
現代社会において、AIは私たちの生活に深く浸透し、スマートスピーカーや音声アシスタント、翻訳アプリなど、さまざまな場面でその恩恵を受けています。特に「音声AI」の進化は目覚ましく、より自然な会話や複雑な指示を理解するための技術開発が日々進められています。しかし、これらのAIが賢くなるためには、膨大な量の「学習データ」が不可欠です。AIはデータからパターンを学び、人間のように認識したり、判断したりする能力を身につけていきます。
Qlean Datasetが新たな日本語音声データセットを提供開始

この度、Visual Bank株式会社が展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、ASR(自動音声認識)、音声理解、そして音声とテキストを統合的に扱う基盤モデルの開発を支援するため、「日本語・1話者・サブカル・スピリチュアル系テーマの朗読音声コーパスとトランスクリプト」の提供を開始しました。
この新しいデータセットは、特定のテーマに焦点を当てることで、より専門的で深みのある日本語音声AIの開発を可能にする画期的なものです。AI開発者だけでなく、これからAIの学習データについて知りたいというAI初心者の方にも、その重要性を詳しくご紹介します。
サブカル・スピリチュアル系テーマに特化した日本語音声データとは?
Qlean Datasetが今回提供を開始したデータセットは、以下のような特徴を持っています。
-
テーマ: サブカルチャー、スピリチュアル、ヒーリングといった、思想や概念、内省的な内容を含むテーマに特化しています。
-
話者: 日本人話者一人が朗読しています。
-
語り口: 落ち着いた語り口で文章が連続的に読み上げられています。
-
構成: 音声データと、その発話内容を忠実に記録したトランスクリプト(文字起こしテキスト)で構成されています。
なぜ、このような特定のテーマに特化したデータセットが重要なのでしょうか?一般的な会話データでは捉えにくい、特定の分野で使われる専門用語、独特の言い回し、感情のニュアンスなどをAIが学習するには、その分野に特化したデータが非常に有効だからです。サブカルチャーやスピリチュアルといったテーマは、抽象的な概念や深い思索を含むことが多く、AIがこれらの言葉や表現を正確に理解し、生成するためには、このような専門的なデータが不可欠となります。
単一話者・朗読形式の利点
このデータセットの大きな特長の一つは、単一話者による朗読形式であることです。
-
単一話者: 複数の人が話すと、声の高さ、話し方、アクセントなどが異なるため、AIは話者の違いに気を取られてしまうことがあります。単一話者であれば、AIは話者の特性による影響を気にせず、純粋に「音声とテキストの対応関係」に集中して学習できます。これにより、より正確で安定したモデル評価が可能になります。
-
朗読形式: 会話音声とは異なり、朗読は文章の構造が明確で、構文や語彙の流れが一貫しています。これは、AIが日本語の文法構造や表現方法を深く学ぶ上で非常に有利です。例えば、AIが物語を読んだり、情報をナレーション形式で伝えたりする際に、より自然で人間らしい表現ができるようになるための基礎となります。
このように、単一話者による一貫した朗読音声と、その内容を正確に記録したテキストデータは、AIが言葉の意味だけでなく、その背景にある思想や概念までを理解する能力を養うための貴重な資源となります。
