
AIの「耳」と「声」を育む!Qlean Datasetが「海外文学の朗読音声とトランスクリプト」を提供開始
近年、AI技術は私たちの生活に深く浸透し、その進化のスピードは目覚ましいものがあります。AIが賢くなるためには、大量かつ質の高い「学習データ」が不可欠です。まるで人間が言葉を学ぶように、AIも様々なデータから知識や能力を習得していきます。特に、音声認識や音声合成といった「音」に関わるAI、そして言葉の意味を理解するAIにとって、人間の発話とそれに対応するテキストデータは非常に重要な学習材料となります。
このような背景の中、AI学習用データソリューション「Qlean Dataset(キュリンデータセット)」が、新たな一歩を踏み出しました。Visual Bank株式会社傘下の株式会社アマナイメージズが展開するQlean Datasetは、この度「海外文学の朗読音声とトランスクリプト」の提供を開始。これは、AIの「耳」を鍛え、より自然な「声」を生み出すための、高品質な日本語データセットとして注目されています。

Qlean Dataset(キュリンデータセット)とは?
Qlean Datasetは、AI開発に必要な学習データを、安全かつ効率的に提供するソリューションです。画像、動画、音声、3D、テキストなど、多岐にわたる形式のデータを取り扱っており、研究用途から商用利用まで幅広く対応しています。AI開発において、学習データの収集や整備は大きな負担となることがありますが、Qlean Datasetは、権利処理が明確で法的なリスクがないデータを提供することで、開発現場の負担軽減とAI開発環境の構築を支援しています。

Qlean Datasetが提供するデータの大きな特徴は以下の通りです。
-
権利処理済みで安心: すべての被写体から同意を取得しており、著作権や肖像権などの権利クリアランスがされているため、研究・商用利用に安心して利用できます。
-
多様なデータ形式に対応: 画像、動画、音声、3D、テキストなど、AI開発に必要なあらゆる形式のデータを提供しています。
-
迅速な提供とカスタマイズ: 既存データは最短1日で納品可能であり、特定の要件に応じたカスタム撮影や収録、収集による独自データの構築にも対応しています。
-
AI倫理や法制度への対応: 最新のAI倫理や法制度の状況に準拠しており、安全なAI開発をサポートします。
新サービス:海外文学の朗読音声とトランスクリプトの全貌
今回提供が開始された「海外文学の朗読音声とトランスクリプト」は、AI学習用データラインナップ「AIデータレシピ」の一つとして加わります。このデータセットは、特に音声認識(ASR)の精度向上や、より自然な韻律を持つ音声合成(TTS)モデルの学習に最適化されています。
どのようなデータなのか?
このデータセットは、海外文学作品の日本語訳文を対象としています。物語の情景描写や思想的な一節を、一人の日本人話者が落ち着いた語り口で朗読した音声と、それに対応する正確なテキストデータ(トランスクリプト)で構成されています。

なぜこのデータが重要なのか?
翻訳文学には、日常会話とは異なる「書き言葉」としての特徴があります。格調高い文体、複雑な修飾関係、倒置法など、一般的な話し言葉ではあまり使われない表現が多く含まれています。このような特徴を持つ文章をAIに学習させることで、以下のような高度な能力の獲得が期待できます。
-
文脈を保持した長尺の音声解析: 長い文章でも、前後の文脈を理解しながら正確に音声をテキスト化する能力。
-
高度な語彙を伴う自然言語処理(NLP): 複雑な単語や表現を含む文章の意味を深く理解し、処理する能力。
-
一貫性のある発話品質: 物語性のある文章を、聴き取りやすく、感情を抑えつつも情景を想起させるような表現力で再現する能力。
データセットの具体的な内容
提供されるデータセットの概要は以下の通りです。
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 日本人 |
| データ形式 | 音声データ:mp3 |
| 収録時間 | 1音声30秒〜90分 |
| 音声レート | 44.1kHz / 48kHz |
| 対象のシーン | 海外文学作品の文章を日本語訳文として朗読するシーン |
より詳しいサンプルデータは、Qlean Datasetのウェブサイトで確認できます。
Qlean Dataset「海外文学の朗読音声とトランスクリプト」サンプル詳細
このデータセットで何ができる?具体的なユースケース
この「海外文学の朗読音声とトランスクリプト」は、様々なAI開発フェーズで活用が想定されています。AI初心者の方にも分かりやすいように、具体的なユースケースを詳しく見ていきましょう。
1. 研究用途:長尺文脈における音声認識モデル(ASR)の精度検証
音声認識(ASR)とは?
ASR(Automatic Speech Recognition)は、人間の音声をコンピュータがテキストに変換する技術です。スマートフォンの音声アシスタントや、議事録の自動作成などで活用されています。
なぜこのデータが役立つのか?
