Qlean Datasetが提供開始!日本語・児童書の朗読音声データセットでAI開発を加速させる方法
AI(人工知能)の技術は、私たちの生活のさまざまな場面で活用され始めています。スマートフォンの音声アシスタント、自動翻訳、おすすめ商品の表示など、AIが裏側で動いている例は枚挙にいとまがありません。しかし、これらのAIが賢く機能するためには、質の高い「学習データ」が不可欠です。AIは、与えられたデータを分析し、そこからパターンを学び取ることで、初めて特定のタスクをこなせるようになります。例えるなら、人間が教科書や参考書から学ぶのと同じように、AIもデータから知識を得るのです。
AIの性能は、この学習データの「質」と「量」に大きく左右されます。データが不正確だったり、偏っていたりすると、AIも間違った判断をしたり、特定の状況にしか対応できない「偏った」AIになってしまう可能性があります。そのため、AI開発においては、いかに高品質で多様なデータを効率的に集め、整備するかが重要な課題となっています。
このような背景の中で、AI学習用データソリューション「Qlean Dataset(キュリンデータセット)」が、AI開発を強力にサポートする新たなデータセットの提供を開始しました。それが「日本語・1話者・児童書の朗読音声データセット」です。このデータセットが、これからの音声・言語系AI開発にどのような可能性をもたらすのか、AI初心者の方にもわかりやすく詳しくご紹介します。
Qlean Datasetとは?AI学習用データソリューションの役割
Qlean Datasetは、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。AI開発の現場では、画像、動画、音声、テキスト、3Dデータなど、多種多様なデータが必要とされますが、これらのデータを自社で収集・整備するのは非常に手間とコストがかかります。また、データの著作権や肖像権といった「権利処理」も複雑で、これらをクリアしないと商用利用で法的なリスクを抱えることになりかねません。
Qlean Datasetは、これらの課題を解決するために、研究開発から商用展開まで安心して利用できる、権利処理済みの高品質な学習データをワンストップで提供しています。これにより、AI開発者はデータの準備に時間を取られることなく、本来のAIモデル開発に集中できるようになります。
新登場!「日本語・1話者・児童書朗読音声データセット」の詳細
今回Qlean Datasetが新たに提供を開始したのが、「日本語・1話者・児童書・童話・絵本・昔話テーマの朗読音声コーパスとトランスクリプト」です。少し長い名前ですが、その内容を詳しく見ていきましょう。
このデータセットは、子ども向けの物語(児童書、童話、絵本、昔話など)を、一人の日本人話者が朗読した音声データと、その朗読内容を正確に文字に起こした「トランスクリプト」で構成されています。
「1話者」と「自然な朗読発話」の重要性
なぜ「1話者」であることが重要なのでしょうか?AIが音声を認識する際、話者の声質や話し方の癖は、認識精度に大きな影響を与えます。単一の話者が長時間にわたって朗読しているデータは、特定の話者の特徴を深く学習するのに適しており、音声認識モデルの検証において、話者によるバラつきを排除し、純粋に「発話内容」や「文脈」に起因する認識エラーを分析しやすくなります。
