
AI(人工知能)は、私たちの生活のあらゆる場面でその存在感を増しています。スマートフォンで話しかけて情報を検索したり、文章の要約を自動で行ったりと、その応用範囲は広がるばかりです。しかし、これらのAIが賢く働くためには、質の高い「データ」が不可欠であることをご存知でしょうか。AIは、まるで人間が勉強するように、大量のデータからパターンを学び、知識を習得していきます。特に、人間の言葉を理解し、処理する「音声認識AI」や「自然言語処理AI」にとって、リアルな音声やテキストデータは学習の要となります。
このような背景の中、AI学習用データソリューション「Qlean Dataset(キュリンデータセット)」を提供するVisual Bank株式会社が、AI開発の新たな一歩を支援するデータセットの提供を開始しました。それが「日本語・1話者・レジャーテーマトーク音声コーパスとトランスクリプト」です。この新しいデータセットは、AIがより自然で人間らしいコミュニケーションを理解し、処理する能力を高めるための貴重な資源となるでしょう。
新たなAI学習の扉を開くデータセットの概要
Qlean Datasetから新たに提供される「日本語・1話者・レジャーテーマトーク音声コーパスとトランスクリプト」は、AI開発者にとって非常に魅力的なデータセットです。このデータセットは、趣味や娯楽といった「レジャー」をテーマに、一人の話者が台本なしで自由に語る日本語の音声と、その発話内容を正確に書き起こしたテキスト(トランスクリプト)で構成されています。
なぜ「一人語り」で「レジャーテーマ」が重要なのか?
このデータセットの最も大きな特徴は、「1話者」による「レジャーテーマトーク」である点です。通常の会話データとは異なり、一人が自身の体験や感想、特定の作品に対するレビューや考察などを、連続して自然に語る形式が採用されています。これは、実際のユーザーがインターネット上でレビューを投稿したり、友人や知人に体験談を話したりする際の、よりリアルな発話に近い形を再現していると言えるでしょう。
AIは、こうした「生きた」データを学習することで、以下のような高度な能力を習得することが期待されます。
-
長文の理解: 一人語りでは話題が連続して展開されるため、AIは長い文脈の中で情報を追跡し、理解する能力を養えます。
-
感情や評価の把握: 感想やレビューには、話者の感情や評価が豊富に含まれています。これにより、AIは単語の意味だけでなく、その裏にあるニュアンスや評価の方向性を学習できるようになります。
-
自然な表現の習得: 台本に依存しない自然な発話から、AIは人間が実際に使う言葉遣いや表現方法を学ぶことができます。これは、より人間らしい応答が可能なチャットボットや音声アシスタントの開発に繋がります。
このデータセットは、音声とテキストの両面からAIに学習させることで、音声認識の精度向上はもちろんのこと、テキストデータの分析を通じて自然言語処理の能力も飛躍的に高める可能性を秘めています。
データセットの詳細情報
提供されるデータセットの具体的な仕様は以下の通りです。AI開発者は、これらの詳細を参考に、自身のプロジェクトに最適な形でデータを活用できるでしょう。
-
データ種別: 音声データとテキストデータがセットで提供されます。
-
被写体属性: 20代から50代までの幅広い年代の男女が対象となっています。
-
データ形式: 音声は一般的なmp3形式で、テキストは書き起こし内容を記録した形式で提供されます。
-
収録時間: 合計で約600時間もの長時間にわたる音声が収録されており、1つの音声ファイルは約5分から40分の長さです。
-
音声レート: 44.1kHzという高音質で収録されているため、細かな音声の特徴もAIに学習させることが可能です。