通常の会話と異なり、文学作品の文章は一文が長く、倒置法や複雑な修飾関係が含まれることがあります。このような文章をAIが正確にテキスト化するには、前後の文脈を深く理解する能力が必要です。このデータセットは、AIがどれだけ文脈を保持してテキスト化できるかを測定するための「ベンチマーク用データ」として利用できます。これにより、AIの音声認識モデルが、より複雑な日本語を理解する能力を向上させることができます。
2. 産業用途:ナレーション特化型・音声合成(TTS)エンジンの開発
音声合成(TTS)とは?
TTS(Text-to-Speech)は、テキストデータから人間の声のような音声を生成する技術です。カーナビの音声案内や、ニュース記事の自動読み上げサービスなどで使われています。
なぜこのデータが役立つのか?
エンターテインメント分野でのオーディオブック制作や、ニュース記事の自動読み上げサービスでは、単にテキストを読み上げるだけでなく、感情を抑えつつも聞き手に情景を想起させるような、高い表現力を持った合成音声が求められます。このデータセットは、文学作品の朗読という「表現力豊かな話し方」をAIに学習させるための「教師データ」として活用できます。これにより、より自然で魅力的なナレーションを生成するAIの開発が進むでしょう。
3. 教育・社会実装用途:日本語学習者向けの発音評価およびリスニング支援AI
なぜこのデータが役立つのか?
日本語を学ぶ外国人学習者にとって、正確な発音や自然なイントネーションの習得は非常に重要です。このデータセットは、標準的かつ丁寧な日本語発音の「正解データ(Ground Truth)」として利用できます。これを基に、外国人学習者の朗読に対する発音矯正AIを構築したり、視覚障害者向けの読書支援デバイスにおいて、自然で疲れにくい読み上げ機能を実装したりすることに貢献します。
4. 教育・社会実装用途:文学的コンテクストを理解するLLMのファインチューニング
LLM(大規模言語モデル)とは?
LLM(Large Language Models)は、膨大なテキストデータを学習することで、人間のように文章を理解し、生成できるAIモデルです。ChatGPTなどがその代表例です。
ファインチューニングとは?
ファインチューニングとは、あらかじめ学習された大規模なAIモデル(基盤モデル)を、特定の目的やタスクに合わせて少量の追加データで再学習させることです。これにより、モデルは特定の領域において、より高い精度や専門性を発揮できるようになります。
なぜこのデータが役立つのか?
論理的な構造を持つ文学作品の音声とテキストをペアで学習させることで、LLMは文学的な文脈や表現を深く理解できるようになります。これにより、例えば以下のような特化型モデルの調整に利用できます。
-
要約生成の精度向上: 長い文学作品でも、その本質を捉えた的確な要約を生成する。
-
文学的表現の翻訳精度向上: 詩的な表現や比喩など、翻訳が難しい文学特有の言い回しをより自然に翻訳する。
