

AI開発の新たな一歩:Qlean Datasetがビジネス・自己啓発朗読音声データセットを提供開始
近年、AI(人工知能)技術の進化は目覚ましく、私たちの生活やビジネスに大きな変革をもたらしています。特に「大規模言語モデル(LLM)」や「自動音声認識(ASR)」といった分野は、日々新しい技術が生まれ、その応用範囲を広げています。しかし、これらのAIをさらに賢く、そして実用的にするためには、大量かつ質の高い「学習用データ」が不可欠です。特に日本語のような複雑な言語においては、その重要性が一層高まります。
このような背景の中、Visual Bank株式会社(以下、Visual Bank)が傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、AI開発現場の大きな課題に応える新たなデータセットの提供を開始しました。それが「日本語・1話者・ビジネス・自己啓発・趣味実用テーマの朗読音声コーパスとトランスクリプト」です。この新しいデータセットは、日本語の音声理解や言語表現を伴うAIモデルの開発を強力に支援し、LLMや音声言語AIの可能性をさらに広げることでしょう。
ビジネス・自己啓発分野に特化した高品質日本語音声データとは?
Qlean Datasetが今回提供を開始したデータセットは、ビジネス書、自己啓発書、趣味・実用書といった分野の文章を、一人の日本人話者が朗読した音声と、その内容を正確に文字起こしした「トランスクリプト」で構成されています。ここで重要なのは、単なる文章の読み上げではないという点です。このデータセットには、業務の解説、考え方の整理、手順の説明など、知識や概念を言語化する文脈が多く含まれています。これにより、AIは単語や文を認識するだけでなく、「内容を理解した上で発話されている」という、より高度な言語表現を学習できるようになります。
なぜこのデータセットがAI開発に重要なのか
AIが人間の言葉を深く理解するためには、言葉の表面的な意味だけでなく、その背後にある文脈や意図を捉える必要があります。特に、ビジネスや自己啓発といった分野では、論理的な思考や複雑な概念が文章中に多く登場します。このデータセットは、そうした「知識理解・言語表現を伴う音声」を豊富に収録しているため、AIがより高度な推論や要約、応答生成を行うための基盤となります。
また、朗読形式であるため、話者の発話が安定しており、音声と文字起こし(トランスクリプト)の対応関係が非常に明確です。これにより、AIが音声とテキストの関連性を正確に学習しやすくなります。さらに、長文構造や論理的な文章展開を含む音声が収録されているため、短文中心のデータでは難しかった、文脈理解や情報整理を伴う音声処理の検証にも活用できます。これは、例えば会議の議事録作成AIや、複雑なマニュアルを読み上げて説明するAIなど、実用的なAIの開発において非常に大きなメリットとなります。
データセットの概要
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 日本人 |
| データ形式 | 音声データ:mp3 |
| 収録時間 | 1音声30秒〜160分 |
| 音声レート | 44.1kHz / 48kHz |
| 対象のシーン | ・ビジネス書や自己啓発書、実用書の文章を一人の話者が朗読するシーン ・手順説明や考え方を整理しながら読み上げる朗読シーン |
このデータセットのサンプルは、以下のリンクから詳細を確認できます。
AI開発現場を変革するユースケース
この新しいデータセットは、AIの研究開発と産業応用において、多岐にわたる活用が期待されています。AI初心者の皆様にもわかりやすく、具体的な活用シーンをご紹介します。
【研究用途】
-
音声入力を伴う日本語言語理解モデルの検証
-
