
AI開発を加速する新たな一歩:Qlean Datasetの「日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット」
近年、AI(人工知能)の進化は目覚ましく、私たちの生活やビジネスのあらゆる場面でその恩恵を感じる機会が増えています。AIが賢くなるためには、大量かつ質の高いデータを用いた「学習」が不可欠です。この「AI学習用データ」は、AIの性能を左右する非常に重要な要素となります。
Visual Bank株式会社(以下、Visual Bank)が、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション『Qlean Dataset(キュリンデータセット)』は、このAI学習用データの提供に力を入れています。そしてこの度、『日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット』の提供を開始しました。この新しいデータセットは、音声認識(ASR)や自然言語処理(NLP)、そして最近注目を集める生成AI基盤モデルの研究・開発に、新たな可能性をもたらすものです。
AI初心者の方にも分かりやすいように、このデータセットがどのようなもので、なぜAI開発において重要なのか、そしてどのように活用されるのかを詳しく解説していきます。

AI学習用データセットとは?なぜ重要なのか
AIは、人間のように自ら考えることはできません。AIは与えられたデータからパターンやルールを学習し、その学習結果に基づいて判断や予測を行います。この学習に使うデータの集まりを「データセット」と呼びます。
例えば、AIに猫の画像を認識させたい場合、猫の画像と「これは猫である」という情報をセットにしたデータを大量に学習させます。するとAIは、猫の画像に共通する特徴を覚え、初めて見る猫の画像でも「これは猫だ」と判断できるようになるのです。このデータが少なかったり、質が悪かったりすると、AIは正しく学習できず、間違った判断をしてしまう可能性が高まります。
特に音声データを扱うAIの場合、ただ音声を学習させるだけでは不十分です。誰が、何を、どのような状況で話しているのかといった情報(アノテーション)が付与された高品質なデータセットが求められます。今回提供が開始されたデータセットは、このようなAI学習の根幹を支える、非常に重要な役割を担っています。
「日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット」の概要と特徴
Qlean Datasetが提供を開始した『日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット』は、その名の通り、日本語の「事件・犯罪」をテーマにした「一人語り(モノローグ)」の音声を収録したデータセットです。
データセットの具体的な内容
このデータセットには、事件・犯罪に関する「歴史的な事例」、「制度の説明」、「社会課題」といったテーマについて、話者が連続的に説明や解説を行う音声が収録されています。特筆すべきは、台本に厳密に依存しない「自然発話」である点です。これにより、以下のような特徴を持つ音声が豊富に含まれています。
-
自然な話題転換や文脈依存の語り: 人が実際に話すような、自然な流れでの話題の移り変わりや、文脈によって意味合いが変わる表現が含まれます。
-
主張の整理やエピソード紹介: 特定の主張を論理的に整理したり、具体的なエピソードを交えながら説明したりする、長尺のモノローグ形式です。
-
感情の抑揚: 台本にない自然な話し方のため、話者の感情の抑揚や間合いが反映されています。
技術的な詳細
-
データ種別: 音声
-
被写体属性: 20代〜50代の男女
-
データ形式: mp3
-
収録時間: 総計約350時間(1音声あたり約5分〜40分)
-
音声レート: 44.1kHz(学習・検証データとして利用可能な高品質な形式)
