに使われます。NLPモデルは、テキストデータから言語の構造や意味を学びます。
LLM(大規模言語モデル)とは?
LLMは、大量のテキストデータを学習することで、人間のような文章を生成したり、質問に答えたりする能力を持つAIモデルです。ChatGPTなどがその代表例です。LLMは、音声認識と組み合わせることで、音声での対話システムなどに応用されます。
高品質な学習データが解決する課題
Qlean Datasetが提供するこのデータセットは、以下のような点でAI開発の課題を解決します。
- 音声とテキストの明確な対応関係: 台本朗読形式であるため、音声とテキストのズレが少なく、AIが正確な学習を行うことができます。これは、特にASRモデルの学習や評価において非常に重要な要素です。
- ノイズの少ないデータ: 自然発話特有の言い直しや話題の逸脱がないため、AIはより「クリーン」な言語パターンを学習でき、汎用性の高いモデル構築に繋がります。
- 権利処理済みで安心: 研究用途だけでなく、商用利用を前提としたAI開発においても、著作権や肖像権といった権利処理が適切に行われているため、安心して利用できます。これにより、開発者は法的リスクを気にすることなく、開発に集中できます。
- データ収集・整備の負担軽減: 企業が独自でこのような高品質なデータセットをゼロから用意するのは非常に困難です。Qlean Datasetの利用により、この負担が大幅に軽減され、AI開発のスピードアップに貢献します。
具体的な活用事例
このデータセットは、AI開発の様々な段階で活用が期待されています。
研究用途:日本語ASRモデルの基礎評価
AIの研究開発を行う方々にとって、このデータセットは日本語ASRモデルの基礎的な性能を評価するのに最適です。単一話者による台本朗読音声は、音声とテキストの対応関係が非常に明確なため、ASRモデルがどの程度正確に音声をテキストに変換できるか、どのような種類の誤りを犯しやすいかなどを詳細に分析するのに役立ちます。例えば、新しいASRアルゴリズムを開発した際に、このデータセットを用いて客観的な評価を行うことができます。
産業用途:音声入力を含むLLM・音声言語処理パイプラインの検証
ビジネスの現場では、音声入力に対応したシステムや、音声認識結果を基に動作する大規模言語モデル(LLM)の導入が進んでいます。このデータセットは、そうした複雑な「音声言語処理パイプライン」の検証に非常に有効です。
例えば、顧客からの音声問い合わせをAIがテキストに変換し、そのテキストをLLMが分析して自動応答するシステムを開発する場合を考えてみましょう。このデータセットを使うことで、音声からテキストへの変換精度がLLMの応答にどう影響するか、といった一連の処理フローを、正確な日本語音声とトランスクリプトのペアを使って効率的にテストできます。これにより、システムの信頼性と性能向上に貢献します。
その他実需要:音声言語処理システムの学習・評価用データ
教育機関でのAI学習や、既存の音声認識モデルの動作確認、性能比較など、幅広い実需要にも対応します。例えば、音声認識の仕組みを学ぶ学生が、このデータセットを用いて実践的な演習を行うことができます。また、複数の音声認識エンジンを比較検討する企業が、統一されたデータセットで公平な評価を行う際にも役立ちます。
Qlean Dataset(キュリンデータセット)について
