AI学習の精度を飛躍的に向上!LiLzと東北大学が開発した「量子アニーリング×データ浄化」の世界初技術を徹底解説
現代社会において、AI(人工知能)は私たちの生活やビジネスのあらゆる側面に浸透し、その進化は目覚ましいものがあります。AIが賢くなるためには、大量のデータから学習することが不可欠です。しかし、この学習プロセスにおいて、AIの性能を大きく左右する「データの質」という重要な課題が存在します。
LiLz株式会社と東北大学大学院情報科学研究科の大関真之教授らの研究グループが、このAI開発における長年の課題、特に「間違ったラベルの付いたデータ(ラベルノイズ)」を取り除く画期的な新技術を世界で初めて開発しました。この技術は、量子アニーリングとブラックボックス最適化という最先端の技術を組み合わせることで、AIの学習効率と精度を飛躍的に向上させると期待されています。本記事では、この革新的なデータセット浄化技術について、AI初心者にも分かりやすい言葉で詳しく解説します。
「ラベルノイズ」とは何か?AIの学習を妨げる見えない敵
AIが私たち人間のように「賢く」なるためには、たくさんの情報(データ)を学び、そこからパターンやルールを見つけ出す必要があります。例えば、「犬」の画像を認識できるAIを作る場合、AIには何千、何万という「犬」の画像と、それが「犬である」という情報(ラベル)をセットにして与え、学習させます。
このとき、もし「犬」の画像に誤って「猫」というラベルが付いていたらどうなるでしょうか?AIは間違った情報を学習してしまい、「この画像は犬なのに、ラベルは猫になっている。どっちが正しいんだろう?」と混乱してしまいます。このような、データに付与された情報(ラベル)が間違っている状態を「ラベルノイズ」と呼びます。
ラベルノイズがAIに与える悪影響
ラベルノイズは、AIの学習に深刻な悪影響を及ぼします。
- 学習の質の低下: AIは間違った情報も正しいものとして学習してしまうため、パターン認識の精度が落ちます。
- 汎化性能の低下: 「汎化性能」とは、学習したデータだけでなく、まだ見たことのない新しいデータに対しても正確に判断できる能力のことです。ラベルノイズが多いと、AIは特定のデータに過度に適合しすぎてしまい、未知のデータへの対応力が弱くなってしまいます。
- 信頼性の損失: 間違った判断を下すAIは、医療診断や自動運転など、高い信頼性が求められる分野では決して利用できません。AIの実社会での応用を妨げる大きな要因となります。
近年のAI開発では、扱うデータの量が非常に大規模になっています。このような膨大なデータの中から、人手で一つ一つラベルノイズを見つけて修正する作業は、途方もない時間とコストがかかり、現実的ではありませんでした。この課題が、AIのさらなる発展を阻む大きな壁となっていたのです。
世界初!量子アニーリングとブラックボックス最適化の融合
LiLz株式会社と東北大学の研究グループが開発したのは、この「ラベルノイズ」の問題を効率的に解決する画期的な技術です。彼らは、ブラックボックス最適化という手法と、量子アニーリングという最先端の量子技術を統合することで、AIの検証誤差を直接最適化し、ノイズフリーなデータセットを効率的に生成する枠組みを提案しました。これは、データクレンジングというAI開発の重要課題に量子技術を応用した世界初の実証例であり、AIの汎化性能を飛躍的に改善する可能性を秘めています。

量子アニーリングとは?複雑な問題を高速に解く魔法の技術
量子アニーリングは、量子コンピューティングの一種であり、特に「組合せ最適化問題」と呼ばれる種類の問題を解くことに特化した技術です。組合せ最適化問題とは、「たくさんの選択肢の中から、最も良い組み合わせを見つけ出す」という、従来のコンピュータでは計算に非常に時間がかかるような難しい問題のことです。
例えば、たくさんの都市を巡る最短ルートを探す「巡回セールスマン問題」などがこれに当たります。選択肢が増えれば増えるほど、計算すべき組み合わせは爆発的に増加し、どんなに高性能なスーパーコンピュータでも現実的な時間では解けなくなってしまいます。
