
AI開発の鍵を握る「学習データ」の重要性
AI(人工知能)技術は、私たちの生活やビジネスに急速に浸透し、その進化は目覚ましいものがあります。しかし、AIが賢く、より人間に近い判断や応答をするためには、質の高い「学習データ」が不可欠です。学習データは、AIが世界を理解し、パターンを認識するための「教科書」のようなもの。この教科書が不十分だったり、偏っていたりすると、AIは期待通りの性能を発揮できません。
特に、人の言葉をAIが理解するための「音声認識(ASR)」、言葉の意味や文脈を解析する「自然言語処理(NLP)」、そして人間のような文章や画像を生成する「生成AI」といった分野では、大量かつ多様な音声データやテキストデータがAIの「知能」を大きく左右します。例えば、AIが人の言葉を正確に聞き取り、その意味を理解し、自然な文章を生成するためには、様々な話し方、文脈、専門用語を含むデータで学習する必要があります。
このような背景の中、Visual Bank株式会社が提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」から、AI開発の新たな可能性を切り開くデータセットが登場しました。それが、「日本語・1話者・歴史テーマトーク音声コーパスデータセット」です。本記事では、この画期的なデータセットがどのようなもので、AI開発の現場にどのようなメリットをもたらすのかを、AI初心者の方にも分かりやすい言葉で詳しく解説していきます。
「日本語・1話者・歴史テーマトーク音声コーパスデータセット」とは?

今回Qlean Datasetが提供を開始したのは、「日本語・1話者・歴史テーマトーク音声コーパスデータセット」です。これは、その名の通り、日本史、世界史、文化史といった歴史分野をテーマに、一人の話者が語り続ける音声を収録したデータセットです。
データセットの主な特徴
このデータセットは、単に歴史に関する情報を読み上げたものではありません。20代から50代の男女話者による、台本に依存しない「自然な語り口」が特徴です。これにより、実際の会話に近い、文脈に沿った説明、話題の転換、具体的なエピソードの紹介など、多様な発話構造がそのまま収録されています。まるで歴史解説のポッドキャストを聞いているかのような、生きた音声データと言えるでしょう。
収録時間は合計で約150時間にも及び、1つの音声ファイルが約5分から40分と長尺である点も特徴的です。データ形式は汎用性の高いmp3形式で、44.1kHzという高音質で収録されています。この長尺で文脈豊かな音声データは、AIが単語を認識するだけでなく、話全体の流れや意味を深く理解するために非常に重要です。
なぜ「歴史テーマ」の「独り語り」が重要なのか?
AIがより高度な処理を行うためには、以下のような点が求められます。
-
専門的な語彙の理解: 歴史分野には「幕府」「ルネサンス」「産業革命」など、一般的な会話ではあまり使われない専門用語が多数登場します。これらの語彙をAIが正確に認識し、意味を理解することは、特定の分野に特化したAIを開発する上で不可欠です。
-
長文における文脈理解: 独り語りは、説明が長く続き、複数の情報が関連付けられながら展開されます。AIがこのような長尺の音声を処理し、文脈を正確に捉える能力は、要約生成や質疑応答など、より複雑なタスクに対応するために必要です。
-
自然な発話パターン: 台本に依存しない自然な語り口は、AIが実際の人間とのコミュニケーションで遭遇するであろう、間や言い直し、感情のニュアンスなどを学習するのに役立ちます。これにより、より人間らしい自然なAIモデルを構築することが期待できます。
