AI開発の新たな扉を開く「方言独り語り音声データ」
AI技術の進化は目覚ましく、私たちの生活に深く浸透しつつあります。特に音声認識や音声言語モデル、生成AIといった分野では、より自然で人間らしいコミュニケーションの実現が期待されています。しかし、これらのAIが直面する大きな課題の一つに「方言」があります。日本には多様な方言が存在し、標準語を学習したAIだけでは、方言話者の音声を正確に認識したり、自然な方言で応答したりすることが難しいのが現状です。
そんな中、Visual Bank株式会社のAI学習用データソリューション『Qlean Dataset(キュリンデータセット)』が、この課題解決に貢献する画期的なデータセットの提供を開始しました。それが『日本語・1話者・地域の方言の独り語り音声データ』です。この新しいデータセットは、日本各地の方言話者が一人で語る音声を収録したもので、AIが方言を理解し、適切に処理するための重要な基盤となります。本記事では、このデータセットがどのようなもので、なぜAI開発においてこれほどまでに重要なのか、そして具体的な活用方法について、AI初心者にも分かりやすい言葉で詳しく解説していきます。

Qlean Datasetとは?AI学習用データの重要性
AI(人工知能)を開発するためには、大量かつ高品質な「学習用データ」が不可欠です。AIは、この学習用データを分析することでパターンを認識し、推論や予測を行う能力を身につけます。例えば、画像認識AIには大量の画像データ、音声認識AIには大量の音声データが必要になります。データの質がAIの性能を大きく左右するため、学習用データの選定や準備はAI開発において非常に重要な工程です。
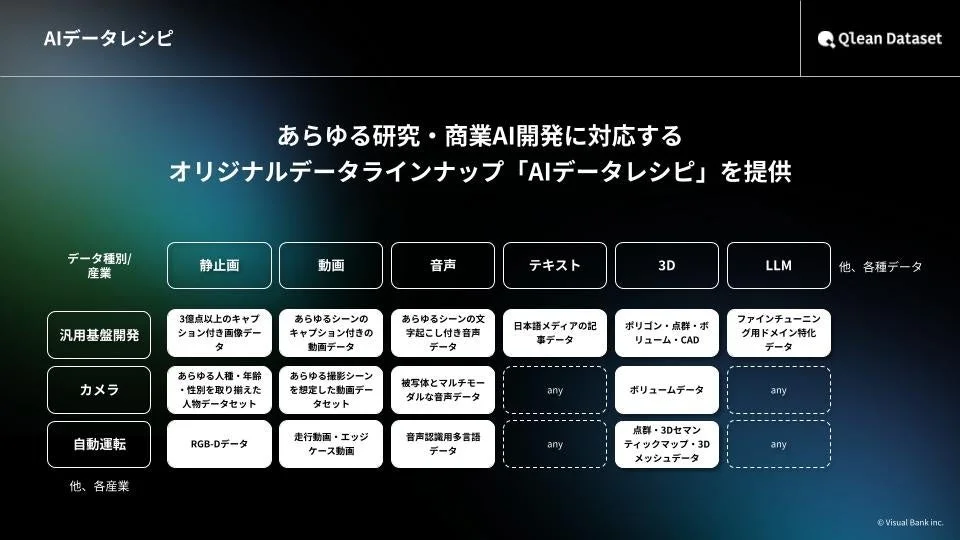
Visual Bank株式会社が株式会社アマナイメージズを通じて展開する『Qlean Dataset』は、このようなAI開発現場のニーズに応えるAI学習用データソリューションです。画像、動画、音声、3D、テキストといった多様な形式のデータを、研究用途から商用利用まで安全に活用できる形で提供しています。特に、著作権や肖像権といった権利処理が適切に行われている点は、法的リスクを避けたい企業にとって大きなメリットとなります。
