AIの「声」をより自然に、より正確に!Qlean Datasetが新データセットを提供
近年、AI(人工知能)技術の進化は目覚ましく、私たちの日常生活の様々な場面でAIが活用されています。特に、AIが人間の言葉を理解したり、人間のように話したりする「音声AI」の分野は、スマートスピーカーや自動応答システム、オーディオブックなど、その応用範囲を広げています。
このような音声AIの性能をさらに高めるためには、高品質な「学習データ」が不可欠です。学習データとは、AIに様々な情報を覚えさせるための材料のことで、音声AIの場合は「人間の声のデータ」と「その声が話している内容を文字にしたデータ(トランスクリプト)」が重要になります。
この度、Visual Bank株式会社が展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」が、AI開発を強力に後押しする新たなデータセットの提供を開始しました。それが、「日本語・1話者・文学朗読音声コーパスとトランスクリプト」です。
この新しいデータセットは、AIがより自然で表現豊かな音声を生成したり、複雑な日本語の音声を正確に聞き取ったりするための基盤となることが期待されています。AI初心者の方にも分かりやすいように、その詳細とAI開発における重要性について詳しく見ていきましょう。
「日本語・1話者・文学朗読音声データセット」の全貌
Qlean Datasetが提供を開始した「日本語・1話者・文学朗読音声データセット」は、その名の通り、日本の文学作品や小説を対象とした音声データと、その内容を忠実に書き起こしたテキストデータ(トランスクリプト)で構成されています。
データセットの主な特徴
このデータセットの最も大きな特徴は、「同一の日本人話者が全編を朗読している」という点です。これにより、長時間にわたる音声データ全体で、声質や話し方(話者性)に一貫性が保たれています。これは、AIが学習する上で非常に重要な要素となります。
収録されている音声は、文学作品特有の情景描写や地の文(登場人物のセリフではない部分)を、一定のテンポで丁寧に読み上げる「朗読スタイル」を維持しています。感情の起伏を抑えつつも、文学的な表現に基づく微細な抑揚(声の高さや強弱の変化)が含まれているため、文脈を考慮した高度な音声生成技術の検証に最適です。
AI開発における具体的な活用シーン
このデータセットは、主に以下の3つのAI技術開発に最適化されています。
- 音声合成(TTS:Text-to-Speech)モデルの学習: テキストから音声を生成するAIです。例えば、入力された文章をAIが読み上げてくれる機能などがこれにあたります。このデータセットを使うことで、AIがより人間らしく、自然な抑揚で文学作品を朗読できるようになります。
- 自動音声認識(ASR:Automatic Speech Recognition)の精度向上: 音声をテキストに変換するAIです。私たちが話した言葉をAIが文字に起こす機能などがこれにあたります。文学作品特有の難しい言葉遣いや長い文章でも、AIが正確に認識できるようになります。
- 自然言語処理(NLP:Natural Language Processing)の研究: 人間の言葉の意味や構造を理解するAIです。文章の要約や翻訳、感情分析などがこれにあたります。文学作品の豊かな表現をAIが深く理解するための研究に役立ちます。
データセットの概要
提供されるデータセットの具体的な仕様は以下の通りです。
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 日本人 |
| データ形式 | ・音声データ:mp3 ・テキストデータ:txt, json, csv |
| 収録時間 | 1音声30秒〜160分 |
| 音声レート | 44.1kHz / 48kHz |
| 対象のシーン | ・日本の小説や文学作品の文章を朗読するシーン |
このデータセットのサンプルは、以下のページで確認できます。
サンプルページ
なぜこのデータセットがAI開発に重要なのか?
