
AIと古典文学の意外な接点?Qlean Datasetの新データセットとは
AI(人工知能)技術の進化は目覚ましく、私たちの生活に欠かせないものとなりつつあります。スマートフォンの音声アシスタントや、自動翻訳、推薦システムなど、身の回りには多くのAIが活用されています。これらのAIが賢くなるためには、「学習データ」が非常に重要です。人間が学校で勉強するのと同じように、AIも大量のデータから知識やパターンを学び取ります。
そんなAI開発の最前線で、Visual Bank株式会社傘下の株式会社アマナイメージズが展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」が、非常にユニークで画期的なデータセットの提供を開始しました。その名も「日本語・1話者・古典朗読音声データセット」です。
「古典文学」と聞くと、難解なイメージを持つ方もいるかもしれません。しかし、この古典文学の朗読音声が、最新のAI技術、特に音声合成(TTS:Text-to-Speech)や言語モデルの能力を飛躍的に向上させる可能性を秘めているのです。本記事では、この新しいデータセットがどのようなもので、なぜAI開発において重要なのか、そしてどのような未来を切り開くのかを、AI初心者の方にも分かりやすい言葉で詳しく解説していきます。

Qlean Datasetが提供する「日本語・1話者・古典朗読音声データセット」の全貌
Qlean Datasetが今回提供を開始した「日本語・1話者・古典朗読音声データセット」は、日本の豊かな古典文学作品を題材としています。このデータセットの最大の特徴は、以下の点にあります。
1. 高品質な朗読音声と正確なテキスト
このデータセットは、古典文学作品をプロのナレーターが一貫して読み上げた「朗読音声」と、その朗読内容を正確に文字に起こした「トランスクリプト(テキストデータ)」で構成されています。AIが学習するためには、音声とテキストが正確に対応していることが非常に重要です。これにより、AIは「この音が、この文字(言葉)を表している」という関係性を深く学習できます。
2. 一人の日本人話者による安定した発話
データセット全体を通して、一人の日本人話者が朗読を担当しています。これはAI開発において非常に大きなメリットです。話者が複数いると、声質や話し方の違いがノイズとなり、AIの学習を複雑にしてしまうことがあります。しかし、一人の話者による安定した発話であれば、AIは特定の声質や発話スタイルを効率的に学習し、高品質な音声合成モデルの構築に役立てることができます。
3. 古典文学特有の表現を網羅
日本の古典文学には、現代語とは異なる文法構造、独特な言い回し、そして特有のリズム(韻律)が存在します。このデータセットは、これらの古典特有の表現を、朗読者が息継ぎや抑揚の変化、間の取り方など、自然な形で読み上げるシーンを網羅しています。AIがこのような多様な音響的特徴とテキストの相関を深く学習することで、文脈を正確に汲み取った、より自然で人間らしい発話を生成する能力を身につけることが期待されます。
データセットの概要
このデータセットの具体的な仕様は以下の通りです。
| データ種別 | 音声、テキスト |
|—|
| 被写体属性 | 日本人 |
| データ形式 | 音声データ:mp3 |
| 収録時間 | 1音声30秒〜90分 |
| 音声レート | 44.1kHz / 48kHz |
より詳細な情報やサンプル音声は、Qlean Datasetのウェブサイトで確認できます。
サンプル詳細
なぜ今、古典文学の音声データがAI開発に重要なのか?