Qlean Datasetは、千葉ロッテマリーンズや東洋経済新報社といったデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータラインナップ『AIデータレシピ』を継続的に拡充しています。これにより、AI開発者はデータ収集や整備にかかる手間を大幅に削減し、より本質的なAI開発に注力できるようになります。
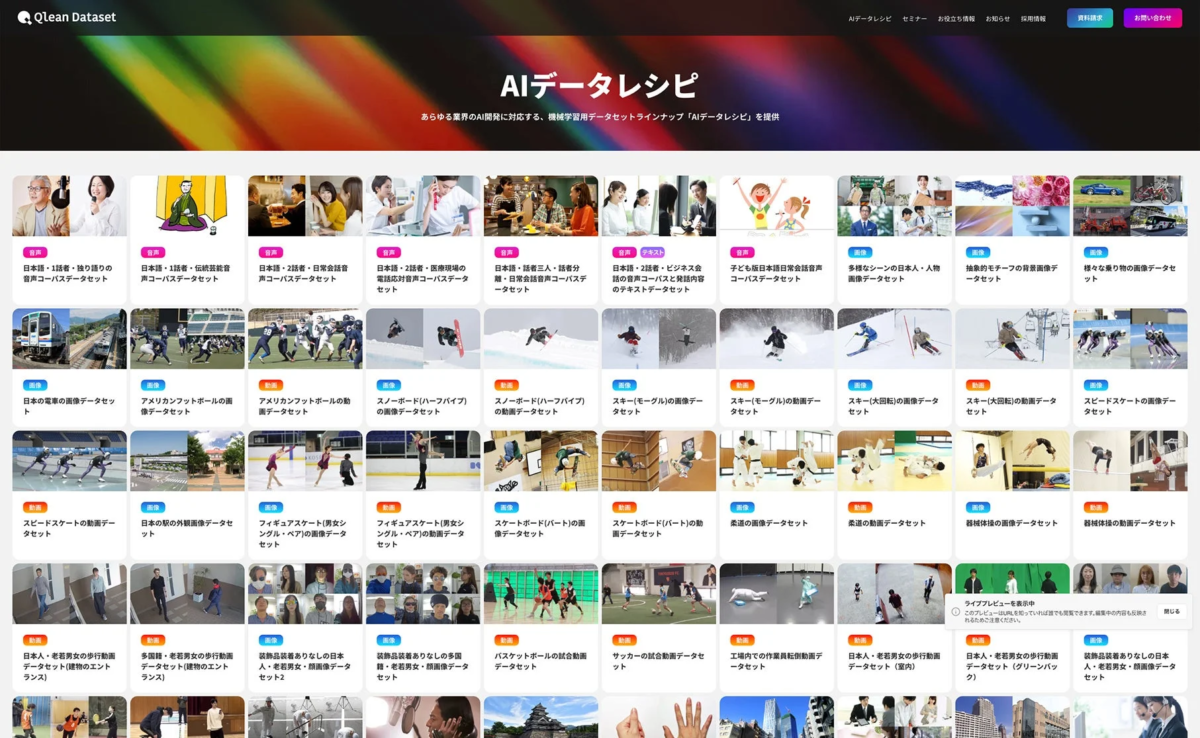
新データセット「日本語・1話者・地域の方言の独り語り音声データ」の全貌
今回Qlean Datasetが新たに提供を開始した『日本語・1話者・地域の方言の独り語り音声データ』は、AIデータレシピの一つとして追加されました。このデータセットは、その名の通り、日本の様々な地域の方言を話す人が一人で語る音声を収録したものです。
データセットの具体的な内容
このデータセットには、以下のような特徴があります。
-
被写体属性: 日本人の20代〜60代の男女が話者となっています。
-
方言種類: 関西弁、岡山弁、伊予弁、土佐弁など、日本各地の地域的な特徴を持つ方言が収録されており、今後も随時拡充される予定です。これにより、特定の地域の方言に特化したAI開発も可能になります。
-
収録内容: 日常的な話題や、話者自身の考えについて一人で語る音声が中心です。台本をベースとしながらも、自然な発話のリズムや間、そして地域特有の言い回しが豊富に含まれている点が大きな特長です。これにより、よりリアルな環境でのAI性能評価が可能になります。
-
データ形式: mp3またはwav形式で提供され、音声レートは44.1kHz、48kHz/16bit、24bitと高品質です。
-
収録時間: 合計で数百時間にも及び、1音声あたり約10分程度の長さで構成されています。
このデータセットのサンプルは、以下のQlean Datasetサイトから詳細を確認できます。
日本語・1話者・地域の方言の独り語り音声データ サンプル詳細
また、研究や検証用途での利用を想定して提供されるだけでなく、開発目的や要件に応じて、音声データの設計や新規収録にも柔軟に対応するとのことです。これにより、AI開発者は自身のプロジェクトに最適なデータを手に入れることができます。
なぜ方言音声データがAI開発に重要なのか?