量子アニーリングは、量子の特性(重ね合わせやトンネル効果など)を利用することで、このような膨大な組み合わせの中から、効率的に最適な解の候補を見つけ出すことができます。例えるなら、広大な山の中で最も低い谷(最適解)を探すときに、従来のコンピュータが一つ一つ道を辿っていくのに対し、量子アニーリングは一瞬で山の全体像を把握し、低い谷の候補にワープして効率的に探索を進めるようなイメージです。
本研究では、この量子アニーリングが、ラベルノイズを含む学習データセットの中から、「ノイズが少なく、AIの学習に最適なサブセット」を見つけ出すための強力なツールとして活用されています。
ブラックボックス最適化とは?中身が分からなくても最適な答えを探る方法
「ブラックボックス」とは、内部の仕組みが不明であったり、複雑すぎて解析が困難であったりするシステムを指す言葉です。例えば、私たちが車を運転するとき、エンジンの詳細な構造を知らなくても、アクセルを踏めば加速し、ブレーキを踏めば減速するという結果(出力)は分かります。ブラックボックス最適化は、このように内部構造が分からないシステムに対して、最適な入力(条件)を見つけ出すための手法です。
本研究におけるブラックボックス最適化は、以下のようなプロセスで機能します。
- 少量の検証データセットの用意: まず、ごく少量ではありますが、ラベルが正しく付与された「検証用データセット」を用意します。これは、AIモデルの性能を評価するための「正しい答え」の基準となります。
- 学習サブセットの選択とAIモデルの訓練: 大量の学習用データセットから、ある特定のデータの一部(サブセット)を選び出し、そのサブセットでAIモデルを訓練します。
- 検証誤差の評価: 訓練されたAIモデルが、先ほどの「正しい答え」である検証用データセットに対して、どれくらい正確な判断ができるか(検証誤差)を評価します。
- 「データの選び方」と「検証誤差」の関係を分析: 様々な「データの選び方」(学習サブセットの構成)と、それによって得られる「検証誤差」の関係性を分析します。この関係性は、まるで山の地形のように、最も低い谷(検証誤差が最小になるデータの選び方)があるはずです。
- 量子アニーラーによる最適な選び方の提案: ここで量子アニーリングが登場します。ブラックボックス最適化と組み合わせることで、過去の評価結果から「次にどの学習サブセットを選べば、検証誤差が最も小さくなるか」を効率的に予測し、新たな「データの選び方」を提案します。
- 繰り返しによる改善: この「評価」と「提案」のサイクルを繰り返すことで、徐々にラベルノイズが取り除かれた、より高品質な学習データセットへと最適化を進めていきます。
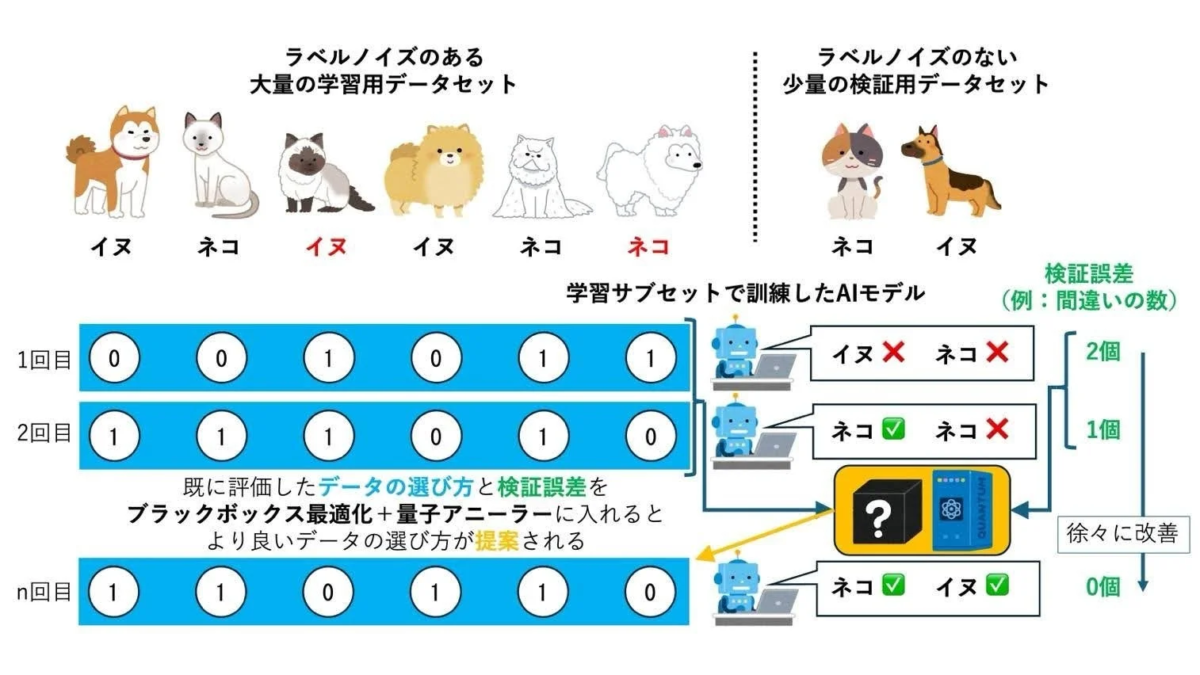
図1.提案手法の概念図。ラベルノイズのある学習用データセットから、正しくラベル付けされた少量の検証用データセットを用いてAIモデルの性能を評価し、その結果をブラックボックス最適化と量子アニーラーで分析。これにより、検証誤差が最も低くなる学習サブセットを効率的に見つけ出す。
このプロセスにより、従来は困難だった「組合せ的に膨大なデータ部分集合の探索」を量子アニーリングが効率的に実行し、良質な解を高速に得ることが可能になりました。
驚異の高速化を実現!AI開発を加速させるD-Wave Quantum社の量子アニーラー
研究グループが行った数値実験では、この新しいデータセット浄化手法が、誤ラベルによる悪影響が大きなデータを優先的に除去できることが示されました。さらに、この技術のもう一つの大きな成果は、処理速度の劇的な向上です。
D-Wave Quantum社の量子アニーラーを用いて実験を行った結果、古典的なシミュレータと比較して、実際の経過時間(ウォールタイム)でなんと約10倍〜100倍の高速化が実現したと報告されています。この驚異的な高速化は、AI開発の現場に以下のような大きなインパクトをもたらします。
-
開発期間の劇的な短縮: 大規模なデータセットの浄化にかかる時間が大幅に短縮されるため、AIモデルの開発サイクル全体が加速します。
-
開発コストの削減: 時間の短縮は、そのまま人件費や計算資源のコスト削減に直結します。
-
より複雑なAIモデルの開発: 従来は時間とコストの制約から諦めざるを得なかった、より大規模で複雑なAIモデルの開発が可能になります。
-
迅速な意思決定と市場投入: 高速に高品質なAIモデルを開発できるため、ビジネスにおける迅速な意思決定や、新しいAIサービスの市場投入を加速させることができます。