このデータセットは、小規模ながらも高品質なデータとして、特定の領域に特化したLLMの能力をさらに引き出すための重要な鍵となるでしょう。
「AIデータレシピ」について
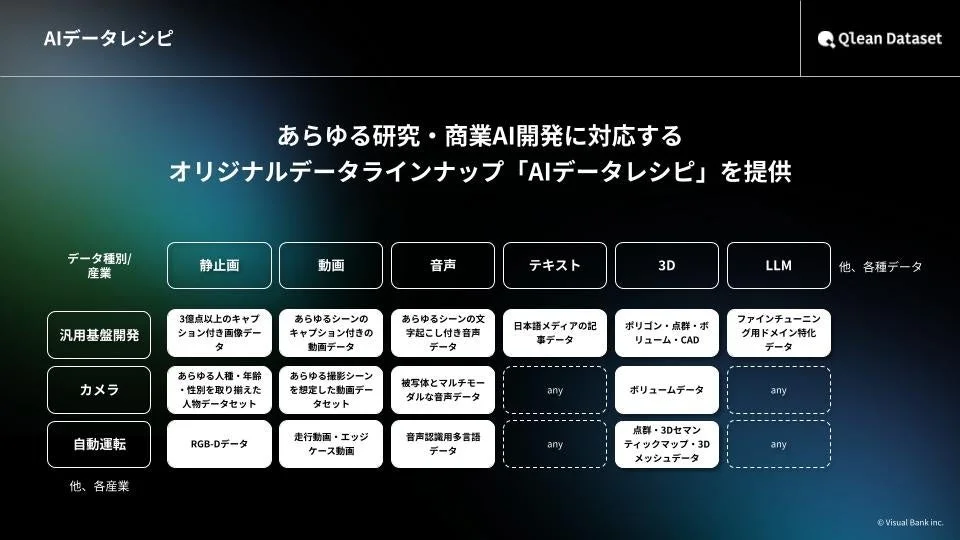
今回提供が開始された「海外文学の朗読音声とトランスクリプト」は、Qlean Datasetが提供するAI開発用オリジナルデータラインナップ「AIデータレシピ」の一つです。AIデータレシピは、あらゆる業界のAI開発に対応できるよう、画像、動画、音声、テキスト、3Dなど多様な形式のデータセットを提供しています。
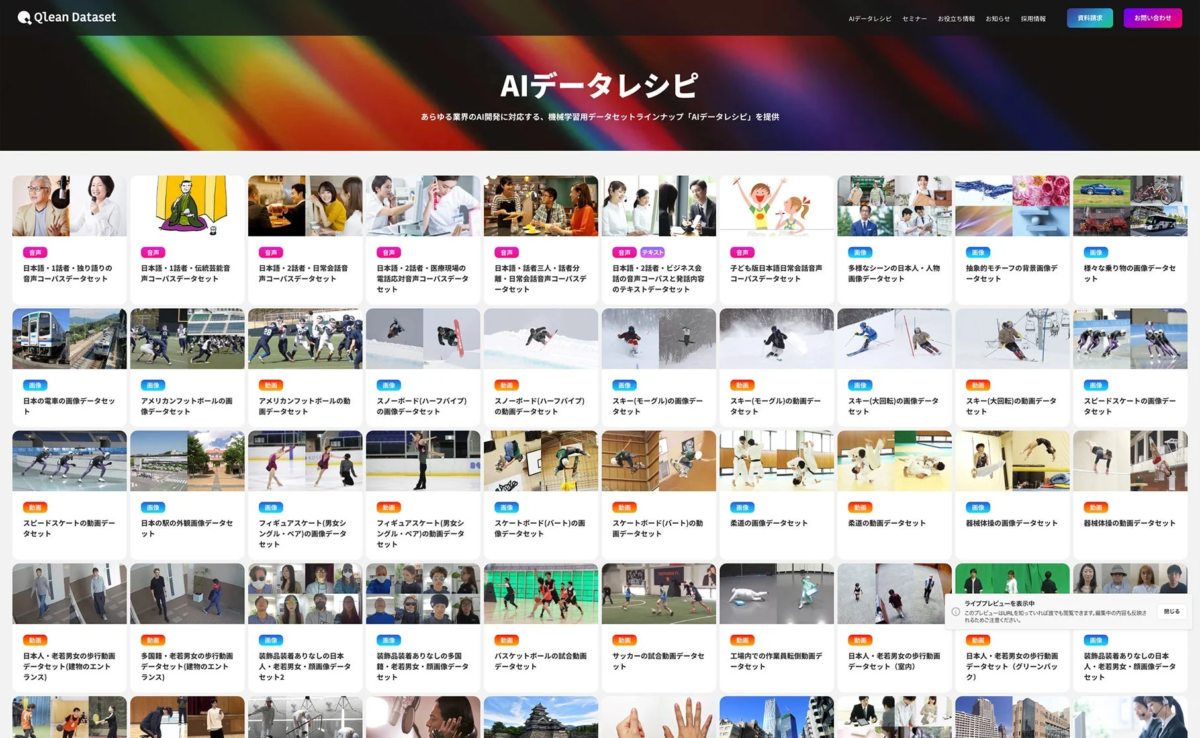
Qlean Datasetは、国内外のデータホルダーやラジオ・新聞社・通信社などのメディアとの協業を通じて、業界特化型や最新トレンドに即したデータラインナップを継続的に拡充しています。AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援することが、Qlean Datasetの使命です。
Qlean Datasetのウェブサイトでは、さらに詳しい情報やデータラインナップを確認できます。
Visual Bank株式会社とアマナイメージズについて
今回のデータ提供を行うVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラの構築・提供を行うスタートアップ企業です。漫画家向けのAI補助ツール『THE PEN』の提供も行っています。
Visual Bank株式会社は、株式会社アマナイメージズを100%子会社としており、アマナイメージズを通じてAI学習用データセット開発サービス『Qlean Dataset』を展開しています。また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
まとめ:AIの可能性を広げる高品質な日本語データ
Qlean Datasetが提供を開始した「海外文学の朗読音声とトランスクリプト」は、AIの音声認識や音声合成、そして大規模言語モデルの理解能力を飛躍的に向上させる可能性を秘めています。翻訳文学特有の高度な日本語表現を学習することで、AIはより複雑な文脈を理解し、人間にとって自然で表現力豊かな音声を生成できるようになるでしょう。
このデータセットは、オーディオブックの自動生成、高度な日本語学習支援、視覚障害者向けの読書支援、さらには文学作品の分析や翻訳といった、多岐にわたる分野でのAIの実用化を加速させることが期待されます。Visual Bankとアマナイメージズが提供するこのような高品質な日本語データは、国内外のAI研究・開発を力強く後押しし、これからのAIが社会にもたらす恩恵をさらに拡大させていくことでしょう。
AI技術の進化は、まさにこうした地道ながらも質の高いデータ収集と提供によって支えられています。今後のQlean Datasetの展開にも注目が集まります。

