AIの進化を支える「学習データ」の重要性
近年、私たちの生活の中にAI(人工知能)が浸透し、音声アシスタントやチャットボットなど、AIと自然に会話する機会が増えてきました。これらのAIがまるで人間のように言葉を理解し、適切な応答を生成できるのは、膨大な「学習データ」を元に学習しているからです。
AIは、与えられたデータからパターンを学び、その知識を使って新しい状況に対応します。例えば、音声認識AIであれば、たくさんの音声データとそれに対応するテキストデータを学習することで、私たちの話す言葉を正確に文字に変換できるようになります。この学習データの質や量が、AIの性能を大きく左右するため、AI開発において質の高いデータセットは非常に重要なのです。
多人数対話AIの課題と新しいデータセットの登場
AIが一人との会話だけでなく、複数人が同時に話す「多人数対話」を理解し、適切に対応することは、これまでのAI開発における大きな課題でした。会議の議事録作成AIや、複数のユーザーと同時にやり取りする音声エージェントなど、多人数対話のニーズは高まる一方です。
しかし、多人数対話では、複数の人が同時に話す「重なり発話」や、会話の途中で別の人が割り込む「割り込み」、さらには話題が目まぐるしく変わるなど、一人対話にはない複雑な要素が多く含まれます。これらの複雑な状況をAIに学習させるためには、実際の多人数会話に近い、質の高い学習データが不可欠でした。
このような背景の中、Visual Bank株式会社のAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、多人数対話AIの開発を強力に支援する新たなデータセット「日本語・3話者・コメディテーマトーク音声コーパスデータセット」の提供を開始しました。これは、3名の話者によるコメディ調の自然な掛け合いを収録した画期的なデータセットです。
「日本語・3話者・コメディテーマトーク音声コーパスデータセット」の全貌
この新しいデータセットは、Qlean Datasetが展開する機械学習用データセットラインナップ「AIデータレシピ」の新たな一員として加わりました。このデータセットの最大の特徴は、3名の話者がまるで日常会話のように自然に、そしてコメディタッチで会話している点です。これにより、AIは以下のような多人数対話特有の複雑な要素を効率的に学習できます。
-
重なり発話や割り込み: 複数の人が同時に話したり、相手の発言を遮って話し始めたりする、実際の会話で頻繁に起こる状況を再現しています。
-
テンポのある応答: 会話のテンポが速く、間髪入れずに応答するような、自然な会話の流れが収録されています。
-
話題転換: 会話の中で話題が自然に、かつ多様に変化していく様子が捉えられています。
これらの特徴を持つデータセットは、音声認識(ASR)、会話理解、対話生成、話者追跡など、多人数対話を対象とするAI領域の研究・開発において、非常に価値のある学習・検証データとなります。
データセットの詳細スペック
今回提供が開始された「日本語・3話者・コメディテーマトーク音声コーパスデータセット」の具体的な内容は以下の通りです。
| データ種別 | 音声 |
|---|---|
| 被写体属性 | 20代〜50代の男女 |
| データ形式 | mp3 / wav |
| 収録時間 | 計約100時間(1音声約20分〜30分) |
| 音声レート | 44.1kHz |