この「日本語・1話者・文学朗読音声データセット」が、なぜAI開発においてこれほどまでに重要視されるのでしょうか。その理由を、具体的なユースケースを交えて解説します。
【研究用途】長尺文脈における音声合成(TTS)の韻律制御研究
AIが生成する音声がどれだけ自然に聞こえるかは、「韻律(いんりつ)」の制御にかかっています。韻律とは、声の高さ、アクセント、リズム、ポーズ(間)といった、音声の抑揚や流れのことです。特に、数十分から一時間を超えるような長い文章をAIに読ませる場合、一貫した話者性を保ちながら、文脈に応じて自然なポーズや抑揚を生成するのは非常に高度な技術が求められます。
このデータセットは、長時間の文学朗読音声であるため、AIが長文を読んだ際の韻律制御の精度を検証するのに最適です。例えば、「この小説の登場人物は、ここでどのような感情を抱いているのか?」といった文脈をAIが理解し、それに合わせた自然な声の表現ができるかどうかを試すことができます。これにより、より人間らしい、感情豊かな音声合成モデルの開発が進むでしょう。
【産業用途】オーディオブック・ナレーション生成AIの開発
出版業界やエンターテインメント業界では、オーディオブックや動画のナレーション制作の需要が高まっています。しかし、人間による朗読やナレーション制作には時間もコストもかかります。
このデータセットは、文学作品の複雑な構文(文章の組み立て方)を正確に読み上げるナレーションAIの学習データとして活用できます。AIが文学作品特有の表現や難しい言葉遣いを習得することで、人間による朗読に近い、自然で心地よいリスニング体験を提供するオーディオブックやナレーションを自動で生成できるようになります。これにより、制作コストの削減や、より多くの作品をオーディオブック化する可能性が広がります。
【産業用途】文学表現に特化した自動音声認識(ASR)の音響モデル最適化
自動音声認識(ASR)技術は、日常会話の認識にはある程度対応できるようになってきましたが、文学作品のような「文語体」(書き言葉)や、特定の分野で使われる専門的な「語彙(ごい)」が含まれる音声の認識は、まだ課題が残っています。
日常会話と異なり、文学作品では古風な言葉遣いや比喩表現、独特の言い回しが多く使われます。このデータセットは、そうした文学表現に特化した音声を正確に認識し、テキスト化するためのASRモデルを開発する際に役立ちます。特定のドメイン(分野)に特化したASRモデルの「ファインチューニング」(既存のAIモデルを特定の目的に合わせて微調整すること)を行うことで、例えば、研究者が文学作品の音声を分析する際などに、より高い精度で文字起こしができるようになるでしょう。
Qlean Datasetと「AIデータレシピ」について
この革新的なデータセットを提供する「Qlean Dataset」とは、どのようなサービスなのでしょうか。
Qlean Datasetとは
Qlean Datasetは、Visual Bank株式会社の100%子会社である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。AI開発には、画像、動画、音声、3D、テキストなど、多種多様な形式のデータが必要とされますが、Qlean Datasetはこれらすべてに対応しています。
AI開発で最も重要なのは、「権利処理がクリアであること」です。AIの学習に使うデータが、著作権や肖像権などの権利を侵害していないか、商用利用が許可されているか、といった点は非常に複雑で、開発者が頭を悩ませる大きな課題の一つです。Qlean Datasetは、研究用途から商用利用まで、あらゆる用途で安全に利用できる環境を整備しており、法的リスクを気にすることなくAI開発に専念できるのが大きな強みです。