現代のAI技術は、日常会話や一般的な文章の処理においては高い精度を誇ります。しかし、古典文学のような古い言葉遣いや複雑な文法、独特の表現を含むテキストを扱う場合、その精度はまだ十分とは言えません。ここに、「日本語・1話者・古典朗読音声データセット」が果たす重要な役割があります。
1. 高度な言語理解の実現
古典文学は、現代の日本語のルーツであり、豊富な語彙や複雑な文法構造を含んでいます。これらのデータをAIに学習させることで、AIは単に現代語を理解するだけでなく、より深いレベルでの「言語」そのものの構造や歴史的変遷を理解できるようになります。これにより、文語表現を含む高度な言語理解能力を持つAIの開発が可能になります。
2. 繊細な音声表現の学習
古典文学の朗読では、物語の情景や登場人物の感情を表現するために、声のトーン、速さ、抑揚、間の取り方など、非常に繊細な音声表現が用いられます。現代語のデータだけでは学習が難しい、このような複雑な「韻律(いんりつ)」のパターンをAIが学ぶことで、より感情豊かで表現力のある音声合成が可能になります。例えば、AIがオーディオブックを読み上げる際に、単調な読み上げではなく、物語に合わせた情感のこもった声で話すことができるようになるでしょう。
3. 特定の声質・スタイルの再現性向上
一人の話者による長尺の朗読データは、特定の声質や話し方の特徴をAIが深く学習するのに非常に有効です。これにより、まるでその話者自身が話しているかのような、自然で一貫性のあるAIボイス(音声合成)を生成する技術の研究開発が進みます。これは、オーディオブックやデジタルコンテンツにおいて、一貫したブランドイメージを持つ音声を提供したい場合に特に重要です。
広がる可能性:データセットが切り開くAI活用の未来
この「日本語・1話者・古典朗読音声データセット」は、多岐にわたる分野でAI技術の発展に貢献することが期待されています。具体的なユースケースを見ていきましょう。
研究用途:文語体における音響的特徴の抽出と韻律解析
AIの研究者たちは、このデータセットを使って、古典文学特有の文法構造や古い語彙が、話し手のピッチ(声の高さ)やポーズ(間)の配置にどのように影響するかを分析できます。これにより、古典文学に特化した韻律モデルを構築する研究が進み、言語学とAI技術の融合による新たな発見が期待されます。
産業用途:エンターテインメント向け高精度音声合成モデルの開発
エンターテインメント業界では、オーディオブックやデジタルコンテンツの需要が高まっています。このデータセットを学習させることで、一人の話者による安定した、情感豊かで一貫性の高い特定話者音声合成(TTS)エンジンを開発できるようになります。これにより、まるで人間が読み上げているかのような自然なオーディオブックをAIが自動生成したり、ゲームキャラクターに古典的なセリフを自然な声で話させたりする技術が実現するかもしれません。
