Excelで始めるテキストマイニング:無料ガイドで定性データをビジネス価値に変える!初心者向け徹底解説
現代のビジネスにおいて、顧客からのアンケートの自由記述、SNSの口コミ、従業員の日報など、膨大な量の「テキストデータ」が日々生成されています。これらのデータは、顧客の真の声や市場のトレンド、社内の課題を浮き彫りにする宝の山ですが、「どう分析したら良いか分からない」「高額な専門ツールが必要なのでは?」といった理由で、十分に活用されていないケースが少なくありません。
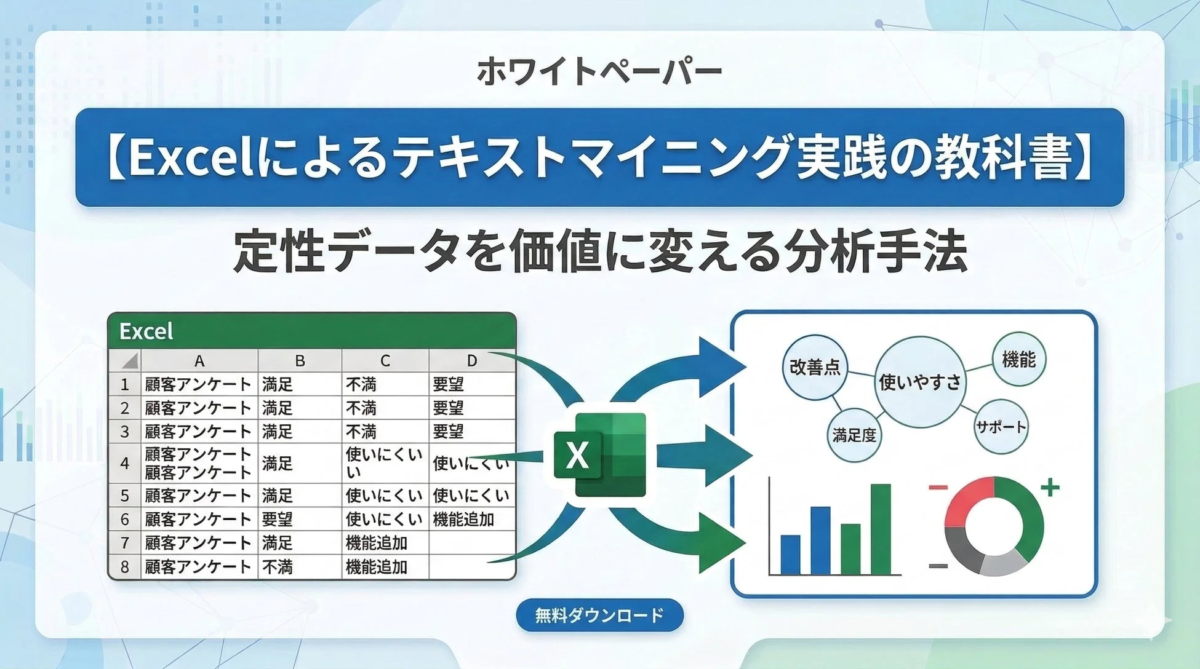
このような課題に対し、株式会社パタンナーは、普段使い慣れたMicrosoft Excelを活用し、専門知識がなくてもテキストデータをビジネス価値へと変換できる実践的ガイド「【Excelによるテキストマイニング実践の教科書】定性データを価値に変える分析手法」を無料で公開しました。

このガイドは、AIやデータ分析の専門知識がない方でも、手軽にテキストマイニングを始められるよう、具体的な手順と豊富な解説で構成されています。本記事では、その内容をAI初心者にも分かりやすい言葉で詳しくご紹介し、どのようにビジネスの効率化と成果向上に繋がるのかを解説します。
「文字のデータ」を眠らせていませんか?:テキストデータ活用の重要性
多くの企業では、顧客アンケートの自由記述欄が「ざっと目を通すだけ」で終わってしまったり、大量の口コミや日報データが蓄積されても「どう分析していいか分からない」と活用されずに眠っています。これらのテキストデータには、顧客の生の声や従業員の気づき、市場の潜在的なニーズといった、ビジネスの意思決定に直結する貴重な「インサイト(洞察)」が隠されています。
これまでのテキストマイニング(文章のデータ分析)は、専門的な高額ツールを導入したり、データサイエンティストによる高度なプログラミングが必要だと考えられがちでした。このため、中小企業やデータ分析専門部署を持たない組織にとっては、導入のハードルが高いと感じられていました。
しかし、適切なアプローチと手法を知っていれば、多くの人が日常的に利用しているExcelを強力な分析ツールへと変えることができます。これにより、個人の「勘と経験」に頼るのではなく、客観的なデータに基づいた意思決定が可能になり、プロダクトの改善やマーケティング施策の「次の一手」を生み出すためのノウハウが手に入ります。
無料ガイドのダウンロードはこちら
▼『【Excelによるテキストマイニング実践の教科書】定性データを価値に変える分析手法』を読む(PDFダウンロード)
https://tazna.io/contents-excel-textmining-2
高額ツール不要!Excelで始めるテキストマイニングの全体像
このガイドでは、Excelが単なる表計算ソフトではなく、「統合データ分析環境」として進化していることを示しています。2026年現在、Excelに「自動化(Power Query)」と「高度解析(Python in Excel)」を組み合わせることで、費用対効果の高いハイブリッドなデータ分析が可能になります。