また、このデータセットの朗読音声は、単に文字を読み上げるだけでなく、登場人物の心情や物語の展開を聴き手に伝えることを意識した「自然な朗読発話」が特徴です。読み上げ特有の抑揚(声の上げ下げ)や間の取り方、文脈に応じた発声が丁寧に記録されており、より人間らしい自然な音声表現をAIに学習させる上で非常に価値のあるデータと言えます。
「トランスクリプト」がもたらす恩恵
そして、音声データとセットで提供される「トランスクリプト」(文字起こしデータ)も非常に重要です。AIが音声を学習する際、どの音声がどの言葉に対応するのかを示す「正解データ」が必要となります。このトランスクリプトがあることで、AIは音声とテキストの対応関係を正確に学ぶことができ、音声認識モデルの学習効率が格段に向上します。さらに、音声と言語を横断して処理する「マルチモーダルAI」の開発にも活用できます。

データセットの概要
このデータセットの主な仕様は以下の通りです。
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 日本人 |
| データ形式 | 音声データ:mp3 |
| 収録時間 | 1音声30秒〜120分 |
| 音声レート | 44.1kHz / 48kHz |
| 対象のシーン | ・子ども向け物語を一人の話者が朗読するシーン ・登場人物や物語展開をわかりやすく伝える読み上げシーン |
| サンプル詳細 | https://qleandataset.visual-bank.co.jp/lineup/pn-043 |
なぜこのデータセットがAI開発に不可欠なのか?具体的なメリット
では、この「日本語・1話者・児童書朗読音声データセット」が、具体的にどのようなAI開発に役立つのでしょうか?AI初心者の方にも理解しやすいように、主要なAI技術と合わせて解説します。
ASR(自動音声認識)モデルの検証に最適
ASR(Automatic Speech Recognition:自動音声認識)とは、人間の話す声をテキスト(文字)に変換する技術のことです。スマートフォンの音声入力や、議事録の自動作成などに利用されています。このデータセットは、児童書や童話の朗読音声という、物語文脈を伴う読み上げ発話を含んでいるため、ASRモデルがこのような「読み上げ」の音声をどれだけ正確に文字に起こせるかを評価するのに非常に適しています。
特に、単一話者であるため、話者の声質による影響を考慮せずに、物語の内容や文章の構造に起因する認識エラーを詳細に分析することが可能です。これにより、より汎用性の高いASRモデルの開発に貢献できます。
NLP・LLM(自然言語処理・大規模言語モデル)の学習・評価を強化
NLP(Natural Language Processing:自然言語処理)は、人間が日常的に使う言葉(自然言語)をコンピューターに理解させる技術です。LLM(Large Language Model:大規模言語モデル)は、このNLPの進化形であり、ChatGPTに代表されるように、まるで人間のように自然な文章を生成したり、質問に答えたりすることができます。