Qlean Datasetは、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。AI開発の現場で直面するデータに関する課題を解決するために、高品質で権利処理済みのデータセットを提供しています。
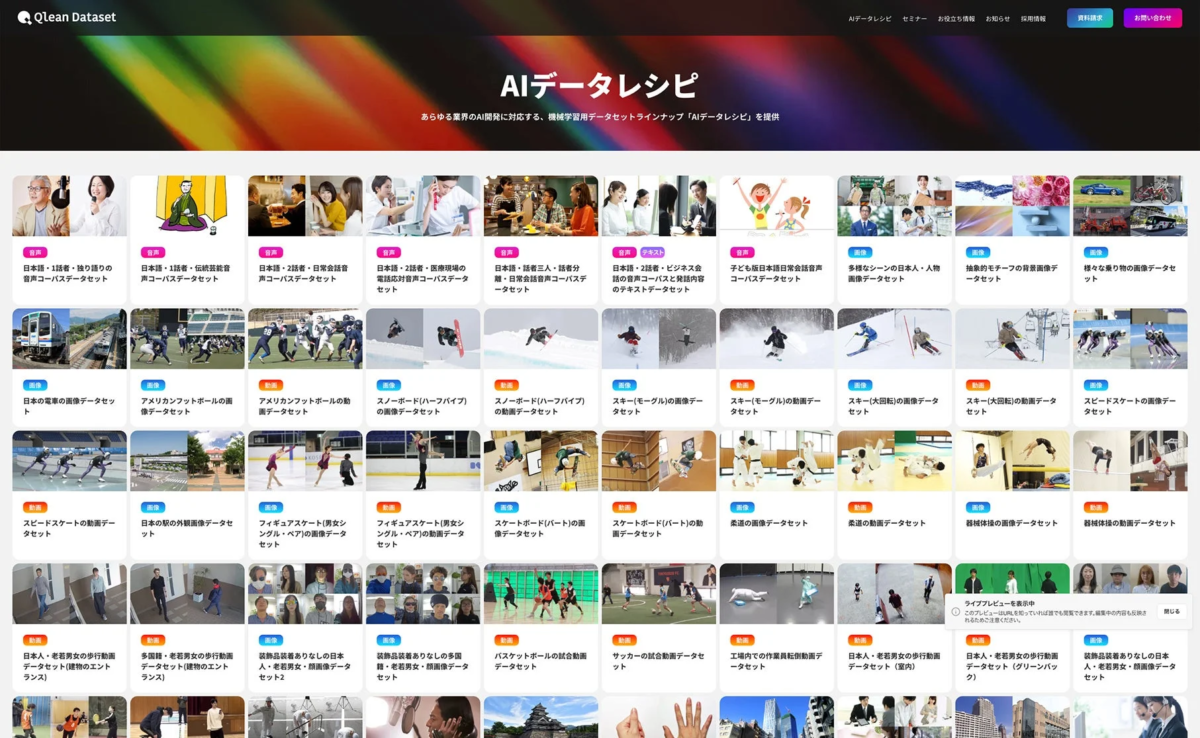
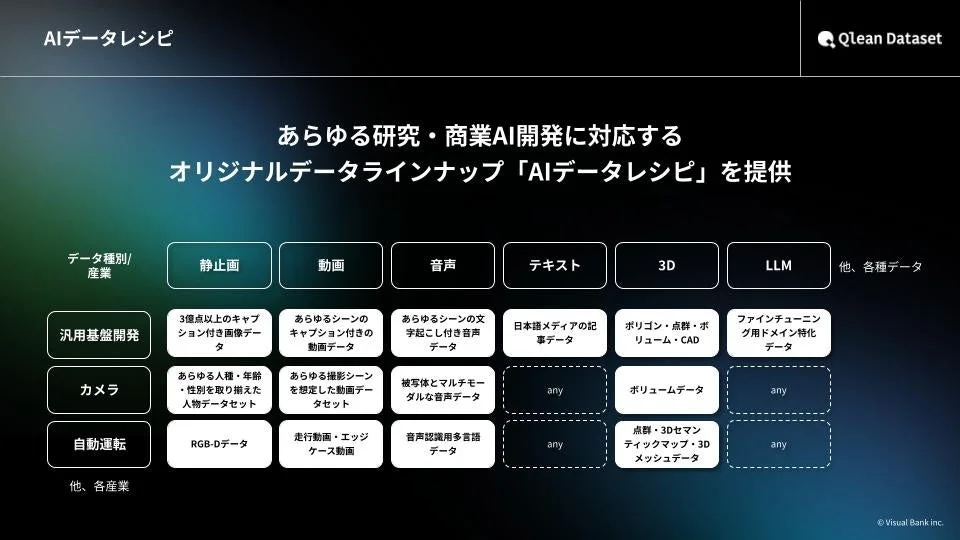
AIデータレシピという豊富なラインナップ
Qlean Datasetは、「AIデータレシピ」という名称で、多岐にわたる機械学習用データセットのラインナップを展開しています。今回の日本語音声データセットもその一つです。AIデータレシピでは、画像、動画、音声、3D、テキストなど、さまざまな形式のデータを取り扱っており、あらゆる業界のAI開発ニーズに対応しています。
データパートナーとして、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といった企業と協業し、業界特化型や最新トレンドに即したデータセットを継続的に拡充している点も特徴です。
Qlean Datasetの提供価値と強み
Qlean Datasetは、AI開発に必要な学習データ素材、アノテーション(データへのタグ付けや注釈付け)、キャプションデータなどを提供することで、開発現場のデータ収集・整備の負荷を軽減します。その強みは以下の通りです。

- 安価かつスピーディーなデータ提供: 初期投資を抑えつつ、必要なデータを迅速に調達できます。
- 多様なデータ形式や構成にカスタマイズ: 画像、動画、音声、3D、テキストなど、AI開発のあらゆるニーズに対応できるよう、データ形式や構成を柔軟にカスタマイズできます。
- AIデータレシピにないデータは要件に応じて拡充: 既存のデータセットにない特殊なデータが必要な場合でも、個別の要件に合わせて独自にデータ構築を行うことが可能です。
- 権利処理済みで商用利用も安心: 著作権や肖像権などの権利クリアランスが徹底されており、研究用途はもちろん、商用利用においても法的リスクを気にすることなく安全に利用できます。AI倫理や法制度の最新状況にも対応しているため、安心して開発を進められます。

Qlean Datasetの詳細やAIデータレシピのラインナップは、以下の公式サイトで確認できます。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、漫画家の創作活動をサポートするAI補助ツール『THE PEN』や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
まとめ
AI技術の進化は、高品質な学習データの存在なしには語れません。Qlean Datasetが提供を開始した「日本語・1話者・台本朗読音声コーパスとトランスクリプト」は、ASRやLLMといった音声・言語系のAI開発において、その精度と効率を飛躍的に向上させる可能性を秘めています。権利処理済みの安全なデータが、研究者や開発者の負担を軽減し、より創造的なAIソリューションの創出に貢献することでしょう。
この新しいデータセットが、日本のAI開発をさらに加速させ、私たちの未来をより豊かにする技術革新へと繋がっていくことに期待が寄せられます。

