
リコーがオンプレミス環境に最適な高性能日本語LLMを発表
株式会社リコーは、企業のデジタルトランスフォーメーション(DX)を加速させる新たな取り組みとして、オンプレミス環境に特化した高性能な日本語大規模言語モデル(LLM)を開発しました。このLLMは、Googleが提供するオープンモデル「Gemma 3 27B」を基盤としており、エフサステクノロジーズ株式会社の「Private AI Platform on PRIMERGY」に搭載されて提供が開始されます。これにより、多くの企業がセキュアな環境でAIを業務に活用できるようになります。
大規模言語モデル(LLM)とは?
大規模言語モデル(LLM)とは、人間が使う言葉(自然言語)を理解し、生成する能力を持つ、非常に大きなAIモデルのことです。膨大なテキストデータを学習することで、質問に答えたり、文章を要約したり、新しい文章を生成したりと、人間のような自然なコミュニケーションが可能になります。近年、ビジネスでの活用が急速に進んでおり、業務効率化や新たな価値創造への期待が高まっています。
オンプレミス環境でのLLM導入の重要性
クラウド上で提供されるLLMが一般的になりつつありますが、企業によってはデータセキュリティやプライバシー保護の観点から、自社のサーバー(オンプレミス環境)でのLLM運用が求められるケースが多くあります。リコーが開発した今回のLLMは、このオンプレミス環境での導入に最適化されており、企業が安心してAIを業務に組み込めるよう設計されています。
リコー新日本語LLMの主要な特長
Google「Gemma 3 27B」をベースに独自技術で性能向上
リコーの新しい日本語LLMは、Googleが提供するオープンモデル「Gemma 3 27B」をベースに開発されました。「Gemma」はGoogleが開発した軽量で高性能なオープンモデルシリーズであり、その中でも270億パラメータを持つ「Gemma 3 27B」は、高い基本性能を備えています。
リコーは、このベースモデルに独自の「モデルマージ」技術を適用し、大幅な性能向上を実現しています。モデルマージとは、複数の学習済みLLMモデルの強みを組み合わせて、より高性能なモデルを構築する技術です。GPUのような大規模な計算リソースが不要なため、効率的かつ手軽にモデル開発を進められる点が注目されています。
具体的には、リコー独自の約1万5千件のインストラクションチューニングデータで追加学習したInstructモデルから抽出した「Chat Vector」など、複数のChat Vectorを開発し、Gemma 3 27Bにマージすることで、指示への追従能力を飛躍的に向上させています。Chat Vectorは、指示追従能力を持つモデルからベースモデルの重み(ウェイト)を差し引き、指示追従能力のみを抽出したベクトルであり、モデルマージにおいて重要な役割を果たします。
最先端モデルと同等レベルの高性能を実現
同規模パラメータ数のLLMとのベンチマーク評価の結果、リコーの日本語LLMは、米OpenAIのオープンウェイトモデル「gpt-oss-20b」をはじめとする最先端の高性能モデルと同等の性能を示すことが確認されました。

評価には、複雑な指示やタスクを含む代表的な日本語ベンチマーク「ELYZA-tasks-100」と、日本語のマルチターンの対話能力を評価する「Japanese MT-Bench」が用いられました。これらのベンチマークは、それぞれ以下の能力を測るものです。
-
Japanese MT-Bench: コーディング、抽出、人文、数学、推論、ロールプレイ、STEM、ライティングといった多岐にわたるタスクにおける、複数回のやり取り(マルチターン対話)での対話能力を評価します。スコアは1(最低)から10(最高)の範囲です。
-
Elyza-tasks-100: 要約の修正、意図の汲み取り、複雑な計算、対話生成など、広範な複雑な指示・タスクに対する処理能力を評価します。スコアは1(最低)から5(最高)の範囲で、ここではJapanese MT-Benchとの平均スコアを算出するためにスコアを2倍にして比較されています。