このデータセットは、物語形式の連続した長文テキスト(トランスクリプト)を含んでいるため、LLMが物語の流れや登場人物の関係性をどれだけ正確に理解し、記憶できるかを検証するのに役立ちます。AIが単語や短文だけでなく、長い文脈の中で意味を捉える能力を高めることは、より高度な対話型AIや文章生成AIの開発につながります。
音声と言語を連携させる「マルチモーダルAI」開発への応用
近年注目されているのが「マルチモーダルAI」です。これは、音声、画像、テキストといった複数の種類の情報を同時に処理し、連携させることで、より高度な判断や応答を可能にするAIのことです。例えば、音声で話された内容を認識し、その内容に基づいて画像を生成したり、テキストで詳細な説明を加えたりするようなAIが考えられます。
このデータセットは、音声とそれが意味するテキストが完全に一致しているため、音声認識モデルの学習だけでなく、音声入力から言語処理を行い、さらにその結果を別の形で表現するといった、音声と言語を横断するマルチモーダルな検証用途にも非常に適しています。これにより、音声とテキストの双方を理解する、より高度で人間らしいAIの開発が加速するでしょう。
「日本語・1話者・児童書朗読音声データセット」の具体的な活用事例
このデータセットは、研究用途と産業用途の両方で幅広い活用が期待されます。
研究分野での応用
-
音声認識モデルにおける朗読音声の認識精度検証
児童書や童話の朗読音声を使って、ASRモデルが物語文脈を伴う読み上げ発話をどの程度正確に文字起こしできるかを評価する研究に利用できます。単一話者条件のため、発話内容や文構造に起因する誤認識を分析し、モデルの弱点を特定し改善につなげることが可能です。 -
長文コンテキストを扱う言語モデルの理解検証
物語形式の連続したテキストを用い、LLMが物語の流れや登場人物の関係性をどの程度保持・理解できるかを検証する研究用途に利用できます。例えば、物語の途中の質問に対して、LLMが正確に答えることができるか、登場人物の感情の変化を捉えられているかなどを評価できます。
産業分野での応用
-
音声読み上げAI・ナレーション生成モデルの評価
児童向けコンテンツを想定した音声読み上げAI(テキストを音声に変換する技術)において、物語調の自然な発話表現(抑揚や間の取り方)をどのように再現できているかを確認するための評価データとして利用できます。絵本の読み聞かせアプリや、教育コンテンツのナレーション生成などに応用が期待されます。 -
音声入力を伴う対話型AIの基礎検証
物語朗読音声と対応するテキストを用い、音声入力を起点とした対話・応答処理の検証や、音声と言語を統合した処理パイプラインの検証用途に利用できます。例えば、子ども向けの教育用ロボットや、物語を通じて学習を促すAIアシスタントなどの開発において、自然な対話を実現するための基礎データとして活用できるでしょう。
Qlean Datasetが提供する「安心」と「多様性」
Qlean Datasetは、今回ご紹介した朗読音声データセット以外にも、AI開発に必要な多様なデータセットを提供しています。その最大の特長は、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援している点です。