具体的には、以下のような構成でテキストマイニングを進めることができます。
-
Excel Native(ピボットテーブルとグラフ): 直感的な集計とレポーティングで、基本的なデータの傾向を把握します。
-
Power Query: データの前処理(データの整形やクリーニング)を自動化し、分析にかかる労力を大幅に削減します。
-
Python in Excel: 高度な機械学習モデルをExcelのセル内で直接実行することで、より深い洞察を得ます。
このアプローチは、数百万件のログ分析や厳格な機密情報処理には不向きな場合もありますが、現場部門がPDCAサイクルを回すための「数百〜数万件のインサイト抽出」においては、圧倒的な費用対効果を発揮すると考えられます。
実践!Excelテキストマイニングの具体的なステップ
ガイドでは、テキストマイニングを実践するための具体的なステップが詳細に解説されています。AI初心者でも迷わないよう、準備から高度な分析までを順を追って見ていきましょう。
1. 失敗しないExcelテキストマイニングの準備:収集・整形・前処理
テキストマイニングの成功は、データの「質」に大きく左右されます。ここでは、分析しやすいデータを作るための準備が重要です。
-
まずは“列設計”で勝つ:1行1コメント、メタ情報を添える
-
テキストデータは「1行に1つのコメント」という形で整理します。例えば、アンケートの自由記述であれば、回答者ごとに1行を使います。
-
さらに、そのコメントに関連する「メタ情報」を追加します。これは、回答者の年代、性別、購入商品、満足度評価など、テキスト以外の定量的な情報です。これらの情報とテキストを組み合わせることで、より多角的な分析が可能になります。
-
-
クリーニング:表記ゆれ・不要語・絵文字・改行を整理する
- テキストデータには、同じ意味でも異なる表記(例:「スマホ」と「スマートフォン」)や、分析に不要な言葉(「です」「ます」などの助詞)、絵文字、改行などが含まれていることがあります。これらを統一したり、削除したりする作業が「クリーニング」です。この作業を丁寧に行うことで、分析結果の精度が向上します。
-
Power Queryで前処理を自動化し、再現性を担保する
- ExcelのPower Query機能を使うと、上記のようなデータ整形やクリーニングの作業を自動化できます。一度設定すれば、新しいデータが追加された際も、ボタン一つで同じ前処理を実行できるため、作業の効率化と再現性の確保に繋がります。
2. 形態素解析エンジンとの連携(MeCab/Janome編)
日本語のテキストデータを分析する上で欠かせないのが「形態素解析」です。これは、文章を「単語」や「品詞」といった最小単位に分解する作業です。ガイドでは、MeCabやJanomeといった形態素解析エンジンとExcelを連携させる方法が紹介されています。これにより、Excel上でも高度な日本語のテキスト分析が可能になります。
3. 多彩な分析手法をExcelで実装する
前処理と形態素解析が完了したら、いよいよ分析です。ガイドでは、Excelで実践できる具体的な分析手法が紹介されています。
-
頻度分析とワードクラウドを最短で可視化
-
頻度分析: 最も基本的な分析で、どの単語がどれくらいの頻度で出現するかを調べます。ピボットテーブルを使えば、形態素解析で分解された単語の出現回数を瞬時に集計し、ランキング形式で可視化できます。
-
ワードクラウド: 出現頻度の高い単語を、その頻度に応じて大きく表示する視覚的な表現方法です。無料のアドインなどを使うことで、直感的に重要なキーワードを把握できます。
-
-
共起ネットワークをピボットグラフで描く
- 共起ネットワーク: どの単語とどの単語が一緒に出現しやすいか(共起する関係)を分析し、その関係性をネットワーク図で可視化する手法です。これにより、単語同士の関連性や、特定のテーマで語られることが多いキーワードの組み合わせを発見できます。Excelのピボットグラフを活用して、このネットワークを描く方法が解説されています。