このデータセットのサンプルは、Qlean Datasetのウェブサイトで確認できます。
AI開発における多様な活用シーン
この「日本語・1話者・歴史テーマトーク音声コーパスデータセット」は、アカデミアの研究者から企業の開発者、さらには教育分野まで、幅広い領域でAIの高度化に貢献する可能性を秘めています。
研究用途(アカデミア)
大学や研究機関でのAI研究において、このデータセットは以下のような用途で活用できます。
-
長文音声認識モデルの学習・評価: 歴史分野の専門用語や文脈依存の独り語りを含むデータは、長尺の音声入力に対するAIの認識精度を評価したり、どのような間違いを起こしやすいかを分析したりするのに役立ちます。例えば、歴史の講義音声を正確にテキスト化するAIの開発に繋がるでしょう。
-
日本語NLP研究(要約・固有表現抽出・談話解析): 一人語りの説明構造や話題転換を含むデータは、AIが文章の重要な部分を抜き出す「要約生成」、人名や地名などの固有名詞を識別する「固有表現抽出」、話の構造を分析する「談話構造解析」といった日本語の自然言語処理研究に利用できます。
-
生成AI基盤における音声→テキスト→意味理解の研究: 連続的な語りを含むため、音声入力からテキストに変換し、その内容を理解した上で新たな情報を生成する、いわゆる「マルチステップ型AIモデル」の研究に適しています。これは、AIが単に情報を羅列するだけでなく、深い理解に基づいた応答を生成するために不可欠なステップです。
産業用途(企業)
企業におけるAI製品やサービスの開発においても、このデータセットは大きな価値をもたらします。
-
音声認識エンジン(ASR)の日本語精度向上: 専門語彙を含む独り語り音声は、教育コンテンツ、知識データベース、オンライン学習プラットフォームなど、特定の知識領域における音声認識モデルの性能を強化するのに利用できます。これにより、より正確な議事録作成やコンテンツ検索が可能になるでしょう。
-
対話生成AI・音声チャットボットの知識領域強化: 歴史領域の説明構造を含むため、顧客からの質問に対して長文で詳細な回答を生成したり、複雑な概念を分かりやすく説明したりするチャットボットや音声対話AIの学習素材として活用できます。例えば、博物館の音声ガイドAIや、歴史学習支援AIの開発に役立つかもしれません。
-
音声入力型LLM・マルチモーダルAIの評価データ: 文脈理解が求められる長尺音声は、音声からテキスト、そして推論へと一連の処理を行う大規模言語モデル(LLM)やマルチモーダルAIの精度を検証するための評価データとして最適です。これにより、より高度なAIアシスタントの開発に貢献します。
その他実需要(教育・社会実装)
教育現場や社会実装を目指すプロジェクトにおいても、具体的な活用が期待されます。
- 教育支援AIにおける説明生成モデルの開発: 歴史領域の説明音声を学習素材とすることで、教育向けのAI教材が生成する説明や要約の品質向上に貢献します。生徒が質問した際に、AIが歴史の出来事を分かりやすく解説したり、重要なポイントを要約したりする機能の実現に役立つでしょう。
AI学習用データソリューション「Qlean Dataset」の全体像と強み
「日本語・1話者・歴史テーマトーク音声コーパスデータセット」を提供しているのは、Visual Bank株式会社傘下の株式会社アマナイメージズが展開する「Qlean Dataset」です。このソリューションは、AI開発に必要な学習データを幅広く提供しており、研究・商用問わず安全に利用できる環境を整備しています。
