
AIの感情理解を深める新境地!「日本人・2話者・感情対話音声データセット」で次世代AI開発が加速
近年、人工知能(AI)技術は目覚ましい進化を遂げ、私たちの生活やビジネスに深く浸透しています。特に、人間の言葉を理解し、自然な対話を行うAIの開発は、さまざまな分野で注目されています。しかし、AIが本当に人間らしいコミュニケーションを実現するためには、言葉の意味だけでなく、その裏にある「感情」を理解することが不可欠です。
このような背景の中、Visual Bank株式会社が提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、AIの感情理解能力を飛躍的に向上させる新たな一歩を踏み出しました。それが、今回提供が開始された「日本人・2話者・感情対話音声データセット」です。この革新的なデータセットは、音声認識(ASR)の精度向上はもちろんのこと、大規模言語モデル(LLM)やマルチモーダルAIにおける感情理解を最適化し、次世代のAI開発を強力に後押しすると期待されています。
なぜAIに「感情」の理解が必要なのか?
AIが私たちの指示を理解し、タスクをこなすことはすでに当たり前になりつつあります。しかし、AIとの対話で「なんだか事務的だな」「こちらの気持ちを理解してくれていない」と感じた経験はないでしょうか?これは、AIが言葉の意味は理解できても、その言葉に込められた感情やニュアンスを捉えきれていないことが原因です。人間同士のコミュニケーションでは、言葉だけでなく、声のトーン、速さ、抑揚といった「非言語情報」が感情を伝える上で非常に重要な役割を果たします。
例えば、カスタマーサポートの現場を考えてみましょう。お客様が「困っている」と話すとき、その声に怒りの感情が込められているのか、それとも悲しみの感情が込められているのかによって、オペレーターの対応は大きく変わるはずです。AIがこのような感情の機微を理解できるようになれば、より共感的で、パーソナルな対応が可能となり、顧客満足度の向上にも直結します。
「日本人・2話者・感情対話音声データセット」の概要
Visual Bank株式会社傘下の株式会社アマナイメージズが展開する「Qlean Dataset」から提供されるこのデータセットは、AIが人間の複雑な感情変化を伴うコミュニケーションを解析し、より高度な対話生成モデルを構築することを目的としています。

データセットの主な特徴
このデータセットは、従来の単一話者(一人で話す)による読み上げ音声データとは一線を画しています。その最も大きな特徴は、「2人の話者による対話形式」を採用している点です。これにより、実社会のコミュニケーションに不可欠な様々な音声的特徴を網羅しています。
-
対象者: 20代から70代までの幅広い年齢層の日本人ペア15組が参加しています。多様な年代の話し方や感情表現を学習することで、より汎用性の高いAIモデルの開発が期待できます。
-
感情の種類: 「エキサイト(興奮)」「怒り(anger)」「悲しみ(sorrow)」「喜び(joy)」の4種類の感情を込めた自然な対話が収録されています。これらの明確な感情ラベルが付与されていることで、AIは感情と音声の特徴を関連付けて学習することができます。
-
収録環境: スタジオ環境で収録されているため、非常にクリアな音質が確保されています。ノイズの少ない高品質なデータは、AIの学習精度を向上させる上で極めて重要です。
-
対話形式の重要性: 2人の話者が相互に影響し合う対話形式では、以下のような音声的特徴が捉えられています。
-
相槌: 会話中に相手の話を聞いていることを示す「うん」「はい」といった応答。これがあることで、AIは自然な対話の流れを学習できます。
-
感情の起伏: 喜びから悲しみへ、怒りから落ち着きへといった感情の変化や、その変化に伴う声のトーン、速さ、音量の変化。
-
話者間のイントネーションの同期: 会話の中で、話者同士の声の高さや抑揚が自然に合っていく現象。より人間らしい対話の再現に役立ちます。