-
感情・評価の簡易スコアリング(辞書方式)で優先度を付ける
- あらかじめ「ポジティブな言葉」と「ネガティブな言葉」の辞書を作成し、テキスト中にこれらの言葉がどれくらい含まれているかをカウントすることで、コメントの感情や評価を簡易的にスコアリングする手法です。これにより、顧客の満足度や不満の度合いを数値化し、改善の優先順位付けに役立てることができます。
4. Python in Excelで一気に高度化:TF-IDF・クラスタリング・可視化
さらに高度な分析を行いたい場合は、Excelに搭載された「Python in Excel」機能が強力な味方になります。これにより、Excelのインターフェース内でPythonの豊富なライブラリを活用し、機械学習を用いた分析が可能になります。
-
Python in Excelの基本:何ができて、どう運用すべきか
- Python in Excelの基本的な使い方、Excel内でPythonコードを実行する方法、そしてどのような分析に活用できるかについて解説されています。これにより、Pythonの知識が少ない方でも、高度な分析に挑戦しやすくなります。
-
TF-IDFで“特徴語”を抽出し、改善点を見える化する
- TF-IDF(Term Frequency-Inverse Document Frequency): 特定の文書やカテゴリにおいて、その単語がいかに特徴的であるかを示す指標です。例えば、ある商品のレビューにおいて、他の商品ではあまり語られないがその商品で頻繁に語られる単語は、その商品の「特徴語」として抽出されます。Pythonのscikit-learnライブラリをExcel内で実行することで、これにより、感覚的な定性評価を明確な改善テーマへと昇華させることができます。
-
クラスタリングで“似た不満”を束ね、打ち手に落とす
- クラスタリング: 似た性質を持つデータをグループ分けする機械学習の手法です。顧客の自由記述コメントをクラスタリングすることで、「似たような不満」や「共通の要望」を持つ顧客グループを特定できます。これにより、個別のコメントに対応するのではなく、複数の顧客に共通する課題に対して効果的な打ち手を講じることが可能になります。
Excelテキストマイニングの活用シナリオ:ビジネスの現場でどう役立つか
このガイドでは、テキストマイニングがビジネスの様々な場面でどのように活用できるかの具体的なシナリオも紹介されています。
-
アンケート/NPS: 自由記述を施策別に仕分けし、顧客の具体的な声に基づいて意思決定を行います。例えば、「新機能への要望」と「既存機能への不満」を明確に区別し、開発の優先順位を決定できます。
-
問い合わせ/VOC(顧客の声): 大量に寄せられる問い合わせ内容から、重大なインシデントの早期検知や、FAQ(よくある質問)の改善に役立てます。顧客がどんな言葉で不満を表現しているかを分析することで、より的確なサポート体制を構築できます。
-
1on1・議事録: 面談記録や会議の議事録から、論点を抽出し、ネクストアクション(次に取るべき行動)を自動で整理する土台として活用します。これにより、会議の生産性向上や、チーム内のコミュニケーション改善に繋げられます。
これらの活用シナリオは、テキストマイニングが単なるデータ分析に留まらず、実際の業務改善や戦略立案に直結する強力なツールとなることを示しています。
無料ガイドのダウンロードはこちら
▼『【Excelによるテキストマイニング実践の教科書】定性データを価値に変える分析手法』を読む(PDFダウンロード)
https://tazna.io/contents-excel-textmining-2
株式会社パタンナーが提供するデータ活用支援サービス
株式会社パタンナーは、このテキストマイニングガイド以外にも、企業のデータ活用を支援する様々なコンテンツやサービスを提供しています。
人気のコンテンツ
パタンナーは、データ活用に関するお役立ち資料を多数公開しています。
-
「データ活用」お役立ち資料3点セット