私たちが普段話す言葉には、住んでいる地域によって異なる「方言」というものがあります。AIが人間の言葉を理解するためには、この方言の存在を無視することはできません。標準語(共通語)だけを学習したAIは、方言を話す人の言葉を聞いたときに、うまく認識できなかったり、間違った解釈をしてしまったりする可能性があります。
標準語中心のAIの限界
現在の多くの音声認識システムや音声言語モデルは、標準語を基にしたデータで学習されています。そのため、コールセンターや音声アシスタントなど、さまざまな人が利用する場面で、方言話者の音声に対して認識精度が低下するという問題が起こりがちです。これは、方言には標準語とは異なる音の高さ(イントネーション)やリズム、単語、言い回しが存在するためです。
方言音声データがもたらすメリット
今回提供される方言音声データは、このような標準語中心のAIの限界を克服し、より実用的なAIを開発するために非常に重要な役割を果たします。具体的には、以下のようなメリットが期待されます。
-
認識精度の向上: 方言を含む多様な音声データをAIに学習させることで、地域差による音韻(おんいん:言葉の音の最小単位)の違いや発話の傾向をAIが理解できるようになります。これにより、方言話者の音声でも高い精度で認識できるようになります。
-
汎化性能(はんかせいのう)の評価: AIが未知のデータに対しても適切に処理できる能力を「汎化性能」と呼びます。方言音声データを用いることで、AIが方言を含む様々な音声入力に対して、どれだけ柔軟に対応できるかを評価し、改善に役立てることができます。
-
自然な方言でのAI応答: 音声合成技術において、方言特有の抑揚やリズム、文末のイントネーションを学習させることで、より自然で人間らしい方言でのAI応答が可能になります。これは、地域に根ざしたサービスやエンターテインメント分野で特に需要があるでしょう。
このように、方言音声データは、AIがより多様な言語環境に対応し、私たちの生活に寄り添う存在となるための「架け橋」となるのです。
「日本語・1話者・地域の方言の独り語り音声データ」の具体的なユースケース
この新しいデータセットは、幅広い分野でのAI開発に活用できます。ここでは、主なユースケースを詳しく見ていきましょう。
研究用途での活用
-
日本語音声認識における方言対応研究
- 詳細: 地域ごとの方言音声を用いることで、標準語中心の学習データでは捉えにくい音韻差や発話傾向を含んだ音声認識モデルの評価が可能です。例えば、ある方言が特定の音をどのように発音するか、AIがその違いをどれだけ正確に認識できるかを検証できます。方言や話者条件を指定した音声を用いることで、地域差が認識精度に与える影響やモデルの挙動を比較・検証するのに役立ちます。
-
音声言語モデルの汎化性能評価
- 詳細: 単一話者による比較的長時間の発話音声を用いることで、方言を含む音声入力に対する音声言語モデルの汎化性能や、特定の条件下での挙動を評価できます。これにより、様々な環境下で安定した性能を発揮できるAIモデルの開発につながります。
-
方言音声合成における韻律・イントネーション分析
- 詳細: 方言特有の抑揚やリズム、文末イントネーションを含む音声を用いて、音声合成モデルがこれらの要素をどれだけ自然に表現できるかを学習・評価できます。これにより、より自然で感情豊かな方言での音声合成が可能になります。
産業用途での活用
-
方言対応型音声認識システムの開発
- 詳細: コールセンターや音声入力UI(ユーザーインターフェース)、業務支援システムなどにおいて、地域話者を想定した音声認識モデルの学習・検証に活用できます。例えば、特定の地域からの問い合わせが多いコールセンターで、その地域の方言を認識できるシステムを導入することで、顧客対応の質を向上させることができます。利用環境に即した条件設定により、実運用を想定した精度検証が可能です。
-
日本語音声モデルの用途別データ設計
- 詳細: 標準語に加えて方言音声を取り入れることで、日本語音声モデルの対応範囲を拡大し、特定の用途に応じた性能評価に活用できます。例えば、観光案内AIであれば、訪れる地域の主要な方言に対応させることで、より親しみやすいサービスを提供できます。用途に応じて話者数や発話パターンを整理した音声データ設計にも対応します。
-
方言音声を用いた音声合成・対話AIの検証
