
AI開発を加速!Qlean Datasetが「日本語・1話者・怪談系朗読音声データセット」を提供開始

近年、人工知能(AI)の進化は目覚ましく、私たちの生活やビジネスに大きな変化をもたらしています。特に、音声認識(ASR)や大規模言語モデル(LLM)といった、AIが人間の言葉を理解し、生成する技術は、スマートスピーカーや自動翻訳、チャットボットなど、様々な分野で活用されています。
これらの音声・言語系AIの性能をさらに高めるためには、高品質で多様な学習データが不可欠です。そんな中、Visual Bank株式会社は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、新たなデータセットの提供を開始しました。その名も「日本語・1話者・怪談系テーマの朗読音声コーパスとトランスクリプト」です。
このデータセットは、ASR(自動音声認識)、音声理解、LLM(大規模言語モデル)といった音声・言語系AIの開発や研究を強力に支援することを目的としています。AI初心者の方にも分かりやすく、この画期的なデータセットがどのようなものなのか、そしてAI開発にどう貢献するのかを詳しくご紹介します。
新たな日本語音声データセットの全貌
今回Qlean Datasetから提供が開始されたのは、「日本語・1話者・怪談系テーマの朗読音声コーパスとトランスクリプト」です。これは、怪談や怖い話といった物語性のある日本語テキストを、一人の日本人話者が朗読した音声データと、その朗読内容を正確に書き起こしたテキスト(トランスクリプト)で構成されています。
データセットの主な特徴
このデータセットの最大の特徴は、その「怪談」というテーマにあります。怪談は、物語の進行に伴って、不安感や緊張感といった感情が自然に表現される語り口が特徴です。これにより、単に読み上げるだけの音声とは異なり、感情を伴う連続的な発話音声が豊富に収録されています。
-
感情豊かな音声表現: 物語の展開に合わせて、抑揚、間(ま)、声のトーン変化などが繊細に表現されています。これは、人間の感情や意図を理解するAIの開発において非常に価値の高いデータとなります。
-
長文コンテキストへの適応性: 怪談は、単文ではなく、物語全体を通して文脈が形成されます。そのため、このデータセットは、長文の文脈を理解する音声認識モデルや言語モデルの学習に特に適しています。
-
1話者朗読形式の利点: 一人の話者による朗読形式であるため、複数の話者が混在する場合に必要となる「話者分離」の技術を前提としないモデル検証や、話者の条件を固定した上での音声・言語挙動の分析に役立ちます。
データセットの概要
このデータセットの具体的な仕様は以下の通りです。
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 日本人 |
| データ形式 | 音声データ:mp3 |
| 収録時間 | 1音声30秒〜90分 |
| 音声レート | 44.1kHz / 48kHz |
| 対象のシーン | ・怪談やホラー作品の文章を、一人の話者が感情を込めて朗読するシーン ・不安感や緊張感を伴う語り口で物語が進行する朗読シーン |
より詳細な情報やサンプル音声は、以下のQlean Datasetのウェブサイトで確認できます。
サンプル詳細
なぜ「怪談」がAI開発に貢献するのか?