データ活用に携わる方やDX担当者にとって必要な知識を網羅した資料です。
https://tazna.io/contents-set-of-3-useful-data -
「データ」と「AI」理解の決定版パーフェクトガイド3点セット

生成AIとデータ戦略に必要なナレッジを完全に網羅した大人気ガイドです。
https://tazna.io/contents-set-of-3-perfectguide-data-and-ai -
Excel×AIで実現するデータ分析入門書3点セット

ExcelとChatGPT、Copilot、Pythonを活用したデータ分析を行う際の参考になる入門書です。
https://tazna.io/contents-set-of-3-dataanalysis-using-excel
世界で一番はじめやすいデータカタログ「タヅナ」
データカタログ「タヅナ」は、情報システム部門がデータを管理するためだけでなく、「どんな企業でも・どんな職種でも・すばやく・簡単に使える」ように再発明されたソフトウェアです。
-
POINT①:設計書を自動でつくる
BIツールで作成されたダッシュボードの指標の意味や数値の根拠を、タヅナがすべて一目瞭然で表示します。 -
POINT②:データの背景を理解する

タヅナはデータだけでなく、そのデータに詳しい人を探せます。誰がどのようなデータ資産(データ・ダッシュボード・用語と定義)に詳しいのか、データに関して誰とどんなコミュニケーションを取っているのかを個人単位で把握でき、人材配置の最適化にも活用できます。 -
POINT③:基盤を作る前に活用する
データ基盤の構築には大きな労力がかかりますが、それが全社員に利用されないのはもったいないことです。タヅナは、整備してほしいデータを具体的に把握できるようにデータカタログを再発明し、開発部門と現場部門が一体となってデータ活用を進められるように支援します。
データカタログ「タヅナ」の詳細はこちら:
https://tazna.io/
自社データを活用してAI/DX時代の”企画力”を鍛える「データアーキテクト研修」

このプログラムは、従来のプログラミング習得中心のDX研修とは異なり、ビジネス現場で求められる「データに基づいた企画・設計力」の習得に特化しています。座学と実際の自社データを用いた「企画開発合宿」を組み合わせることで、研修終了時には実務で使えるプロダクト企画書が完成する、完全実践型のカリキュラムです。
詳細はこちらからお問い合わせください:
https://tazna.io/inquiry-dataarchitect-training
専門組織に頼らず“現場主導”でデータを武器にする「データマネジメント実践研修」

このプログラムは、DMBOK(データマネジメント知識体系)の概念を学ぶだけでなく、「現場で明日から使える運用ルール」を研修中に構築することをゴールとしています。専門組織の不足によりデータ活用が停滞している企業において、現場部門が自ら品質管理やガバナンスを担い、DXやAI活用を加速させるための「自走する組織」を作る実践型カリキュラムです。
詳細はこちらからお問い合わせください:
https://tazna.io/inquiry-datamanagement-training
DX推進に欠かせない”データカタログ”を日本初解説!パタンナー代表深野の著書『会社のデータを”誰もが使えるデータ”に変える データカタログという魔法』

株式会社パタンナーの代表である深野嗣氏の著書『会社のデータを”誰もが使えるデータ”に変える データカタログという魔法』は、各部署でバラバラに管理されているデータを全社共通の資産として活用するための実践的手法を、ストーリー形式で分かりやすく解説した一冊です。
営業出身の主人公がDX推進室に異動し、データカタログを武器に社内変革に挑む成長物語を通じて、専門知識がなくても取り組めるデータ活用の本質を学ぶことができます。AIやDX戦略の前に、データ活用の基盤を整えたいと考える方にとって必読の書となるでしょう。
まとめ
株式会社パタンナーが提供する「【Excelによるテキストマイニング実践の教科書】定性データを価値に変える分析手法」は、AI初心者やデータ分析の専門家ではない方々にとって、手軽にテキストマイニングを始め、ビジネスの効率化と成果向上に繋げるための強力な一歩となるでしょう。
高額な専門ツールや複雑なプログラミングは不要で、普段使い慣れたExcelにPower QueryやPython in Excelを組み合わせるだけで、企業内に眠る膨大なテキストデータから客観的なインサイトを引き出すことが可能です。顧客の声や市場のトレンド、社内の課題をデータに基づいて理解し、次の行動に繋げることで、より競争力のあるビジネス展開が期待できます。
ぜひこの無料ガイドを活用して、あなたのビジネスにおけるテキストデータ活用の可能性を広げてみてください。
株式会社パタンナーについて
株式会社パタンナーは、データカタログ「タヅナ」の企画・開発・運営、データ戦略コンサルティング、データ人材育成・組織開発など、企業のデータ活用を多角的に支援しています。
コーポレートサイト:
https://pttrner.co.jp/
データカタログ「タヅナ」:
https://tazna.io/