データセットの具体的な概要
提供されるデータセットの具体的な仕様は以下の通りです。
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 日本人 |
| データ形式 | 音声データ:mp3 テキストデータ:txt,json,csv |
| 収録時間 | 1音声30秒〜22分 |
| 音声レート | 44.1kHz / 48kHz |
| 対象のシーン | ・サブカルチャーや精神世界に関する文章を一人の話者が朗読するシーン ・落ち着いた語り口で思想や概念を読み上げる朗読シーン |
このデータセットのサンプルは、以下のリンクから確認できます。
サンプル詳細

広がるユースケース:研究から産業応用まで
この新しいデータセットは、AIの研究開発において幅広い用途での活用が期待されています。
【研究用途】
-
音声認識・音声理解モデルにおける朗読音声処理の検証
AIが人間の言葉を正確に聞き取り、その意味を理解する能力を「音声認識」や「音声理解」と呼びます。このデータセットは、日本語の朗読音声とそれに対応するテキストを利用することで、AIモデルが複雑な文章構造を持つ連続した発話をどれだけ正確に認識できるか、またどのような間違いをする傾向があるかを分析するのに役立ちます。例えば、AIが哲学書や詩を読み上げる際に、どこでつまずくか、どのように改善すべきかといった研究に活用できます。 -
音声と言語表現の対応関係に関する基礎研究
言葉には、単なる意味だけでなく、感情やニュアンス、話者の意図などが込められています。このデータセットに含まれる思想的・概念的な文章の朗読音声は、音の信号(声のトーン、速さなど)が言語表現や意味理解にどのように影響するかを研究するための貴重な材料となります。AIがより人間らしいコミュニケーションを取るために、音声と意味の深い関係性を探る基礎研究に貢献します。
【産業用途】
-
音声入力型AIアシスタントの音声認識精度評価
私たちの身近にあるAIアシスタント(スマートスピーカーやスマートフォンの音声入力機能など)は、ナレーションや読み上げのような形式の音声入力に対しても、正確に認識し、理解する能力が求められます。このデータセットは、そうしたAIプロダクトの音声認識や音声理解機能の精度を評価し、改善するための検証に利用できます。例えば、オーディオブックの読み上げ内容をAIが自動でテキスト化する際の精度向上に役立つでしょう。 -
音声×言語系基盤モデルのファインチューニング
「基盤モデル」とは、多様なタスクに対応できる汎用的なAIモデルの土台となるものです。「ファインチューニング」とは、この基盤モデルを特定の用途に合わせてさらに学習させることです。単一話者による朗読音声とテキストの対データは、音声とテキストを統合的に扱う、より高性能な基盤モデルを開発するための学習データとして非常に有効です。これにより、例えば、特定のジャンルのコンテンツ生成AIや、より高度な音声対話システムなどの開発が加速されると期待されます。
『Qlean Dataset』とは?AI開発を支えるデータソリューション
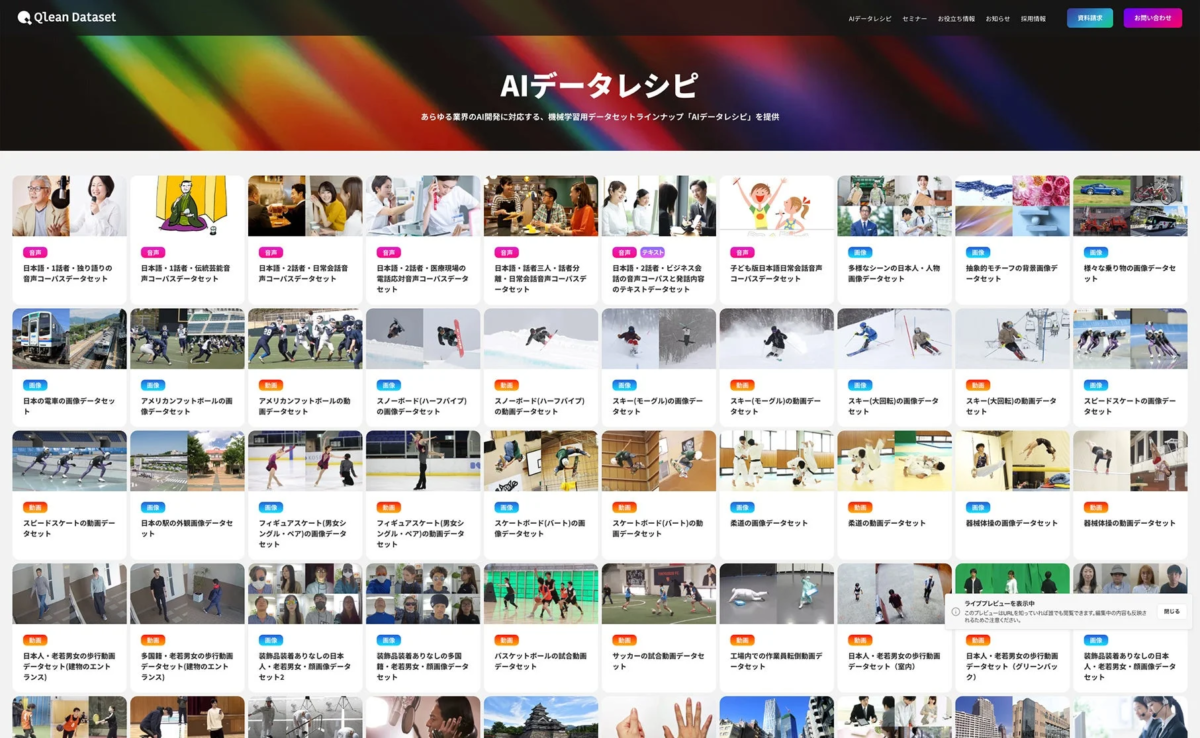