権利処理済みで商用利用も安心
AI学習用データは、著作権や肖像権など、さまざまな権利が絡むデリケートな情報です。Qlean Datasetで提供されるデータは、すべての被写体から同意を取得し、権利処理が適切に行われているため、研究用途はもちろん、商用展開を見据えたAI開発においても安心して利用できます。これにより、開発者は法的なリスクを心配することなく、AI開発に専念できます。
多様なデータ形式と「AIデータレシピ」
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多岐にわたる形式のデータに対応しています。また、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。
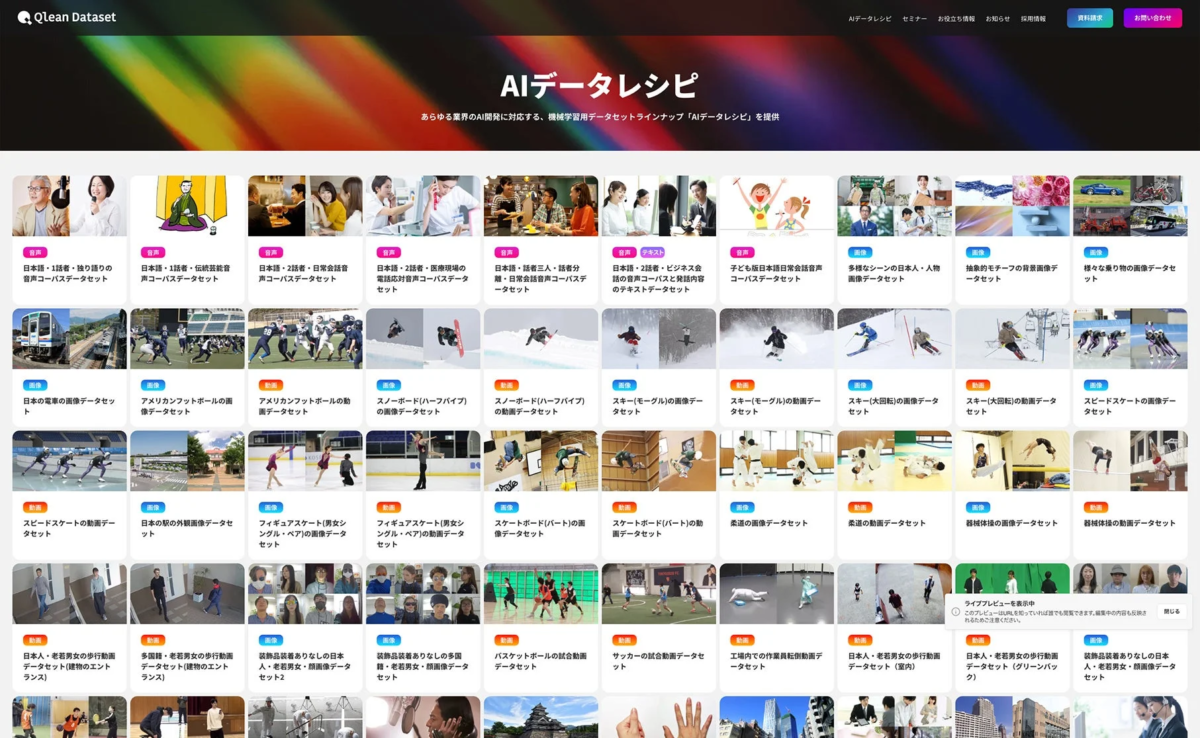
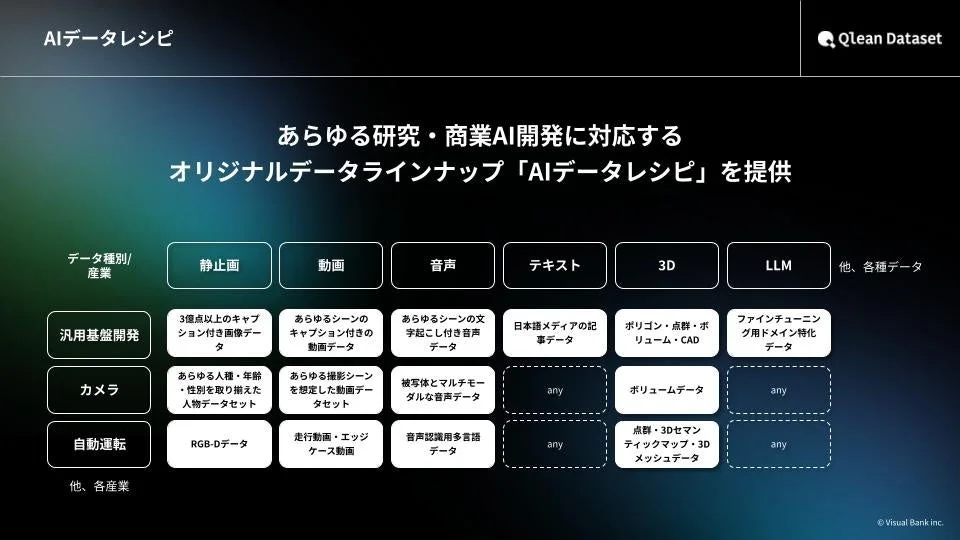
これらのデータは、既存のものであれば最短1日で納品可能であり、もし既存のラインナップにないデータが必要な場合でも、カスタム撮影・収録・収集による独自のデータ構築にも柔軟に対応してくれます。これにより、AI開発のあらゆるニーズに応えることができるのです。


Visual Bank株式会社とAI開発の未来
Qlean Datasetを運営するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラの構築・提供を行っているスタートアップ企業です。漫画家の創作活動をサポートするAI補助ツール『THE PEN』の提供なども手掛けています。
同社は、国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。このような先進的な企業が提供する高品質なデータソリューションは、日本のAI技術の発展に大きく貢献していくことでしょう。
まとめ:高品質データで拓くAIの可能性
今回ご紹介した「日本語・1話者・児童書朗読音声データセット」は、ASR(自動音声認識)やNLP(自然言語処理)、LLM(大規模言語モデル)、さらにはマルチモーダルAIといった、音声・言語系AIの開発において非常に価値の高い学習データです。
AIの性能は、学習データの質に直結します。Qlean Datasetが提供する、権利処理済みで高品質なこのデータセットは、AI開発者がデータの準備に悩むことなく、より高度で実用的なAIモデルの開発に集中できる環境を提供します。特に、子ども向けのコンテンツ開発や、より人間らしい自然な対話が求められるAIの分野で、その真価を発揮することでしょう。
Qlean Datasetのようなデータソリューションの進化は、AI技術の可能性をさらに広げ、私たちの未来をより豊かにしていくことが期待されます。AI開発に携わる企業や研究者の方々は、ぜひこの新しいデータセットとQlean Datasetのサービスを検討してみてはいかがでしょうか。
関連リンク
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/