-
対象シーン: レジャーに関する話題を中心に、話者が自身の体験や考えを一人で連続して語る日本語音声が収録されています。
このデータセットのサンプルは、Qlean Datasetのウェブサイトで確認できます。実際のデータがどのようなものかを知りたい方は、以下のリンクから詳細をご覧ください。
サンプル詳細
広がる活用シーン:研究からビジネスまで
この「日本語・1話者・レジャーテーマトーク音声コーパスとトランスクリプト」は、そのユニークな特性から、学術研究から実際のビジネス開発まで、幅広い分野での活用が期待されています。AI初心者の方にもイメージしやすいように、具体的な活用例をいくつかご紹介します。
研究用途での活用例
-
長文音声認識モデルの精度評価:
テーマパークでの体験談や雪道での歩き方、ドラマやテレビゲームに対する感想など、一人の話者が連続して話題を語る独話音声は、長時間にわたる発話における音声認識の精度を評価するのに非常に適しています。文脈が長く続く中でAIがどれだけ正確に音声をテキストに変換できるか、あるいはどのような誤認識が生じやすいのかといった傾向を詳細に分析することが可能です。 -
談話構造・語用論研究:
一人の話者が体験を振り返ったり、作品を評価したりする発話は、言語学的な研究においても価値があります。例えば、話題の導入から展開、評価、さらには補足説明へと移行する会話の構造や、感想、比較、注意喚起といった言葉の機能(語用的機能)がどのように現れるかを分析するのに利用できます。これにより、より自然で人間らしいAIの会話生成能力の向上に貢献できるでしょう。
産業用途での活用例
-
音声入力型アプリケーション向けASR(自動音声認識)開発:
テーマパークの楽しみ方、旅行時の注意点、ドラマやゲームの感想など、ユーザーが一人で話す場面を想定した音声入力機能を持つアプリケーションの開発に役立ちます。例えば、音声検索、音声メモ、レビュー入力といった機能において、より自然で正確な音声認識を実現するための学習データとして活用できます。 -
自然言語処理モデルのファインチューニング:
レジャー体験や作品レビューに関する発話テキストは、自然言語処理モデルの学習素材として非常に優れています。体験内容の要点抽出、評価ポイントの整理、話題や観点ごとの分類といった処理を行うAIモデルの精度向上に繋がります。これにより、顧客のレビューから自動でインサイトを抽出するシステムや、コンテンツの自動要約機能などを開発できます。 -
音声×テキスト連携AIの検証:
音声データと書き起こしテキストが正確に対応しているこのデータセットは、音声入力された内容をテキストとして解釈・処理するAIシステムの検証に最適です。音声理解とテキスト処理が連動する機能(例えば、音声で指示された内容をテキストで処理し、結果を音声で返すシステム)の精度確認や、機能改善のためのテストに利用することで、より高度なマルチモーダルAI(複数の種類の情報を扱うAI)の開発に貢献します。
Qlean Datasetとは?AI開発を支えるデータソリューション
今回のデータセットを提供する「Qlean Dataset」は、Visual Bank株式会社の傘下である株式会社アマナイメージズが展開する、商用利用可能なAI学習用データソリューションです。AI開発において高品質なデータが不可欠である一方、その収集や整備には多大な時間とコストがかかるのが現状です。Qlean Datasetは、この課題を解決するために、多様な形式のデータを提供しています。
AI開発には、画像、動画、音声、3D、テキストなど、さまざまな種類のデータが必要です。Qlean Datasetはこれらの多様なデータ形式に対応し、研究用途から商用利用まで、あらゆるAI開発プロジェクトで安全に利用できる環境を整備しています。