説明: AIに日本語音声をインプットし、その内容を理解させ、要約したり質問に答えたりする「音声言語モデル」の開発において活用できます。ビジネス文書や実用文書を題材としているため、AIが現実世界のビジネスシーンで求められるような複雑な情報をどれだけ正確に理解し、推論できるかを検証するのに役立ちます。
-
メリット: これまで難しかった、専門性の高い日本語の音声データを基にしたAIの理解度向上や、より自然で適切な応答生成能力の検証が可能になります。
-
-
音声とテキストの対応関係に基づくマルチモーダル研究
-
説明: 「マルチモーダル」とは、音声とテキストのように複数の異なる種類のデータを組み合わせてAIを学習させる研究分野です。このデータセットは、同じ内容の音声と文字起こし(トランスクリプト)がセットになっているため、音声の表現(話し方やイントネーション)が文章構造や言語理解にどのような影響を与えるかを分析する研究に利用できます。
-
メリット: 音声の非言語的な情報(声のトーン、話すスピードなど)と言語的な情報(単語の意味、文法など)を統合的に理解するAIの開発につながり、より人間らしいコミュニケーションが可能なAIの実現に貢献します。
-
【産業用途】
-
音声対応型業務支援AIの基盤モデル検証
-
説明: 音声入力によって業務知識や手順説明を理解し、処理するAIプロダクト、例えばスマートスピーカー型の業務アシスタントや、音声で操作するマニュアルシステムなどの開発に役立ちます。ビジネスや実用分野の日本語音声データを用いることで、AIが実際の業務環境でどれだけ正確に音声を認識し、内容を理解できるかを評価できます。
-
メリット: 業務効率化を図るAIツールの開発において、実務に即した高い認識・理解性能を持つ基盤モデルを構築できるようになります。これにより、現場での誤認識を減らし、よりスムーズな業務遂行を支援するAIの実現が期待されます。
-
-
音声入力を前提としたLLMファインチューニング
-
説明: 大規模言語モデル(LLM)は、テキストデータを学習して文章を生成したり、質問に答えたりするAIです。このデータセットは、音声から得られた日本語テキストを基点としてLLMをさらに調整(ファインチューニング)する際に利用できます。特に、説明文や論理的な展開を含むデータが豊富であるため、要約生成や回答生成の品質を検証し、向上させることが可能です。
-
メリット: 音声入力された複雑な指示や質問に対して、より的確で論理的な回答を生成できるLLMの開発に貢献します。これにより、コールセンターの自動応答システムや、企業の知識ベースからの情報検索AIなど、多岐にわたるビジネスアプリケーションでの活用が見込まれます。
-
AI学習用データソリューション「Qlean Dataset」の全貌
Qlean Datasetは、AI開発に必要な「学習用データ」を提供する専門ソリューションです。Visual Bank傘下の株式会社アマナイメージズが提供しており、AI研究から商用AI開発まで、あらゆるフェーズで安全かつ高品質なデータを提供することを目指しています。
「AIデータレシピ」とは
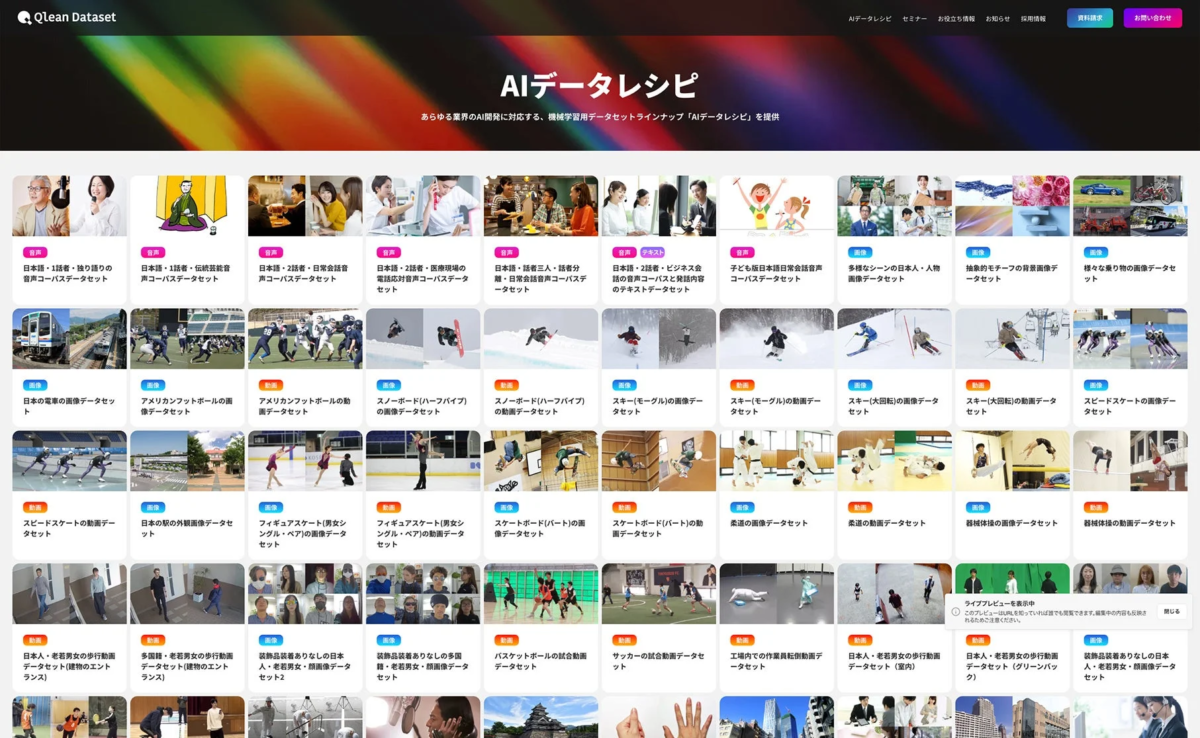
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多様な形式のデータを扱っており、これらを「AIデータレシピ」というオリジナルラインナップとして提供しています。この「AIデータレシピ」には、今回発表された朗読音声コーパス以外にも、様々な業界や用途に特化したデータセットが豊富に用意されています。例えば、日本の電車画像データや、医療現場の会話音声データなど、多岐にわたるニーズに応えるデータが継続的に拡充されています。
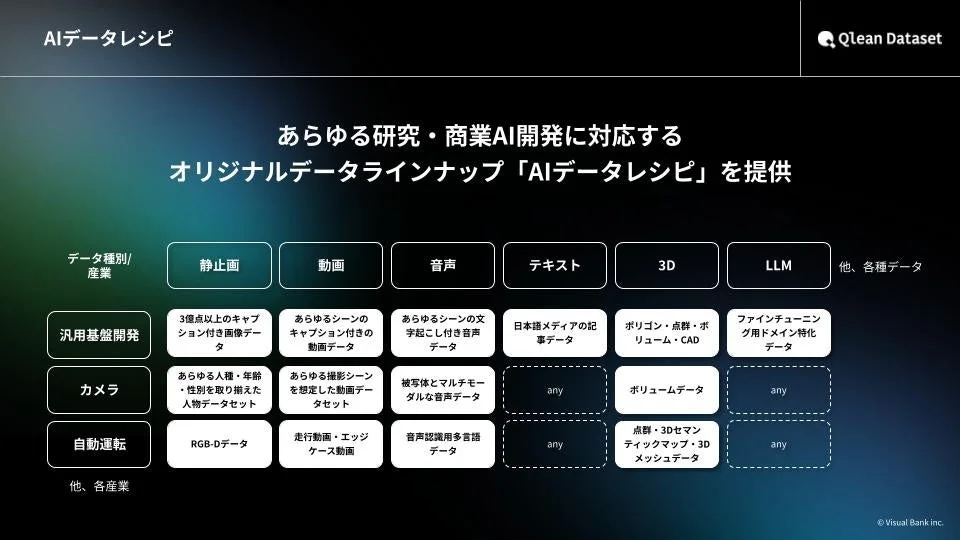
