
AI開発の新常識!Qlean Datasetが日本語ファッション・美容対話音声コーパスで音声認識・対話理解AIの進化を支援
AI(人工知能)技術の進化は目覚ましく、私たちの生活やビジネスのあらゆる側面に浸透しつつあります。特に、人間と自然に会話できる「対話型AI」の登場は、カスタマーサポート、教育、エンターテイメントなど、多岐にわたる分野で大きな変革をもたらしています。しかし、これらの高度なAIを開発するためには、膨大で質の高い「学習データ」が不可欠です。AIは、この学習データを分析することでパターンを認識し、人間のような判断や応答を学習していくからです。
Visual Bank株式会社が提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、このAI開発を支える重要な役割を担っています。この度、Qlean Datasetは、特に需要の高い「日本語・2話者・ファッション・美容テーマトーク音声コーパスデータセット」の提供を開始しました。本記事では、この新しいデータセットがどのようなもので、AI開発にどのような価値をもたらすのか、AI初心者にもわかりやすい言葉で詳しく解説していきます。
AI開発の鍵を握る「学習データセット」とは?
AIは、人間が与えた情報を基に学習する仕組みです。例えば、猫の画像をAIにたくさん見せることで、「これは猫である」と認識できるようになります。この「猫の画像」のような、AIが学習するために使う情報の集まりを「学習データセット」と呼びます。
学習データセットは、AIの性能を大きく左右する要素です。データセットの質が高く、量が豊富であるほど、AIはより正確で賢い判断ができるようになります。特に、音声認識や自然言語処理といった分野では、実際の会話に近い、多様な状況を網羅したデータが求められます。
Qlean Datasetは、画像、動画、音声、3D、テキストなど、さまざまな形式のAI学習用データセットを提供しており、AI開発者が直面するデータ収集・整備の負担を軽減し、権利関係もクリアな状態でAI開発を進められるよう支援しています。
ファッション・美容に特化した日本語対話音声データセットの登場
今回、Qlean Datasetが新たに提供を開始したのが、「日本語・2話者・ファッション・美容テーマトーク音声コーパスデータセット」です。このデータセットは、AIがファッションや美容に関する人間の会話をより正確に理解し、応答できるようになるための、非常に価値のあるデータです。

このデータセットの主な特徴は以下の通りです。
-
テーマ: ファッションや美容に特化しており、メイク、コーディネート、アイテム選び、流行といった具体的な話題が豊富に含まれています。
-
話者: 20代から50代までの男女2名が会話しています。これにより、性別や年代による話し方の違い、語彙、表現の多様性を学習できます。
-
会話の自然さ: 台本に厳密に依存せず、実際の会話に近い自然なテンポで対話が進められています。感想の共有、アドバイス、経験談などが交わされる、生きた会話が収録されています。
-
対話構造: 2話者間の発話の切り替わり、相互応答、話題の移り変わりといった、日常会話によく見られる複雑な対話構造が含まれています。
-
収録時間と形式: 合計約50時間もの音声が収録されており、1音声あたり約5分から60分の長さです。データ形式はmp3またはwav、音声レートは44.1kHzで提供されます。
このデータセットのサンプルは、Qlean Datasetのウェブサイトで確認できます。
Qlean Dataset「日本語・2話者・ファッション・美容テーマトーク音声コーパスデータセット」サンプル詳細
AI開発における具体的な活用シーン
この新しいデータセットは、AIの研究開発において多岐にわたる活用が期待されます。
研究用途での活用
-
対話音声における話者交代・応答構造の分析:
AIが人間同士の会話を理解する上で、誰がいつ話しているのか(話者交代)、そしてその発言が前の発言に対する応答なのかどうか(応答構造)を正確に把握することは非常に重要です。このデータセットは、2話者間の自然な会話を収録しているため、音声認識(ASR: Automatic Speech Recognition、人間の音声をテキストに変換する技術)や対話理解の研究において、これらの複雑な要素を分析し、AIモデルの評価や検証を行うのに役立ちます。 -
ドメイン特化対話コーパスを用いたNLP研究:
NLP(Natural Language Processing: 自然言語処理、人間の言語をコンピュータで処理する技術)の研究では、特定の分野(ドメイン)に特化した言語データを分析することが重要です。ファッションや美容といった特定のドメインに特化した語彙や表現を含むこの対話音声データは、言語的特徴の分析や、特定のドメインに適応したAIモデルを開発するための研究に利用できます。