AIがより人間らしいコミュニケーションを実現するためには、単に言葉を文字に変換するだけでなく、その言葉に含まれる感情や文脈を理解することが重要です。この点において、怪談というテーマは非常にユニークで、AI開発に大きなメリットをもたらします。
感情表現の学習
怪談は、聞き手の不安や恐怖を煽るために、話者が意図的に声のトーンを変えたり、間を取ったり、抑揚をつけたりします。これらの音声表現は、人間の感情と密接に結びついています。このデータセットを使ってAIを学習させることで、AIは以下のような能力を向上させることが期待されます。
-
感情認識の精度向上: 音声から話者の感情(不安、緊張、驚きなど)をより正確に識別できるようになります。
-
自然な音声生成: AIが感情を込めた、より人間らしいナレーションや対話音声を生成する能力を高めます。
長文コンテキスト理解の強化
一般的な会話や指示では、短い文章や単語の認識が主になりますが、物語では文脈が非常に重要です。怪談の朗読音声は、長い物語を通じて一貫した文脈を保持しており、AIが長文を理解し、その中で情報間の関係性を把握する能力を養うのに適しています。
-
ASRモデルの文脈認識能力: 長い発話の中で、単語の誤認識が文脈によって修正されるなど、より高度な音声認識が可能になります。
-
LLMの物語理解: 音声認識結果をLLMに入力することで、物語のプロット、登場人物の感情、伏線などを理解し、要約や質問応答の精度を向上させることが期待されます。
AI開発における多様なユースケース
このデータセットは、研究用途から商用展開を見据えたAI開発まで、幅広いシーンでの活用が想定されています。
研究用途での活用イメージ
AIの研究者にとって、このデータセットは新たな知見を得るための貴重な資源となるでしょう。
-
長文音声入力に対する音声認識・音声理解モデルの評価: 怪談朗読に含まれる連続的な語り口を利用することで、ASRモデルが長い発話音声をどれだけ正確に認識できるか、また文脈が継続する中でどのような誤認識が発生しやすいかを検証する研究に利用できます。
-
音声入力を起点とした言語モデルの文脈理解検証: 音声認識されたテキストをLLMや音声理解モデルに入力し、物語の文脈をどれだけ正確に保持し、内容を理解できるかという挙動を評価する用途に活用できます。
産業用途での活用イメージ
ビジネスの現場でも、このデータセットはAIの応用範囲を広げる可能性を秘めています。
-
音声対話AI・ナレーション生成AIの検証用データ: 怪談朗読に含まれる抑揚や間を含んだ音声表現を用いることで、音声対話AIがユーザーの感情をより深く理解したり、音声生成AIがより感情豊かで自然なナレーションを作成したりするための入力理解や出力品質の検証に利用できます。
-
コールセンター・音声UI向け音声処理モデルの事前検証: 感情を含む連続発話音声は、コールセンターでの顧客対応や音声ユーザーインターフェース(UI)において、認識の安定性や誤動作のリスクを事前に検証するのに適しています。例えば、顧客の不満や緊急性を伴う発言をAIが正確に捉えるための学習に役立つでしょう。
Qlean Dataset(キュリンデータセット)とは
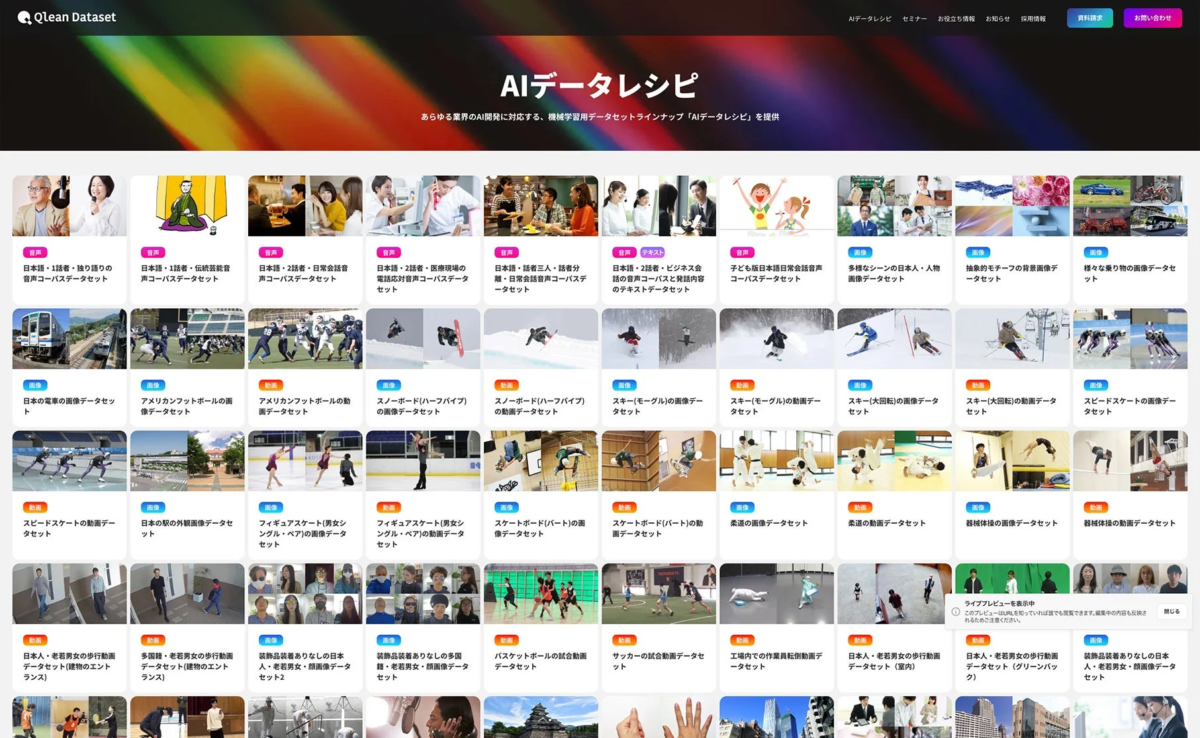