-
-
データ詳細:
-
データ種別:音声
-
被写物属性:20代〜70代の日本人ペア15組
-
データ容量:10GB
-
データ件数:63ファイル
-
データ形式:mp3
-
感情:4種類 (エキサイト、怒り:anger、悲しみ:sorrow、喜び:joy)
-
収録時間:約15時間(1点あたり20分程度)
-
収録環境:スタジオ
-
その他:音声のビットレートなどのメタ情報も含む
-
このデータセットは、Qlean Datasetが提供するAI開発用オリジナルデータラインナップ「AIデータレシピ」の一つとして提供されており、個別のニーズに応じた追加収録や感情パラメーターの調整といったカスタマイズにも柔軟に対応できるのが強みです。
サンプル詳細はこちらをご覧ください。
https://qleandataset.visual-bank.co.jp/lineup/ds-051
「感情対話音声データセット」が拓くAI開発の未来
このデータセットは、AI開発における様々な分野で活用され、その精度と人間らしさを大きく向上させることが期待されます。具体的なユースケースを見ていきましょう。
研究用途での活用
-
音声感情認識(SER)モデルの精度検証:
音声感情認識(SER)とは、音声データから話者の感情を自動的に識別する技術のことです。このデータセットは、喜びや怒りといった感情ラベルが付与された対話データを含んでいるため、音声の基本的な周波数やスペクトル(音の波形の特徴)から感情を推定するアルゴリズムの学習や評価に非常に有効です。例えば、AIが人の声の高さや強さ、速さの変化を分析し、それがどの感情と結びついているかを学ぶことで、より正確な感情認識が可能になります。 -
対話における話者分離・特定技術の研究:
話者分離(Diarization)とは、複数の人が話している音声データから、誰がいつ話したかを区別する技術です。このデータセットは、2人の話者が交互に発話するクリアなスタジオ収録音声を提供するため、ノイズの少ない環境下での話者分離技術の向上に役立ちます。また、感情の変化が話者識別(誰が話しているかを特定する技術)にどのような影響を与えるかといった、より高度な研究にも活用できます。AIが会話の中で話者が交代するタイミングや、感情の変化を正確に捉えることで、複雑なグループ会話の分析も可能になるでしょう。
産業用途での活用
-
カスタマーサポート向け感情分析エンジンの開発:
コールセンターなどの顧客対応ログを解析するAIにおいて、顧客の声に含まれる不満(怒り)や満足(喜び)を自動で検知するモデルの教師データとして活用できます。これにより、応対品質の可視化や、感情に基づいて緊急度を判断しアラートを出す機能の実装に繋がります。AIが顧客の感情をリアルタイムで理解することで、オペレーターはより適切なタイミングで効果的なサポートを提供できるようになり、顧客満足度の向上と業務効率化の両方が実現します。 -
表現力豊かな音声合成(TTS)および対話AIの学習:
音声合成(TTS:Text-to-Speech)とは、テキスト情報を人間の音声のように読み上げる技術です。大規模言語モデル(LLM)と連携した音声対話システムにおいて、この感情対話データセットは、文脈(コンテキスト)に応じた適切な感情表現を生成するための参照データとして利用されます。これにより、AIキャラクターやバーチャルアシスタントが、ただ情報を読み上げるだけでなく、より人間らしい感情を込めた応答を可能にします。例えば、ユーザーが悲しんでいるときに優しい声で、喜んでいるときに明るい声で話すAIを開発できるようになります。
Qlean Dataset(キュリンデータセット)について
「Qlean Dataset」は、Visual Bank傘下の株式会社アマナイメージズが提供する、商用利用が可能なAI学習用データソリューションです。AI開発の現場では、質の高い学習データの確保が非常に重要ですが、その収集や整備には多大な時間とコスト、そして専門知識が必要です。Qlean Datasetは、この課題を解決するために、以下のような特徴を持つデータセットを提供しています。