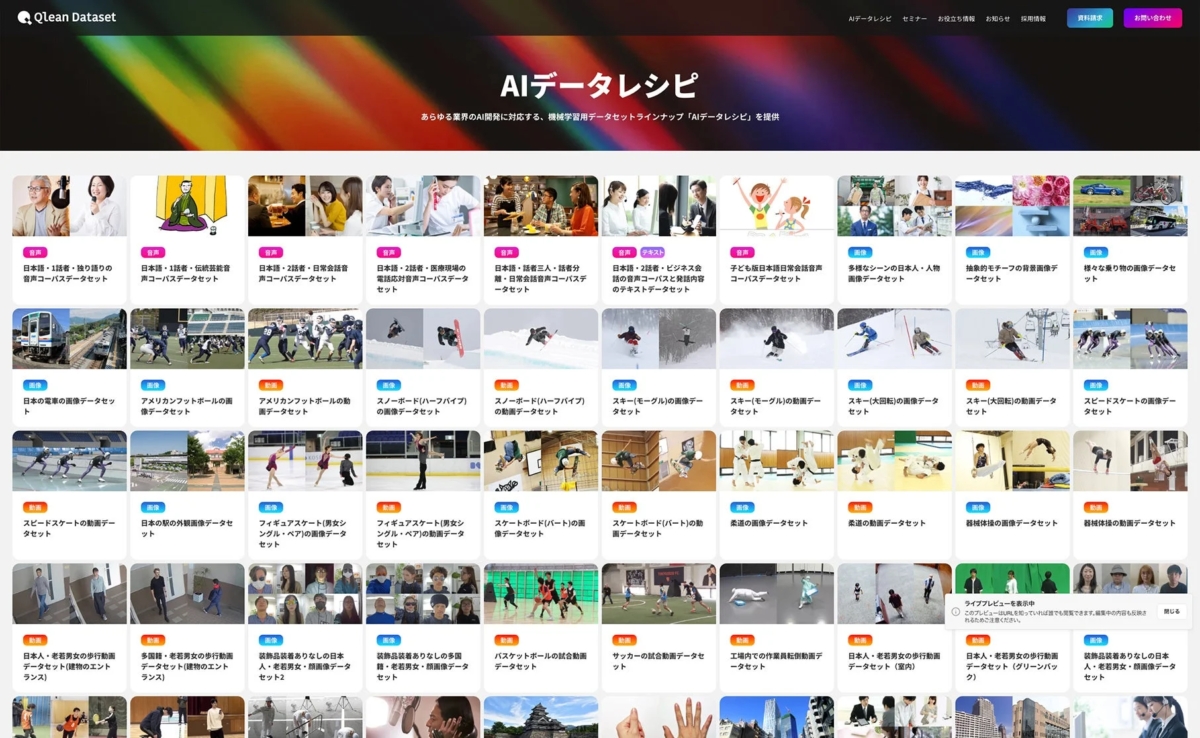
「AIデータレシピ」:豊富なデータラインナップ
Qlean Datasetは、AI開発に必要なデータを「AIデータレシピ」というラインナップで提供しています。この「AIデータレシピ」は、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータセットを継続的に拡充しています。これにより、AI開発者は常に最新かつ質の高いデータにアクセスし、より高度なAIを開発することが可能になります。
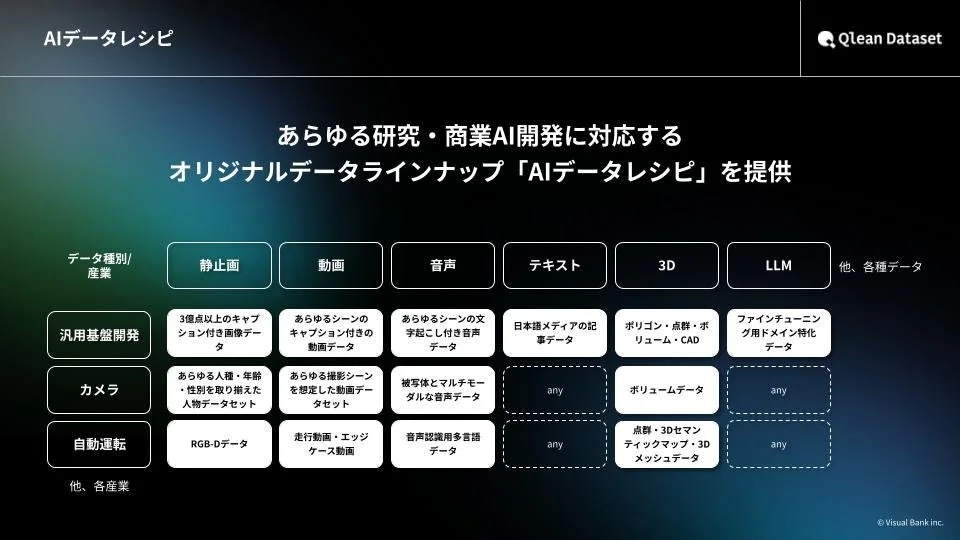
Qlean Datasetが提供する価値
Qlean DatasetがAI開発現場にもたらす主な価値は以下の通りです。
- データ収集・整備の負荷軽減: AI開発者がデータの準備に費やす時間と労力を大幅に削減し、AIモデルの設計や開発といった本来の業務に集中できる環境を提供します。
- 権利クリアで法的リスクのないAI開発: 提供されるすべてのデータは、被写体からの同意取得や著作権、肖像権などの権利処理が適切に行われています。これにより、開発者は法的リスクを心配することなく、安心してAI開発を進めることができます。
- 多様なデータ形式と構成への柔軟な対応: 画像、動画、音声、3D、テキストなど、さまざまなデータ形式に対応し、各プロジェクトの具体的な要件に合わせてデータを提供します。既存のデータセットは最短1日で納品可能であり、独自のデータが必要な場合にはカスタム撮影・収録・収集にも対応しています。


AI開発現場におけるデータに関する悩みを解決し、AI開発を加速させるための強力なパートナーと言えるでしょう。
Qlean Datasetのより詳しい情報はこちらから確認できます。
Qlean Datasetサイト
AIデータレシピ
Visual Bank株式会社:AIの可能性を解き放つ企業
Qlean Datasetを運営するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持つほか、漫画家の「もっと描きたい!」をサポートするAI補助ツール『THE PEN』なども提供しています。
Visual Bankは、国の研究開発プログラム「GENIAC」にも採択されるなど、その技術力と将来性は高く評価されています。高品質なデータ提供を通じて、AI技術の社会実装を加速させるための重要な役割を担っています。
Visual Bank株式会社の詳細は以下のリンクからご覧いただけます。
Visual Bank企業URL
アマナイメージズ企業URL
まとめ:AI開発の未来を拓く新たな一歩
Qlean Datasetが提供を開始した「日本語・1話者・レジャーテーマトーク音声コーパスとトランスクリプト」は、音声認識や自然言語処理といったAI技術の研究開発にとって、非常に価値のあるデータセットです。一人語りの自然な発話とレジャーという身近なテーマは、AIがより人間らしい言葉のニュアンスや文脈を理解するための学習に大きく貢献するでしょう。研究機関から企業のAI開発部門まで、幅広いニーズに応えるこのデータセットは、AIの精度向上と新たな応用分野の開拓を促進します。
AI技術が進化し続ける中で、データの質と量がその進歩を左右します。Qlean Datasetのような信頼できるデータソリューションは、AI開発のハードルを下げ、より多くの人々がAIの恩恵を受けられる社会の実現に貢献していくことでしょう。今回のリリースは、AI開発の未来を拓く、確かな一歩と言えます。AI初心者の皆様も、この新たなデータセットがもたらす可能性にぜひ注目してみてください。