多様なデータ形式と「AIデータレシピ」
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多様な形式のデータに対応しています。AI開発の現場で求められる様々なデータニーズに応えるため、業界特化型や最新トレンドに即したデータラインナップを「AIデータレシピ」として継続的に拡充しています。
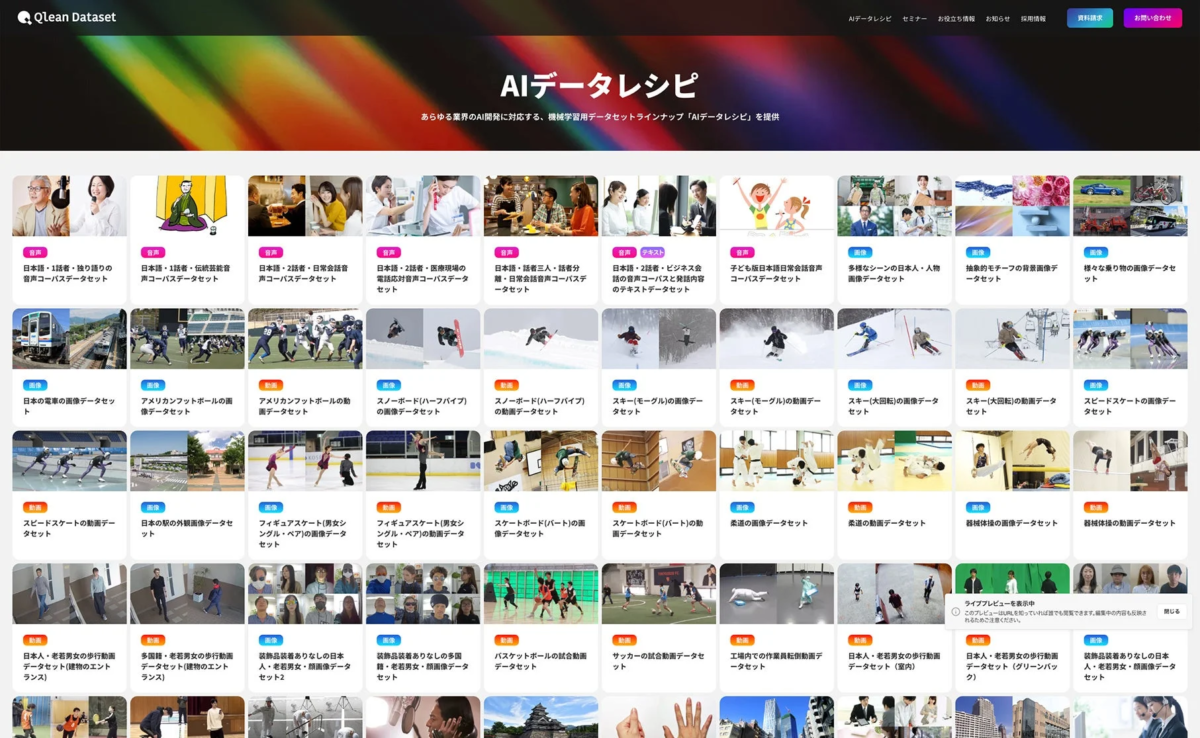
この「AIデータレシピ」は、AI開発者が直面するデータ収集や整備の負担を軽減し、著作権や肖像権などの法的リスクをクリアした環境でAI開発を進められるよう支援することを目的としています。
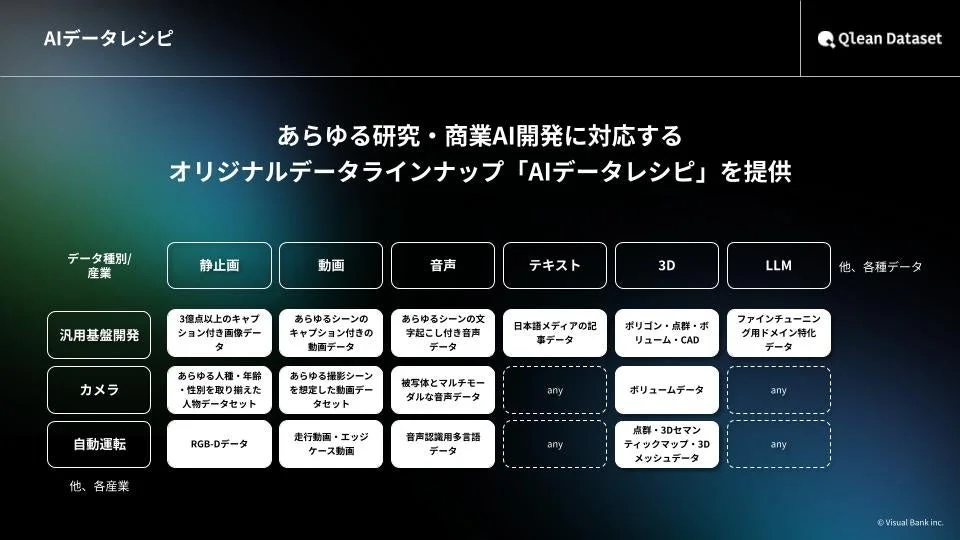
Qlean Datasetが提供する価値
Qlean Datasetは、AI開発で必要とされるデータ素材に加え、アノテーション(AIが学習しやすいようにデータにタグ付けする作業)やキャプション(説明文)なども提供しています。これにより、AI開発者はデータの準備にかかる時間と労力を大幅に削減し、本来の開発業務に集中できるようになります。

Qlean Datasetの主な特長
Qlean Datasetには、AI開発者にとって魅力的な以下の特長があります。
- すべての被写体から同意取得済み: 提供されるデータに含まれる人物や音声については、すべて適切な同意が取得されており、商用利用における法的リスクを最小限に抑えられます。
- 既存データは最短1日で納品可能: 必要なデータが既存のラインナップにあれば、迅速に提供されるため、開発サイクルを加速できます。
- カスタム撮影・収録・収集による独自データ構築にも対応: 特定の要件に合致するデータがない場合でも、要望に応じて新たなデータを作成・収集してくれるため、独自のAIモデル開発を強力にサポートします。
- 権利処理済みで商用利用も安心: 著作権や肖像権といった知的財産権の問題がクリアされているため、研究用途だけでなく、製品やサービスへの組み込みといった商用利用も安心して行えます。

Qlean Datasetの詳細は、以下のサイトで確認できます。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家の創作活動をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持つなど、多角的にAI関連事業を展開しています。
同社は、国の研究開発プログラム「GENIAC」にも採択されており、AI技術の社会実装に向けた取り組みを積極的に加速させています。
まとめ:質の高いデータがAIの未来を拓く
今回発表されたQlean Datasetの「日本語・1話者・歴史テーマトーク音声コーパスデータセット」は、音声認識、自然言語処理、生成AIといった分野のAI開発において、日本語の文脈理解や専門用語対応の精度を飛躍的に向上させる可能性を秘めています。
AIがより賢く、より人間に寄り添った存在になるためには、質の高い学習データが不可欠です。Qlean Datasetのような信頼できるデータソリューションの登場は、AI開発のハードルを下げ、様々な分野でのAI活用を加速させることでしょう。AI開発に携わる方々、あるいはこれからAI技術の導入を検討されている方々にとって、このデータセットは間違いなく強力な武器となるはずです。
この機会に、Qlean Datasetの提供するデータセットが、あなたのAI開発プロジェクトにどのような革新をもたらすか、ぜひ詳細を検討してみてはいかがでしょうか。