この高速化は、これまで人手や従来のコンピュータでは非現実的だった大規模データのクレンジングを可能にし、AI開発の新たなフロンティアを切り開くものと言えるでしょう。
AIの汎化性能を飛躍的に改善する意義
AIの「汎化性能」が優れていることは、そのAIが実世界で役立つかどうかを決定する非常に重要な要素です。例えば、病院で病気の診断を支援するAIがあったとして、それが学習したデータには完璧に対応できても、初めて見る患者さんのデータに対しては誤診してしまうようでは困ります。汎化性能が高いAIは、未知の状況や新しいデータに対しても、一貫して正確な判断を下すことができるのです。
今回開発されたデータ浄化技術は、ラベルノイズを効率的に除去することで、AIがより正確な情報のみを学習できるようになります。これにより、AIはデータの本質的なパターンを捉えやすくなり、その結果として汎化性能が飛躍的に向上します。これは、AIがより信頼性の高い、実用的なツールとして社会に貢献するための基盤を築くものです。
今後の展開:産業・医療分野への大きな期待
本研究で提案されたデータ浄化技術は、その革新性と実用性から、今後様々な分野での応用が期待されています。
-
産業分野における大規模実データの品質向上: 製造業における製品の品質検査、設備予知保全、サプライチェーン最適化など、大量のセンサーデータや画像データが生成される現場では、AIによる分析が不可欠です。しかし、これらのデータにはしばしばノイズが含まれており、AIの精度を低下させる原因となっていました。本技術の導入により、これらの実データの品質が向上し、より信頼性の高いAIシステムを構築できるようになるでしょう。
-
医療分野におけるAIの信頼性向上: 医療画像診断、新薬開発、ゲノム解析など、データの正確性が人命に直結する医療分野において、ラベルノイズの除去は極めて重要です。本技術は、AIによる診断支援や治療計画の最適化の精度を高め、医療の質の向上に貢献することが期待されます。
-
ラベルなしデータセットの品質向上: AIの学習には通常ラベル付きデータが必要ですが、ラベル付け作業はコストがかかります。将来的に、ラベルなしデータセットの品質向上にもこの技術が応用される可能性があります。
-
特徴量選択と組み合わせた学習データと特徴量の同時最適化: AIの学習において、どのデータを使い、どの特徴(データの性質)に注目するかは非常に重要です。本技術は、最適な学習データの選択だけでなく、特徴量の選択も同時に最適化することで、AIの性能をさらに引き出す可能性を秘めています。
LiLz株式会社は、「機械学習とIoTの技術融合で、現場の仕事をラクにする」というミッションを掲げています。今回の東北大学との共同研究も、このミッション実現に向けた重要な一歩であり、今後も学術機関との連携を通じて、様々な産業の現場課題を解決していくことが期待されます。
研究論文と関連情報
論文情報
-
タイトル:Filtering out mislabeled training instances using black-box optimization and quantum annealing
-
著者:Makoto Otsuka, Kento Kodama, Keisuke Morita, Masayuki Ohzeki
責任著者:LiLz 株式会社(研究員)・東北大学大学院情報科学研究科(客員研究員)・ 大塚誠 -
掲載誌:Scientific Reports
YouTube解説動画
東北大学大学院情報科学研究科
-
教授:大関真之
-
東北大学 プレスリリース:https://www.tohoku.ac.jp/japanese/2025/10/press20251031-02-quantum.html
-
東北大学 公式X:https://x.com/tohoku_univ/status/1984130629127360661
LiLz株式会社
-
所在地:沖縄県宜野湾市我如古2-3-7 2F
-
設立:2017年
-
代表:大西敬吾
-
URL:
-
公式HP:https://lilz.jp/
-
チーム紹介note:https://note.com/lilz/
-
-
事業内容:AIおよびIoT技術を活用したサービス提供、研究開発 等