-
対象のシーン: 話者が事件や犯罪のテーマについて連続的に説明・解説するシーン、長尺の独白・語りかけ形式の自然発話シーン(日常的な話題展開、主張の整理、エピソード紹介を含む)、台本に依存せず、話者の自然なリズムや間が反映された一人語りシーン(文脈依存の語り、話題転換、感情の抑揚などを含む)。
このデータセットは、事件・犯罪という専門性の高い領域における説明的・専門的な内容を含む自然発話を収録しているため、AIモデルが文脈を正確に把握し、長尺の音声を処理し、意味を理解する能力を検証するのに非常に適しています。
サンプルページはこちらで確認できます。
https://qleandataset.visual-bank.co.jp/lineup/pn-008
AI開発における活用シーン:ASR、NLP、生成AIへの貢献
このデータセットは、多岐にわたるAI技術の研究・開発に活用できます。特に以下の3つの分野での貢献が期待されます。
1. 音声認識(ASR)モデルの精度向上
ASR(Automatic Speech Recognition)とは、人間の音声をテキストに変換する技術のことです。スマートフォンの音声アシスタントや、会議の議事録作成ツールなどで使われています。
このデータセットは、事件・犯罪領域という専門的な内容を含み、かつ長尺のモノローグ形式であるため、ASRモデルが複雑な文脈や専門用語を正確に認識する能力を高めるのに役立ちます。例えば、法廷での証言や、犯罪捜査における音声記録など、特定のドメインにおけるASRの精度向上に繋がるでしょう。
-
研究用途(アカデミア): 長尺モノローグを対象としたASRモデルの研究において、文脈依存の語りや話題転換を含む日本語ASRモデルの認識性能を検証できます。
-
産業用途(企業): コールセンターでの音声処理や、知識ベース検索型AIなど、専門性のある語彙を含む音声入力対応AIの高精度化に活用できます。
2. 自然言語処理(NLP)領域の文脈理解・要約モデルの評価
NLP(Natural Language Processing)とは、人間が使う言葉(自然言語)をコンピュータに理解させ、処理させる技術です。文章の要約、翻訳、感情分析などがこれに該当します。
このデータセットは、一人語り形式の長文構造を持つため、AIが文章全体の意味を理解し、重要な部分を抽出したり、要約したりする能力の評価に最適です。事件・犯罪に関する詳細な説明や論理展開を学習することで、AIはより高度な文脈理解が可能になり、正確な情報抽出や要約ができるようになるはずです。
-
研究用途(アカデミア): 意味単位の抽出、談話構造解析、要約モデルの評価に利用できます。
-
産業用途(企業): 生成AIのナレッジ拡張や、教育・研究用途での対話モデル評価など、対象分野に応じた幅広い用途で活用できます。
3. 生成AI基盤モデルの音声→テキスト→意味理解処理の強化
最近話題の生成AIは、テキストや画像、音声などを新しく生成するAIです。ChatGPTのような大規模言語モデル(LLM)が代表的ですが、これらのAIは、音声情報をテキストに変換し、その意味を理解した上で適切な応答を生成するといった、マルチモーダル(複数の情報形式を扱う)な処理能力が求められます。
本データセットは、自然発話ベースのモノローグデータであるため、AIが音声からテキストへの変換、そしてそのテキストの意味理解、さらにはそれに基づいた要約生成や説明生成といった一連のマルチモーダル処理の性能向上に寄与します。特に、専門的な内容を含む音声を正確に理解し、それに基づいて新たな情報を生成する能力は、今後のAIの社会実装において非常に重要となるでしょう。
-
産業用途(企業): 音声起点での要約生成や説明生成など、マルチモーダル処理の性能向上に寄与します。
-
その他実需要(教育・社会実装): 司法・社会教育向けの教材AI研究において、教育向けAIの音声理解や自動説明生成モデルの基礎データとして利用できます。