AI開発を加速させる「AIデータレシピ」
Qlean Datasetは、AI開発現場のニーズに応えるため、オリジナルのデータラインナップ「AIデータレシピ」を展開しています。これは、様々な業界や最新のトレンドに即したデータセットを継続的に拡充していく取り組みです。
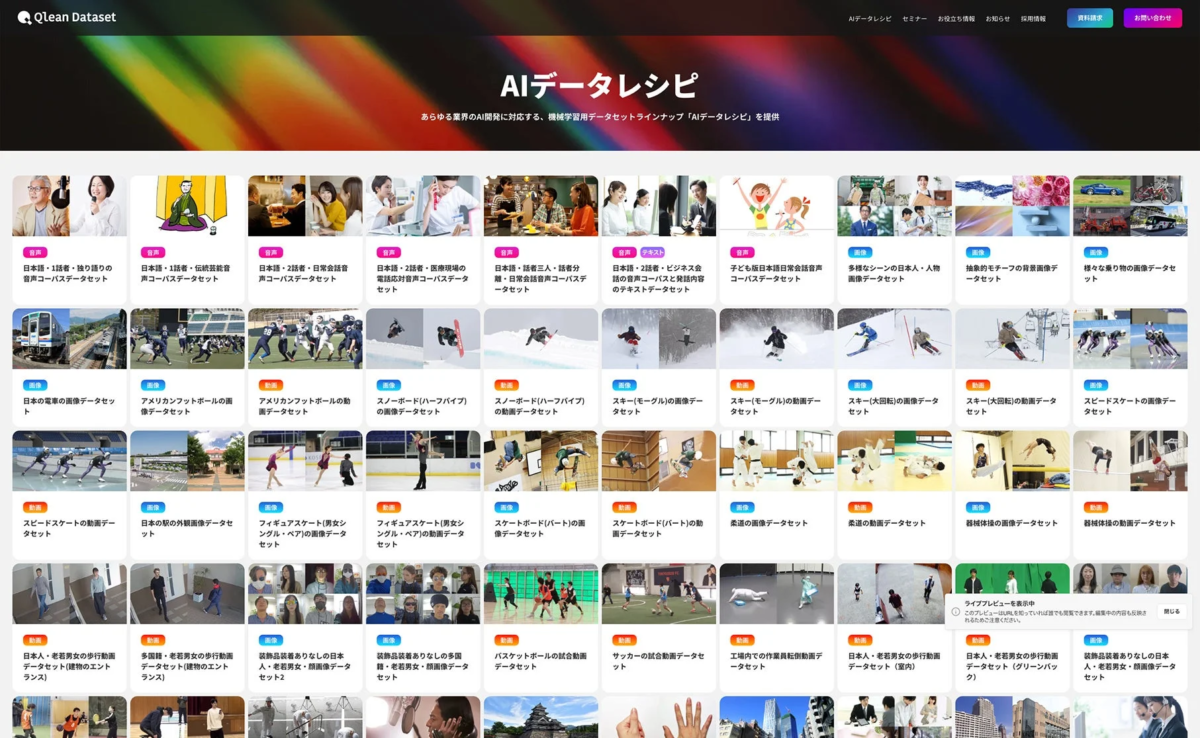
AIデータレシピの主な特徴
-
すべての被写体から同意取得: AI学習に使用される人物などのデータは、事前に適切な同意を得ているため、安心して利用できます。
-
既存データは最短1日で納品可能: 必要なデータセットがあれば、迅速に提供してもらえるため、開発期間の短縮につながります。
-
カスタム撮影・収録・収集による独自データ構築にも対応: 既存のデータセットでは対応できない、特定の要件に合わせたオリジナルのデータセットを、新たに撮影・収録・収集して提供することも可能です。
これらの特徴により、AI開発現場におけるデータ収集や整備にかかる手間と時間を大幅に軽減し、開発者は本来のAIモデル開発に集中できるようになります。

Qlean Datasetは、国内外のデータホルダーやラジオ・新聞社・通信社などのメディアとの協業を通じて、常に最新かつ質の高いデータを提供し続けています。
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社とGENIAC採択について
Qlean Datasetを運営するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。
同社は、漫画家をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持つなど、多角的にAI関連事業を展開しています。
特筆すべきは、Visual Bankが国の研究開発プログラム「GENIAC」に採択されている点です。GENIAC(Generative AI Accelerator Consortium)は、生成AIの社会実装を加速するためのプログラムであり、この採択は、Visual Bankの技術力と将来性が国によって認められていることを示しています。これにより、同社のAIデータソリューションは、今後さらに社会貢献性の高い形で発展していくことが期待されます。
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/
まとめ:AIの「声」の未来を拓く、文学朗読音声データセット
Qlean Datasetが提供を開始した「日本語・1話者・文学朗読音声コーパスとトランスクリプト」は、AIがより人間らしく、より正確に「声」を操るための、まさに「教科書」のような存在と言えるでしょう。
この高品質なデータセットは、音声合成(TTS)によるオーディオブックやナレーションの自動生成、自動音声認識(ASR)による文学作品の正確な文字起こし、そして自然言語処理(NLP)における言語理解の深化といった、多岐にわたるAI開発を強力に支援します。
AI技術は日々進化しており、その中心には常に「質の高いデータ」の存在があります。Qlean Datasetのような、権利処理が明確で、かつニーズに合わせた柔軟なデータ提供を行うサービスは、AI開発の現場にとって不可欠なインフラとなっています。
今後、このデータセットを活用した研究や開発が進むことで、私たちの生活の中に、より自然で、より便利な「音声AI」が浸透していくことでしょう。文学作品がAIの「声」を通じて新たな形で私たちに届けられたり、AIが複雑な人間の言葉をより深く理解し、私たちをサポートしてくれたりする未来は、きっとそう遠くないはずです。Visual BankとQlean Datasetの今後の取り組みにも注目が集まります。