以下の表は、各モデルのベンチマーク評価結果を示しています。
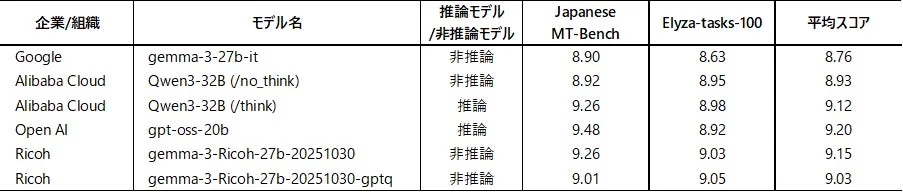
この結果からも、リコーが開発したLLMが、主要な日本語ベンチマークにおいて非常に高いスコアを記録していることが分かります。
高い初期応答性と執筆能力
本モデルは、「非推論モデル」ならではの高い初期応答性(Time to First Token: TTFT)を実現しています。非推論モデルとは、学習済み知識から直接回答を生成する思考プロセスを持つモデルのことで、推論のステップを省略するため、明確な指示を与えれば迅速な回答生成が可能です。初期応答性(TTFT)は、ユーザーがプロンプトを入力してからモデルが最初のテキストを生成し始めるまでの時間を測る指標であり、ユーザー体験(UX)に直接影響します。
さらに、高い執筆能力も兼ね備えており、ビジネス文書作成やコンテンツ生成など、幅広いビジネス用途での活用に適しています。
コンパクトで省エネルギー、低コスト導入を実現
本LLMのモデルサイズは270億パラメータとコンパクトでありながら、高性能を実現しています。これにより、一般的なPCサーバーなどでも構築が可能となり、低コストでのプライベートLLM導入を可能にします。
LLMは高い電力消費による環境負荷が課題とされていますが、コンパクトで高性能な本LLMは、省エネルギー化と環境負荷低減にも貢献します。これは、環境意識が高まる現代において、企業にとって大きなメリットとなるでしょう。
エフサステクノロジーズとの協業による提供体制
「Private AI Platform on PRIMERGY」に搭載
リコーの新しい日本語LLMは、お客様の要望に応じた個別提供も可能ですが、特に注目されるのは、2025年12月下旬からエフサステクノロジーズ株式会社が提供するオンプレミス環境向けの対話型生成AI基盤「Private AI Platform on PRIMERGY(Very Small モデル)」に搭載されて提供が開始される点です。
エフサステクノロジーズの代表取締役社長 CEOである保田 益男氏は、この協業について「株式会社リコーの開発した高性能なLLMと小規模から大規模まで幅広いラインナップを持つ対話型生成AI基盤『Private AI Platform on PRIMERGY』を組み合わせたオンプレミスAIソリューションをリコーグループの販売網を通じて、より多くのお客様にご提供できることを大変嬉しく思います」とコメントしています。
このプラットフォームには、本LLMの量子化モデルと、生成AI開発プラットフォーム「Dify(ディフィ)」がプリインストールされた状態で提供されます。これにより、お客様はLLM動作環境の構築に手間をかけることなく、すぐに生成AIの活用を始められます。
ノーコード開発プラットフォーム「Dify」と伴走支援サービス
「Dify」は、お客様が自社の業種や業務に合わせた生成AIアプリケーションをノーコード(プログラミング不要)で簡単に作成できるプラットフォームです。AIの専門知識がない担当者でも、直感的な操作で業務に役立つAIツールを開発できます。
さらに、リコージャパン株式会社が提供する「Dify支援サービス」による伴走支援も利用可能です。これにより、社内にAIの専門人材がいない企業でも、安心して生成AIの業務活用を開始し、継続的に効果を最大化していくことが期待できます。
株式会社リコー リコーデジタルサービスBU AIサービス事業本部 本部長 梅津 良昭氏は、「この度、優れた基本性能を持つGoogleの先進的な基盤モデルGemma 3 27Bをもとに、オンプレミス導入に最適な日本語LLMを開発しました。エフサステクノロジーズ様による迅速な製品化により、Private AI Platform on PRIMERGYへのこの日本語LLMの搭載が実現しました。3社の技術と強みが結集した本製品を、リコージャパンの提供力で多くのお客様にお届けし、伴走支援することで課題解決に貢献できることを確信しております」と述べています。