| 対象のシーン | ・3名によるコメディ調の雑談や掛け合い、エピソードトークのシーン ・テンポのある応答や即興的な発言、自然な間合いを含む対話シーン ・話題が自然に遷移し、重なり発話や割り込みが発生する多人数会話シーン ・台本に依存しない、自発的な話題展開や感情変化がみられる自然対話シーン |
| 話題例 | 恋愛相談、思い出話(初恋、笑える失敗談など)、マイブーム、趣味、流行、好きなお菓子について、など全約200話題 |
このデータセットのサンプル詳細はこちらで確認できます。
サンプル詳細
多様なAI開発を加速するユースケース
このデータセットは、AIの研究から産業応用、さらには教育現場まで、幅広い分野での活用が期待されています。具体的なユースケースを見ていきましょう。
研究用途:多人数会話のメカニズム解明に貢献
AIの研究者にとって、このデータセットは多人数会話の複雑なメカニズムを解明するための貴重な資源となります。
-
多人数会話における話者分離・話者推定研究: 3話者が同時に発話したり、割り込んだりする自然な音声データは、AIが誰がいつ話しているかを識別する「話者分離」や「話者推定」モデルの性能検証に役立ちます。例えば、会議中に誰がどの発言をしたかを正確に記録する技術の精度向上につながります。
-
自然対話理解・会話行動分析研究: コメディ的なテンポや即興性、自然な話題転換を含むため、AIが会話の構造やターンテイキング(発話交替)、話題の遷移を理解する研究素材として活用できます。これにより、より人間らしい会話の流れを予測し、適切なタイミングで応答するAIの開発が進むでしょう。
-
自然言語処理 × 音声処理のマルチモーダル対話研究: 音声の特徴と自然言語処理を組み合わせることで、AIがより深い対話理解や生成を行う研究が可能です。例えば、話者の感情や意図を音声から読み取り、それに応じた対話生成モデルや発話予測モデルの学習データとして使用できます。
産業用途:ビジネス現場のAIソリューションを強化
ビジネスの現場では、多人数対話に対応するAIソリューションへの期待が高まっています。このデータセットは、これらのAIの性能向上に直結します。
-
多人数会話対応の音声認識(ASR)エンジン開発: 重なり発話や割り込みを含む3話者データは、会議AIや音声議事録生成AI、カスタマーセンター向け対話AIなど、実際のビジネス環境を想定した音声認識(ASR)エンジンの精度向上に活用できます。これにより、より正確な議事録作成や顧客対応が可能になります。
-
対話型AI(音声エージェント・アシスタント)の自然対話生成: テンポのある掛け合いデータは、対話生成モデルの自然さ、応答の多様性、リアクション生成の精度改善に寄与します。これにより、ユーザーはAIとの会話をより自然でストレスなく行えるようになり、満足度の高いサービス提供が期待できます。
-
マルチスピーカー音声処理技術の検証: 音声分離、話者追跡、音量・位置推定など、複数話者状況を前提とした音声処理アルゴリズムの開発に活用できます。例えば、スマートスピーカーが複数の声を聞き分け、それぞれの指示に対応する技術の基盤となるでしょう。
その他実需要:教育現場での活用
教育機関においても、このデータセットは音声工学や自然言語処理の教材、演習データとして利用可能です。学生が実際の多人数会話データを分析し、AI開発の基礎を学ぶ上で貴重なリソースとなるでしょう。
Qlean Dataset(キュリンデータセット)について