産業用途での活用
-
音声対話型AIの学習データ:
ファッションや美容に関するサービス(例えば、オンラインのパーソナルスタイリストAI、メイクアップアドバイスチャットボットなど)を開発する際、このデータセットはAIの音声認識・対話理解モデルの学習データとして最適です。これにより、ユーザーがファッションや美容に関して話す内容をAIがより正確に理解し、適切な応答を生成できるようになります。 -
コールセンター・接客支援AIの対話理解検証:
ファッション・美容関連のコールセンターや店舗における接客支援AIの開発においても、このデータセットは有用です。商品提案やアドバイスを含む自然な対話音声が収録されているため、AIが顧客の意図をどれだけ正確に理解できるか、また、どれだけ自然で適切な応答ができるかを検証する際に活用できます。これにより、顧客満足度の向上や業務効率化に貢献するAIシステムの開発が加速します。
Qlean Datasetとは?AI開発を包括的に支援するソリューション
今回発表されたデータセットは、Visual Bank株式会社の子会社である株式会社アマナイメージズが提供するAI学習用データソリューション「Qlean Dataset」の一部です。Qlean Datasetは、AI開発におけるデータ収集・整備の課題を解決し、研究・商用問わず安全に利用できるAI開発環境の構築を支援しています。
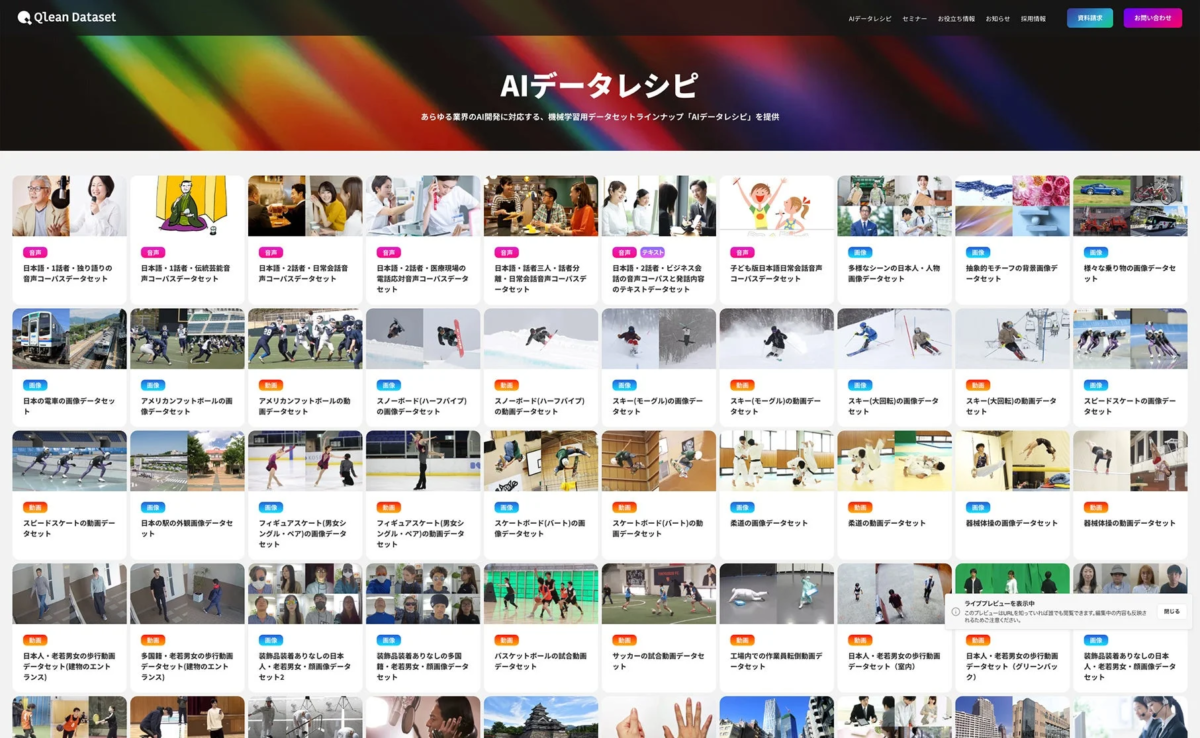
Qlean Datasetは、以下のような特徴を持つ「AIデータレシピ」というデータセットラインナップを提供しています。
-
多様なデータ形式: 画像、動画、音声、3D、テキストなど、AI開発に必要なあらゆるデータ形式に対応しています。
-
権利クリア: すべての被写体から同意を取得しており、著作権や肖像権などの権利処理が済んでいるため、研究用途だけでなく商用利用でも安心して利用できます。AI倫理や法制度の最新状況にも対応しています。
-
迅速な提供: 既存のデータセットは最短1日で納品が可能であり、AI開発のスピードアップに貢献します。
-
カスタム対応: 「AIデータレシピ」にない特定の要件を持つデータが必要な場合でも、カスタム撮影・収録・収集による独自のデータ構築に対応しています。これにより、企業独自のAI開発ニーズにも柔軟に応えることが可能です。
-
スケーラビリティ: 数百万から億単位といった大規模なデータポイントにも対応できるため、大規模なAIプロジェクトにも適しています。
Qlean Datasetは、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といった多様なデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータラインナップを継続的に拡充しています。AI開発現場におけるデータ収集・整備の負荷を軽減し、法的リスクのないAI開発環境の構築を支援することで、より多くの企業がAI技術を社会実装できるよう貢献しています。
Qlean Datasetの詳細については、以下のサイトをご覧ください。
Visual Bank株式会社について
Qlean Datasetを運営するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。
同社は、漫画家の創作活動を支援するAI補助ツール「THE PEN」を提供するほか、Qlean Datasetを提供する株式会社アマナイメージズを100%子会社に持っています。また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、AI技術の社会実装に向けた取り組みを加速させている注目の企業です。
Visual Bank株式会社の企業情報については、以下のサイトをご覧ください。
まとめ:AIが拓くファッション・美容の未来
今回Qlean Datasetが提供を開始した「日本語・2話者・ファッション・美容テーマトーク音声コーパスデータセット」は、ファッションや美容分野におけるAI開発を大きく前進させる可能性を秘めています。この高品質な学習データセットを活用することで、AIは人間の会話をより深く理解し、パーソナルなアドバイスやサポートを提供できるようになるでしょう。
AI技術は、私たちの生活をより豊かにし、ビジネスの効率を向上させる力を持っています。Qlean DatasetのようなAI学習用データソリューションは、その基盤を築く上で不可欠な存在です。これからも、AI開発を支えるデータソリューションの進化に注目していきましょう。ファッションや美容の領域でAIがどのような新しい価値を創出していくのか、今後の展開が非常に楽しみです。