- 詳細: 方言話者による独り語り音声を基に、音声合成モデルや対話AIが生成する音声出力の自然性やイントネーション制御を検証できます。これにより、例えば地域のキャラクターを用いた対話型AIや、地域情報を提供する音声ガイドなどで、より高品質な方言音声を提供できるようになります。
その他実需要(教育・研修用途)
-
音声処理・音声AI教育向け教材
- 詳細: 方言を含む実際の音声データとして、音声認識、音声合成、音声言語モデルを学ぶ際の教育・演習用途に利用できます。学生や研究者が方言の持つ多様性や、それがAIに与える影響を実践的に学ぶための貴重な教材となるでしょう。地域差や話者条件を踏まえた教材設計にも活用可能です。
これらのユースケースは、AI技術がより多様な人々のニーズに応え、社会に深く貢献していくための道筋を示しています。
Qlean Dataset「AIデータレシピ」の強み
Qlean Datasetが提供する『AIデータレシピ』は、AI開発におけるデータに関する様々な課題を解決するための強力なソリューションです。その強みは多岐にわたります。
-
権利処理済みの安全なデータ: AI学習用データは、著作権や肖像権といった権利の問題が常に伴います。Qlean Datasetのデータはすべて被写体から同意を取得し、権利処理が適切に行われているため、研究用途はもちろん、商用利用においても安心して利用できます。これにより、開発者は法的リスクを心配することなく、AI開発に集中できます。
-
多様なデータ形式と柔軟な対応: 画像、動画、音声、3D、テキストなど、AI開発に必要なあらゆる形式のデータに対応しています。また、既存のデータセットは最短1日で納品可能であり、さらにAIデータレシピにないデータでも、顧客の特定の要件に応じてカスタム撮影・収録・収集を行うことで、独自のデータセットを構築することも可能です。これにより、ニッチな分野や特定の目的に特化したAI開発も強力にサポートします。
-
AI開発現場の負荷軽減: データ収集やアノテーション(データにタグ付けや注釈を付ける作業)は、AI開発において時間とコストがかかる工程です。Qlean Datasetは、これらの作業を代行し、高品質なデータを提供することで、開発現場の負荷を大幅に軽減します。
-
スケーラブルなデータ提供: 数百万から億単位といった大規模なデータセットの提供にも対応しており、大規模なAIプロジェクトにも対応できる体制が整っています。

Qlean Datasetは、権利クリアで法的リスクのないAI開発環境の構築を支援し、AI開発の可能性を広げるための重要なパートナーとなるでしょう。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、漫画家の創作活動を支援するAI補助ツール『THE PEN』の提供や、本記事で紹介しているAI学習用データセット開発サービス『Qlean Dataset』を展開する株式会社アマナイメージズを100%子会社に持つなど、AIとデータの分野で多角的な事業を展開しています。
同社は、国の研究開発プログラム「GENIAC」にも採択されており、その技術力と社会実装への取り組みは高く評価されています。これにより、Visual Bankは社会の様々な課題をAIとデータで解決し、豊かな未来を創造することを目指しています。
まとめ:方言音声データが拓くAIの新たな未来
Visual Bank株式会社のQlean Datasetが提供を開始した『日本語・1話者・地域の方言の独り語り音声データ』は、AIが日本の多様な言語文化を理解し、より人間らしいコミュニケーションを実現するための重要な一歩となります。このデータセットを活用することで、AI音声認識の精度向上、音声言語モデルの汎化性能強化、そして自然な方言でのAI応答といった、これまでのAIでは難しかった課題の解決が期待されます。
AI技術が私たちの生活にますます深く関わる中で、地域の方言にまで対応できるAIの登場は、より多くの人々にとって使いやすく、親しみやすいサービスが生まれる可能性を秘めています。Qlean Datasetが提供する高品質なデータは、AI開発者にとって強力な武器となり、日本のAI技術の発展を加速させることでしょう。今後のAIの進化に、この方言音声データがどのような影響を与えていくのか、大いに注目が集まります。