「Qlean Dataset」は、Visual Bank株式会社の100%子会社である株式会社アマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。AI開発の現場では、質の高い学習データを収集・整備するのに大きな労力とコストがかかります。Qlean Datasetは、この課題を解決するために開発されました。
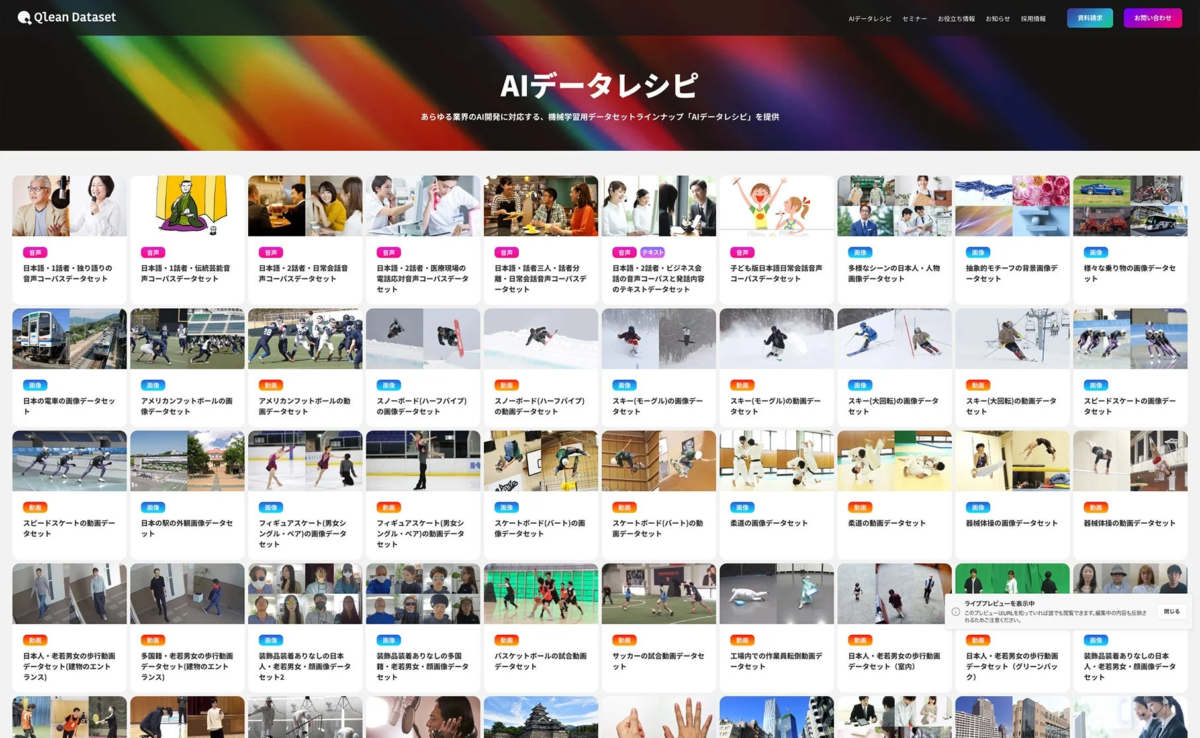
Qlean Datasetは、画像・動画・音声・3D・テキストなど、多様な形式のデータに対応しており、研究用途から商用用途まで、あらゆるAI開発で安全に利用できる環境を提供しています。特に、著作権や肖像権などの権利処理が済んでいるため、法的リスクを心配することなく利用できる点が大きな強みです。
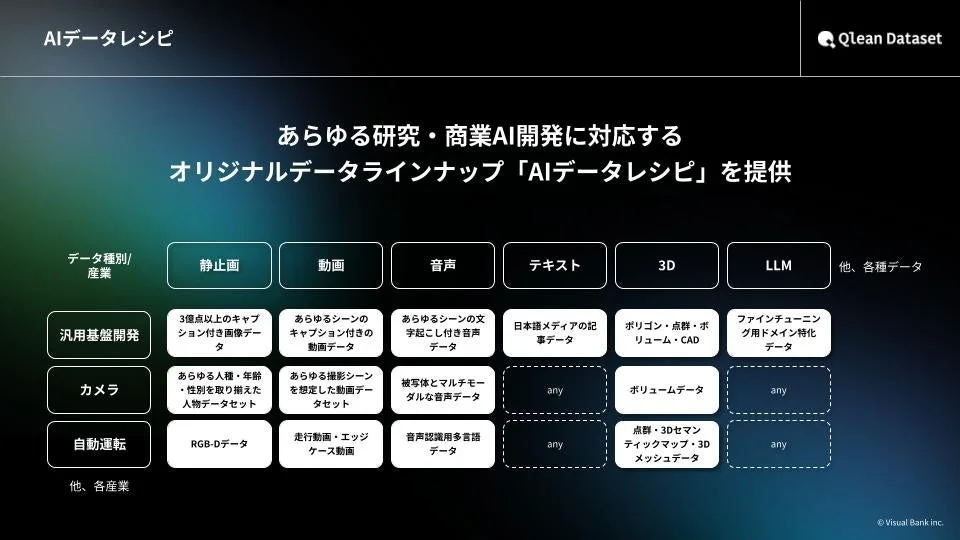
さらに、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。これにより、AI開発現場におけるデータ収集・整備の負荷を軽減し、より効率的で法的リスクのないAI開発環境の構築を支援しています。

Qlean Datasetの主な強み
Qlean Datasetは、以下の4つの強みでAI開発をサポートします。
- 安価かつスピーディーなデータ提供: 初期投資を抑えつつ、必要なデータを迅速に調達できます。
- 多様なデータ形式や構成にカスタマイズ: 画像、動画、音声、3D、テキストなど、さまざまなデータ形式に対応し、開発要件に応じたカスタマイズが可能です。
- AIデータレシピにないデータも拡充: 既存のラインナップにない独自性の高いデータも、顧客の要件に合わせて準備・提供できます。
- 権利処理済みで商用利用も安心: 著作権や肖像権などの権利クリアランスが徹底されており、AI倫理や法制度の最新状況にも対応しているため、研究・商用問わず安心して利用できます。

-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家を支援するAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持つなど、多角的にAI事業を展開しています。
同社は、国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。AIとデータの可能性を追求し、社会に貢献していくその姿勢は、今後のAI業界において注目される存在となるでしょう。
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/
まとめ:AIがより賢く、人間に寄り添う未来へ
Qlean Datasetが提供を開始した「日本語・3話者・コメディテーマトーク音声コーパスデータセット」は、多人数対話AIの開発における大きな一歩となるでしょう。このデータセットにより、AIはより複雑で自然な会話のニュアンスを理解し、まるで人間同士の会話のようにスムーズなやり取りができるようになることが期待されます。
AIが私たちの生活やビジネスにより深く浸透し、より賢く、そして人間に寄り添う存在となる未来は、このような質の高い学習データによって支えられています。今後もQlean Datasetが提供する「AIデータレシピ」の拡充に注目し、AI技術のさらなる進化に期待しましょう。