AI開発においてデータの収集や整備は非常に手間とコストがかかる作業ですが、Qlean Datasetはこうした開発現場の負担を軽減し、著作権や肖像権などの「権利処理済み」のデータを安心して利用できる環境を提供しています。これにより、開発者は法的リスクを心配することなく、AIモデルの学習と実装に集中できます。

Qlean Datasetの具体的な強み
Qlean Datasetは、AI開発を強力にサポートするために、以下の4つの主要な強みを持っています。
-
安価かつスピーディーなデータ提供が可能
- AI開発を始める際の初期投資を抑えつつ、必要なデータを迅速に調達できます。これにより、開発サイクルを短縮し、市場投入までの時間を短縮することが可能です。
-
多様なデータ形式や構成にカスタマイズ
- 画像、動画、音声、3D、テキストといった多岐にわたるデータ形式に対応しており、AI開発の特定の要件に合わせてデータを柔軟にカスタマイズできます。
-
AIデータレシピにないデータは要件に応じて拡充
- もし既存の「AIデータレシピ」にない、独自性の高いデータが必要な場合でも、顧客の具体的な要件に応じて、データの準備や提供に対応しています。カスタム撮影や収録、収集による独自のデータ構築も可能です。
-
権利処理済みで商用利用も安心
- すべてのデータセットは、著作権や肖像権などの権利クリアランスが徹底されており、研究用途はもちろん、商用AI開発においても安心して利用できます。AI倫理や法制度の最新状況にも対応しているため、将来的なリスクを低減できます。

Qlean Datasetの詳細については、以下のサイトをご覧ください。
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社のAI開発支援への貢献
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
Qlean Datasetの提供を通じて、Visual BankはAI開発現場における基盤モデルの学習および実装フェーズを支援し、実務文脈に即した高品質な日本語音声・テキストデータの提供に注力しています。これは、日本国内のAI技術の発展にとって非常に重要な役割を担っていると言えるでしょう。
Visual Bankは、Qlean Datasetを提供する株式会社アマナイメージズを100%子会社に持つほか、漫画家の創作活動をサポートするAI補助ツール『THE PEN』なども展開しており、多角的にAIとデータの可能性を追求しています。
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/
まとめ:日本語AIの未来を拓くデータ基盤
Qlean Datasetが提供を開始した「日本語・1話者・ビジネス・自己啓発・趣味実用テーマの朗読音声コーパスとトランスクリプト」は、日本語のLLMや音声認識AIの精度向上、そしてより高度な言語理解能力の獲得に不可欠なデータ基盤となるでしょう。知識理解や論理的な文章展開を伴う高品質な音声データは、これまでAI開発者が直面してきた日本語データの不足という課題を解決し、AIがより実用的で、私たちの生活やビジネスに密接に関わる存在となるための道を開きます。
AI初心者の方々にとっても、このような高品質な学習用データが提供されることで、AI開発のハードルが下がり、新しいアイデアの実現が加速されることが期待されます。Visual BankとQlean Datasetの取り組みは、これからの日本語AI技術の発展において、中心的な役割を果たすことになるでしょう。今後も、Qlean Datasetがどのような新たなデータを提供し、AI技術の可能性をどこまで広げていくのか、その動向に注目が集まります。