産業用途:文語表現を含む自動音声認識(ASR)の精度向上
歴史的資料のデジタルアーカイブ化や研究において、古文書や古典作品の音声認識は非常に重要です。しかし、日常会話とは異なる語彙体系を持つ古典作品の音声認識は、現在のAIにとっては難しい課題です。このデータセットを用いることで、歴史的資料の翻刻支援ツールや検索システムにおける音声認識モデルの言語適応能力と認識精度が向上し、文化財のデジタル化がさらに加速するでしょう。
その他実需要:古典文学の「音読自習」支援アプリの開発
教育分野、特にGIGAスクール構想のもとでAIを活用した学習ツールの開発が進んでいます。このデータセットは、お手本となる正確な朗読音声とトランスクリプトを照合させることで、生徒の古典音読が正しく行われているかを判定・評価するAIドリルや学習管理システムの実装に役立ちます。これにより、生徒は自宅でも質の高い音読練習ができ、古典学習のハードルが下がることが期待されます。
その他実需要:視覚障害者・学習困難者向けのアクセシビリティ向上
古典文学には、難解な漢字や送り仮名、特殊な読み(歴史的仮名遣い)が多く含まれており、視覚障害者や学習困難者にとってはアクセスが難しい場合があります。このデータセットを活用することで、デジタル教科書の音声読み上げ機能や、バリアフリーな古典学習環境の構築が可能になります。一貫した高品質な音声で古典作品が提供されることで、より多くの人が日本の豊かな文化遺産に触れる機会を得られるようになるでしょう。
「Qlean Dataset」とは?AI開発を支える高品質データソリューション
今回のデータセットを提供する「Qlean Dataset」は、Visual Bank株式会社の傘下である株式会社アマナイメージズが展開する、AI学習用データソリューションです。AI開発において、高品質で権利処理がきちんと行われたデータを入手することは、非常に重要でありながら、しばしば大きな課題となります。Qlean Datasetは、この課題を解決するために設立されました。
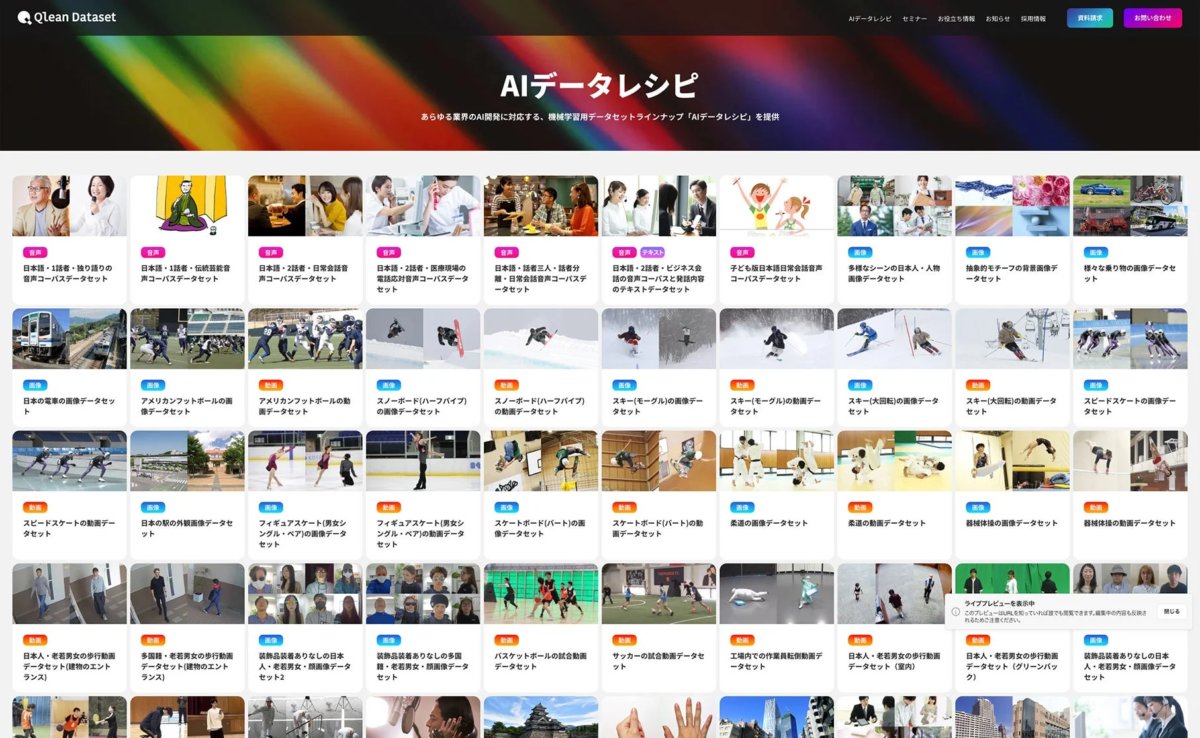
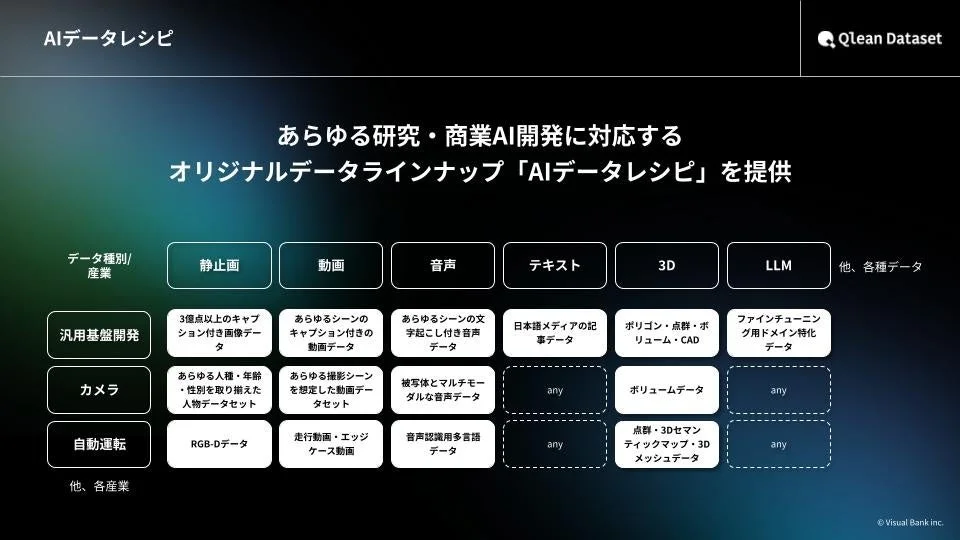
Qlean Datasetの主な特徴は以下の通りです。
1. 多様な形式のデータに対応
画像、動画、音声、3D、テキストなど、AI学習に必要なあらゆる形式のデータを提供しています。これにより、様々なAIモデルの開発ニーズに対応できます。
2. 研究・商用利用が安全
すべてのデータは、被写体からの同意取得や著作権、肖像権などの権利処理が適切に行われています。そのため、研究用途はもちろん、ビジネスでの商用利用においても法的なリスクを心配することなく、安心して利用できます。これはAI開発者にとって非常に大きな安心材料です。
3. 「AIデータレシピ」による豊富なラインナップ