『Qlean Dataset』は、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。AI開発におけるデータの収集や整備は、時間とコストがかかるだけでなく、著作権や肖像権といった法的リスクの管理も非常に重要です。Qlean Datasetは、これらの課題を解決し、研究用途から商用利用まで、安全かつ効率的なAI開発環境を支援しています。
AIデータレシピ:多様なデータラインナップ
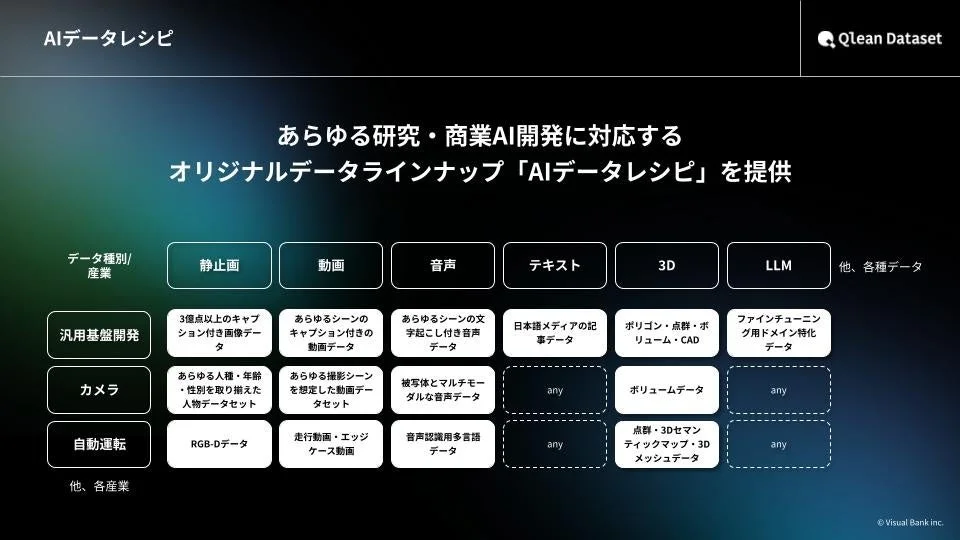
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多様な形式のデータに対応しています。その中でも、特に注目すべきは、AI開発用オリジナルデータラインナップ「AIデータレシピ」です。これは、様々な業界や用途に特化したデータセットを豊富に取り揃えており、今回の朗読音声データもその一つとして提供されます。
-
権利クリアで安心: すべての被写体から同意を取得し、著作権や肖像権などの権利処理が済んでいるため、商用利用でも安心して活用できます。
-
スピーディーな提供: 既存のデータセットは最短1日で納品可能であり、AI開発のスピードアップに貢献します。
-
カスタム対応: AIデータレシピにない、特定の要件に合わせた独自のデータ構築(カスタム撮影・収録・収集)にも柔軟に対応しています。

Qlean Datasetは、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といった多様なデータパートナーとの協業を通じて、常に最新のトレンドや現場のニーズに応じたデータラインナップを拡充しています。これにより、AI開発現場におけるデータ収集・整備の負担を大幅に軽減し、開発者はAIモデルそのものの開発に集中できるようになります。

Qlean Datasetの詳細は、以下のサイトで確認できます。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、漫画家の創作活動をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。このような先進的な取り組みを通じて、国内外のAI研究・開発を強力に支援しています。
まとめ:日本語音声AIの新たな地平を拓く
Qlean Datasetが提供を開始した「日本語・1話者・サブカル・スピリチュアル系テーマの朗読音声コーパスとトランスクリプト」は、AI開発、特に日本語の音声認識や言語モデルの分野に大きな進歩をもたらす可能性を秘めています。特定のテーマに特化し、単一話者による朗読形式を採用することで、AIはより深く、より正確に言葉の持つ意味やニュアンスを学習できるようになります。
これにより、将来的には、より人間らしい自然な対話が可能なAIアシスタントや、専門分野に特化した情報を提供するAIシステム、さらには感情や思想を表現できるコンテンツ生成AIなど、多岐にわたるAIアプリケーションの開発が加速することが期待されます。Qlean Datasetのような高品質なデータセットの提供は、AI技術の発展と社会実装を支える重要な基盤となるでしょう。
AIが私たちの生活をより豊かに、便利にする未来を創る上で、このような学習データの進化は不可欠です。Qlean Datasetの今後のさらなるデータラインナップの拡充にも注目が集まります。