Qlean Dataset(キュリンデータセット)とは
『Qlean Dataset』は、Visual Bank傘下の株式会社アマナイメージズが提供する、商用利用が可能なAI学習用データソリューションです。AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援しています。
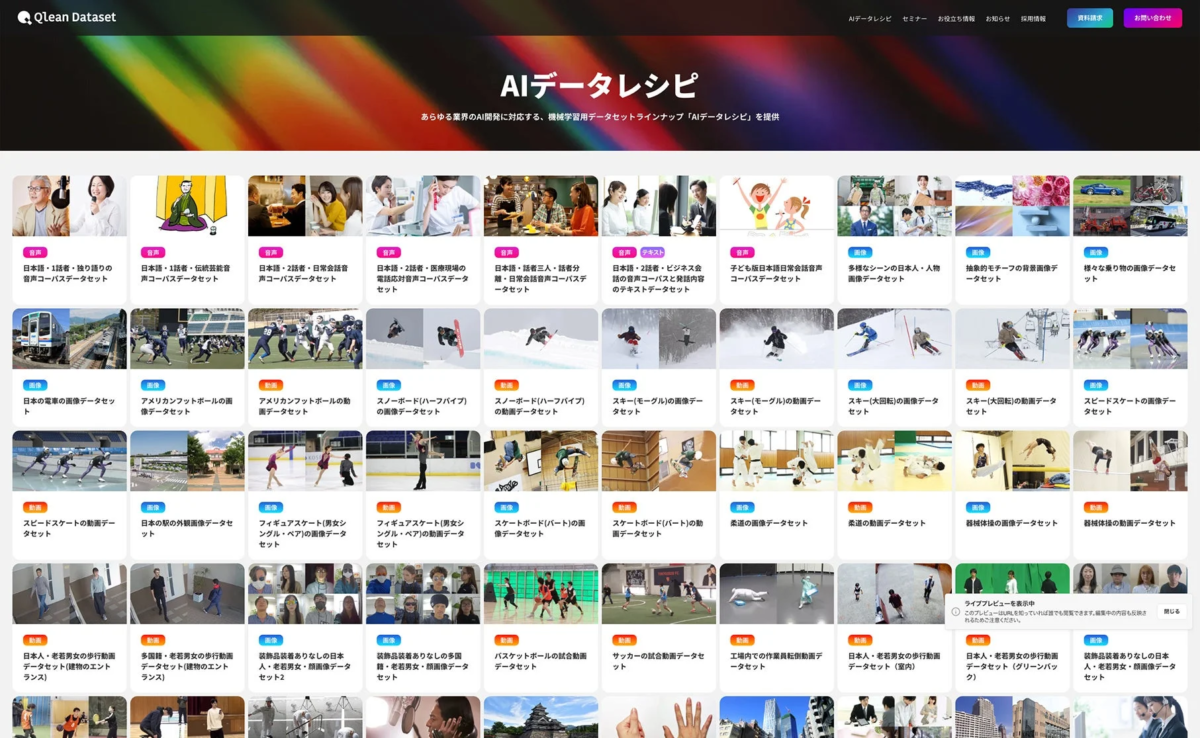
多様なデータ形式と「AIデータレシピ」
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多様な形式のデータに対応しています。また、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社をはじめとするデータパートナーとの協業を通じて、業界特化や最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。これにより、AI開発者は必要なデータを効率的に調達し、開発に集中できる環境が整えられています。
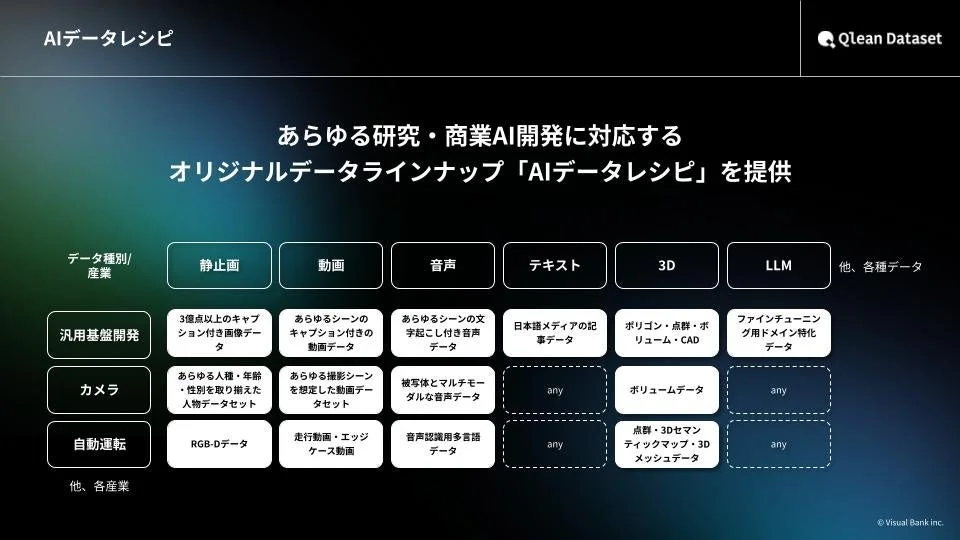
Qlean Datasetの提供価値と強み
Qlean Datasetは、AI開発で必要とされるデータ素材、アノテーション(データにタグ付けする作業)、キャプション(説明文)などを、「AIデータレシピ」として提供しています。その主な強みは以下の通りです。

- 安価かつスピーディーなデータ提供: 初期投資を抑えつつ、迅速なデータ調達が可能です。
- 多様なデータ形式や構成にカスタマイズ: 画像、動画、音声、3D、テキストなど、多様なデータ開発に対応しています。
- AIデータレシピにないデータの拡充: 独自性の高いデータも、要件に応じて準備・提供されます。
- 権利処理済みで商用利用も安心: 著作権や肖像権などの権利クリアランスがされており、国際法規(GDPR/CCPA)に準拠しているため、研究・商用いずれの用途でも安全に利用できます。AI倫理や法制度の最新状況にも対応しています。

Qlean Datasetの詳細やAIデータレシピのラインナップについては、以下のサイトをご覧ください。
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。
同社は、漫画家の「もっと描きたい!」をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。このような背景を持つ企業が提供するデータセットは、AI技術の発展に大きく貢献することが期待されます。
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/
まとめ
Qlean Datasetが提供を開始した『日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット』は、AI開発における新たな可能性を切り開く画期的なサービスです。事件・犯罪という専門性の高いテーマの自然発話データを約350時間も収録していることは、音声認識、自然言語処理、そして生成AIといった最先端のAI技術の精度向上に不可欠な基盤を提供します。
AI初心者の方にとっては、AIがどのように学習し、どのようなデータがその性能を支えているのかを理解する良い機会となったのではないでしょうか。Qlean Datasetのような高品質なデータセットの提供は、AI開発のハードルを下げ、より多くの企業や研究者が革新的なAIモデルを生み出す手助けとなります。
今後、このデータセットが活用されることで、特定の専門領域におけるAIの理解度が飛躍的に向上し、司法・社会教育、コールセンター業務、コンテンツ生成など、多岐にわたる分野でのAIの社会実装が加速することが期待されます。AI技術の進化は、私たちの社会をより豊かで効率的なものへと変えていくことでしょう。