リコーのAI開発の歴史と今後の展望
長年にわたるAI開発の経験
リコーは、1980年代からAI開発に着手し、長年にわたりこの分野での知見を蓄積してきました。2015年からは画像認識技術を活かした深層学習AIの開発を進め、製造分野での外観検査や振動モニタリングなどに適用してきました。2021年には、自然言語処理技術を活用し、オフィス内の文書分析やコールセンターの顧客の声(VOC)分析を通じて、業務効率化や顧客対応を支援する「仕事のAI」の提供を開始しています。
LLM研究開発への早期参入と独自の強み
リコーは、2022年から大規模言語モデル(LLM)の研究・開発にもいち早く着手し、2023年3月には独自のLLMを発表しました。その後も、700億パラメータという大規模ながらオンプレミス環境でも導入可能な日英中3言語対応のLLMを開発するなど、お客様の多様なニーズに応えられるAI基盤の開発を進めています。
リコーのLLM開発における強みは、独自のモデルマージ技術(特許出願中)をはじめとした、多様で効率的な手法・技術を活用している点です。これにより、お客様の用途や環境に最適な企業独自のプライベートLLMを、低コストかつ短納期で提供できる体制を確立しています。
さらなる進化へ:推論性能向上とマルチモーダル化
リコーは今後もLLMの進化を追求していきます。具体的には、LLMが単に情報を検索したりテキストを生成したりするだけでなく、複数のステップからなる論理的な思考プロセスを経て結論を導き出す「推論性能」の向上を目指します。これにより、より複雑な問題解決や高度な意思決定支援が可能になるでしょう。
また、特定の業種・業務に特化したモデルの開発も進め、より専門性の高いAIソリューションを提供していく予定です。さらに、リコーが強みとする画像認識などの「マルチモーダル性能」と組み合わせることで、テキスト情報だけでなく、画像や音声なども総合的に理解・処理できるLLMラインアップを強化していく方針です。
画像認識や自然言語処理に加え、音声認識AIの研究開発も推進し、音声対話機能を備えたAIエージェントの提供も開始しています。リコーは、お客様に寄り添い、業種業務に合わせて利用できるAIサービスの提供を通じて、オフィスや現場のデジタルトランスフォーメーション(DX)を強力に支援していくとしています。
関連リンク:
-
Google Gemma 3 27Bについて: https://ai.google.dev/gemma/docs/core?hl=ja
-
OpenAI gpt-oss-20bについて: https://openai.com/ja-JP/index/introducing-gpt-oss/
-
リコーのAIに関する情報: https://promo.digital.ricoh.com/ai/
まとめ
リコーが開発した「Gemma 3 27B」ベースの日本語LLMは、高性能でありながらオンプレミス環境での導入に最適化され、企業のデータセキュリティとプライバシー保護への懸念を解消します。独自のモデルマージ技術による性能向上、コンパクトなモデルサイズによる低コスト・省エネルギー化は、AI導入のハードルを下げる大きな要因となるでしょう。
エフサステクノロジーズとの協業、そしてノーコード開発プラットフォーム「Dify」と伴走支援サービスの提供を通じて、リコーはAI専門人材が不足している企業でも、生成AIを安全かつ効果的に業務に活用できる環境を整備します。長年のAI開発で培った知見と技術力を背景に、リコーは今後もLLMのさらなる進化と、お客様のDX推進への貢献を目指していきます。この新しい日本語LLMが、多くの企業の働き方やビジネスプロセスに革新をもたらすことが期待されます。