Qlean Datasetは、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。AI開発の現場で直面する「学習用データの収集と整備の負荷」という課題を解決し、法的リスクのないAI開発環境の構築を支援しています。
Qlean Datasetの提供する「AIデータレシピ」
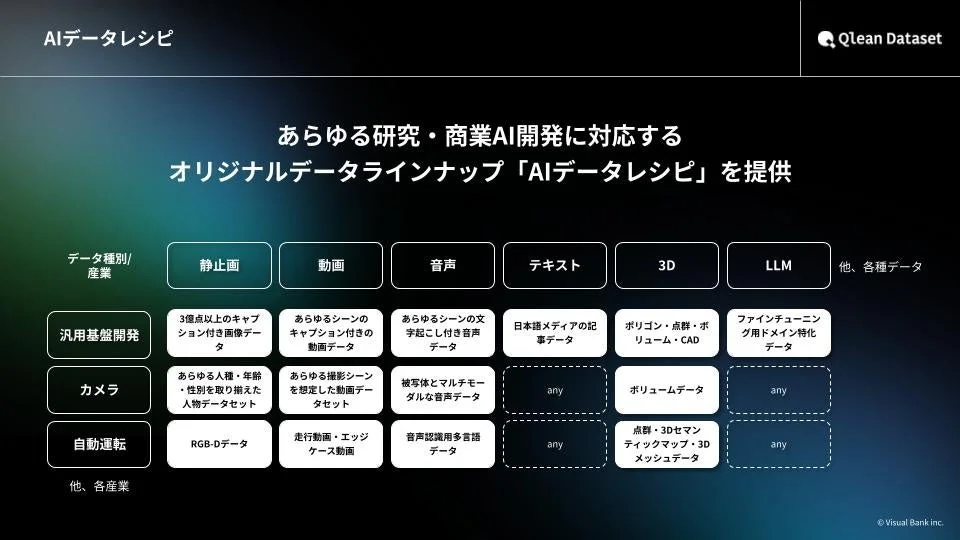
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多岐にわたる形式のデータを扱っており、研究用途から商用利用まで、安全に利用できる環境を整えています。その中核となるのが、オリジナルデータラインナップ「AIデータレシピ」です。
「AIデータレシピ」は、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界に特化したり、最新トレンドを反映したりしたデータセットを継続的に拡充しています。これにより、AI開発者は常に質の高い、目的に合ったデータにアクセスできます。

Qlean Datasetの強み

Qlean DatasetがAI開発者から支持されるのには、いくつかの明確な理由があります。
-
権利関係のクリアさ: 提供されるデータは、すべての被写体から同意を取得し、著作権や肖像権などの権利処理が適切に行われています。これにより、研究用途だけでなく、商用展開を見据えたAI開発でも安心して利用できます。
-
迅速なデータ提供: 既存のデータセットは最短1日で納品可能であり、AI開発のスピードを落とすことなく、必要なデータを手に入れることができます。
-
柔軟なカスタマイズ: AIデータレシピにないデータについても、要件に応じてカスタム撮影・収録・収集による独自のデータ構築に対応しています。
Qlean Datasetの詳細は、以下のサイトで確認できます。
Visual Bank株式会社について
Visual Bank株式会社は、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。「あらゆるデータの可能性を解き放つ」をミッションに掲げ、事業活動を展開しています。
漫画家の「もっと描きたい!」をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持つなど、多角的にAI関連事業を展開しています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
まとめ
Qlean Datasetが新たに提供を開始した「日本語・1話者・怪談系テーマの朗読音声コーパスとトランスクリプト」は、感情表現や長文の文脈理解が求められる次世代の音声・言語系AI開発において、非常に重要な役割を果たすデータセットです。
AI初心者の方にもご理解いただけたように、怪談というユニークなテーマが、AIの感情認識能力や物語理解能力の向上に直結するという点は、今後のAI技術の発展に大きな期待を抱かせます。AIがより人間らしいコミュニケーションを実現し、私たちの生活を豊かにする未来に向けて、このような高品質な学習データが不可欠となるでしょう。
Visual Bank株式会社とQlean Datasetの取り組みは、AI開発の現場に新たな可能性をもたらし、日本のAI技術の発展に大きく貢献していくことが期待されます。