Qlean Datasetは、AI開発用オリジナルデータラインナップ「AIデータレシピ」を展開しています。これは、オーディオブックの自動生成から、歴史的文献のデジタルアーカイブ化を支援する音声認識(ASR)の実装まで、実用的なAI開発を目指すフェーズでの活用を想定した、業界特化型や最新トレンドに即したデータセット群です。国内・海外のデータホルダーやメディアとの協業を通じて、このラインナップは継続的に拡充されています。

Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援しています。
▶ Qlean Datasetサイト:
https://qleandataset.visual-bank.co.jp/
▶ AIデータレシピ:
https://qleandataset.visual-bank.co.jp/lineup
Visual Bank株式会社について
Qlean Datasetを運営する株式会社アマナイメージズの親会社であるVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。
同社は、漫画家の創作活動をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持つなど、AIとデータの分野で多角的に事業を展開しています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。このような先進的な取り組みを通じて、日本のAI技術の発展に大きく貢献している企業です。
▶ Visual Bank企業URL:
https://visual-bank.co.jp/
▶ アマナイメージズ企業URL:
https://amanaimages.com/about/
まとめ:古典とAIが織りなす新たな価値創造
Qlean Datasetが提供を開始した「日本語・1話者・古典朗読音声データセット」は、日本の古典文学という貴重な文化的資産と最先端のAI技術を融合させる画期的な試みです。このデータセットは、AIの音声合成(TTS)能力や言語モデルの理解度を飛躍的に向上させ、より自然で表現豊かなAIボイスの実現に貢献します。
また、研究、エンターテインメント、教育、アクセシビリティといった幅広い分野でのAI活用を後押しし、これまでAIでは難しかった古典文学の深い理解や、それを通じた新たな価値創造の可能性を秘めています。
AI技術は、学習するデータの質と多様性に大きく左右されます。Qlean Datasetのような高品質で権利クリアなデータセットの提供は、AI開発の加速と、より倫理的で信頼性の高いAIシステムの構築に不可欠です。
日本の豊かな古典文化が、これからのAI技術の進化を支え、私たちの社会に新たな恩恵をもたらす未来が、すぐそこまで来ているのかもしれません。AI初心者の方も、この新しいデータセットがもたらす可能性にぜひ注目してみてください。