-
多様なデータ形式: 画像、動画、音声、3D、テキストなど、AI開発に必要なあらゆる形式のデータに対応しています。
-
権利クリア: すべての被写体から同意を取得しており、著作権や肖像権などの権利処理が済んでいるため、研究用途だけでなく商用利用においても法的リスクを心配することなく安全に利用できます。
-
「AIデータレシピ」: 国内外のデータホルダーやメディア(ラジオ・新聞社・通信社など)との協業を通じて、業界に特化したデータや最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。これにより、AI開発者は常に最新かつ多様なデータにアクセスできます。
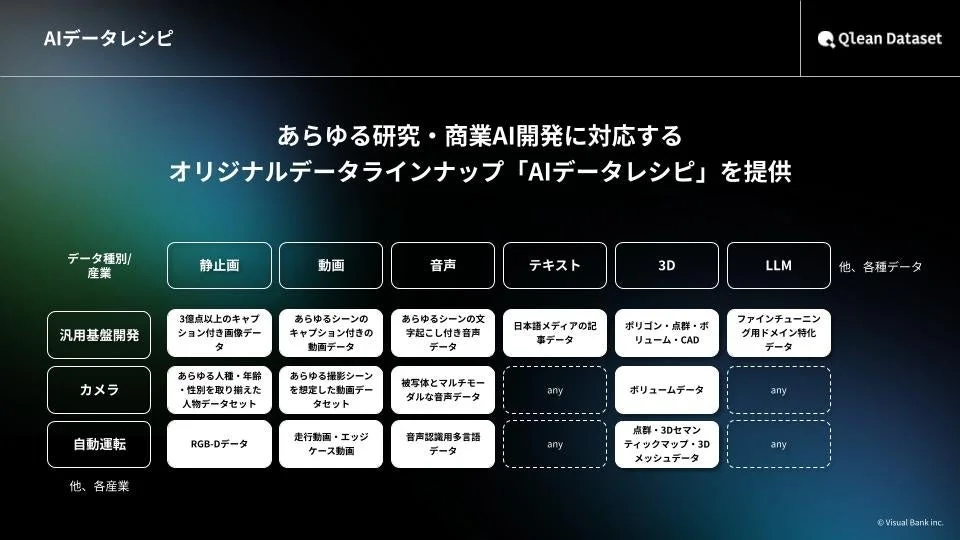
Qlean Datasetの特長
AI開発現場におけるデータ収集・整備の負荷を軽減し、質の高いAI開発環境の構築を支援するための様々な強みがあります。

- 安価かつスピーディーなデータ提供: 初期投資を抑えつつ、必要なデータを迅速に調達することが可能です。
- 多様なデータ形式や構成にカスタマイズ: 画像・動画・音声・3D・テキストなど、多岐にわたるデータ形式に対応し、個別の要件に応じたカスタマイズが可能です。
- 要件に応じた独自データの拡充: 「AIデータレシピ」にないデータであっても、顧客の具体的な要件に合わせて、独自データの準備や提供に対応します。これにより、特定のニッチな分野や先進的なAI開発にも対応できます。
- 権利処理済みで商用利用も安心: 著作権や肖像権などの権利クリアランスを徹底しており、研究・商用利用に完全に準拠しています。AI倫理や法制度の最新状況にも対応しているため、安心して利用できます。

Qlean Datasetサイト:
https://qleandataset.visual-bank.co.jp/
AIデータレシピ:
https://qleandataset.visual-bank.co.jp/lineup
お問い合わせ:
https://qleandataset.visual-bank.co.jp/contact
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、漫画家の創作活動をサポートするAI補助ツール『THE PEN』や、本記事で紹介しているAI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。これは、同社の技術力と将来性が高く評価されている証拠と言えるでしょう。
Visual Bank企業URL:
https://visual-bank.co.jp/
アマナイメージズ企業URL:
https://amanaimages.com/about/
まとめ
「日本人・2話者・感情対話音声データセット」の提供開始は、AIが人間の感情をより深く理解し、より自然で共感的なコミュニケーションを実現するための重要な一歩です。この高品質な構造データは、音声認識(ASR)や大規模言語モデル(LLM)、マルチモーダルAIといった最先端のAI技術の精度を一段と引き上げ、カスタマーサクセスのDX化から、より人間らしい応答が可能なAIキャラクター開発まで、幅広い分野でのイノベーションを加速させるでしょう。
AIがただ情報を処理するだけでなく、私たちの感情に寄り添い、真に役立つ存在となる未来は、このデータセットによってさらに近づくことが期待されます。AI初心者の方々も、この新しいデータセットがどのような可能性を秘めているのか、ぜひ注目してみてください。AI技術の進化は、私たちの想像を超えるスピードで進んでおり、感情を理解するAIがもたらす変化は、きっと社会の様々な側面で大きな影響を与えることでしょう。

