
Qlean Datasetが「日本語・2話者・テレビ・映画テーマトーク音声コーパスとトランスクリプト」の提供を開始
AI(人工知能)の進化は目覚ましく、私たちの生活やビジネスに大きな変化をもたらしています。そのAI開発において、高品質な「学習データ」は不可欠です。特に、人間が日常的に交わす「自然な会話」をAIが理解し、生成する能力は、音声認識(ASR)や大規模言語モデル(LLM)といった分野で非常に重要視されています。
この度、Visual Bank株式会社の子会社である株式会社アマナイメージズが展開するAI学習用データソリューション「Qlean Dataset(キュリン データセット)」から、AI開発を強力に支援する新たなデータセットが提供開始されました。その名も「日本語・2話者・テレビ・映画テーマトーク音声コーパスとトランスクリプト」です。このデータセットは、テレビドラマや映画といったエンターテインメントコンテンツを題材に、2人の日本人が自然に対話する音声とその書き起こしテキストを収録しており、AIがより人間らしいコミュニケーションを学習するための貴重な資源となります。
AI開発におけるデータ収集の課題を解決し、権利処理済みの安全なデータを提供するQlean Datasetが、どのようなデータセットを提供し、それがAI開発にどのような影響を与えるのかを、AI初心者にも分かりやすく詳しく解説していきます。
なぜ「自然な対話データ」がAI開発に不可欠なのか?
AIが私たちの言葉を理解し、適切に反応するためには、大量の「言葉のデータ」を学習する必要があります。しかし、単に文章を読み込ませるだけでは、人間が実際に話すような「自然な会話」のニュアンスや構造をAIが学ぶことは困難です。
例えば、私たちは会話の中で「うん」「そうですね」といった相づちを打ったり、話の途中で話題を変えたり、複数の人が同時に話したりすることがよくあります。このような複雑で予測不能な要素こそが、実際の会話の特徴です。AIがこれらの要素を理解し、適切に処理できるようになるためには、まさに「人間が実際に話している様子」を捉えたデータが必要なのです。
今回Qlean Datasetが提供を開始したデータセットは、まさにこの「自然な対話」に焦点を当てています。テレビや映画という共通の話題を通じて、2人の話者が台本なしで自由に意見を交わすことで、より現実世界に近い会話のパターンをAIに学習させることが可能になります。
自動音声認識(ASR)の精度向上
ASR(Automatic Speech Recognition:自動音声認識)とは、人間の音声をテキストに変換する技術のことです。スマートフォンの音声アシスタントや議事録作成ツールなどで利用されています。このASRの精度は、AIが学習する音声データの質に大きく左右されます。
一般的な音声データは、一人の話者が明確に話す「独話」データが多い傾向にあります。しかし、実際の会話では「話者同士の重なり(被り)」や「相づち」「間合い」など、独話では発生しない要素が多数存在します。これらの要素を含む自然な対話データを学習することで、AIはより複雑な現実世界の音声環境においても、正確に音声を認識できるようになります。
自然言語処理(NLP)と大規模言語モデル(LLM)の進化
NLP(Natural Language Processing:自然言語処理)は、AIが人間の言語を理解し、生成する技術です。そして、近年注目を集めるChatGPTのようなLLM(Large Language Models:大規模言語モデル)は、このNLP技術の最先端をいくものです。
LLMがより自然で人間らしい文章を生成するためには、単語の意味だけでなく、文脈、感情、話者間の関係性なども理解する必要があります。テレビや映画の感想を語り合う会話は、登場人物への評価、作品の印象、意見の一致・相違など、感情や考察が豊かに含まれます。このようなデータは、AIが複雑な感情表現や論理展開を学習し、より高度な対話能力を身につける上で非常に有効です。
新データセット「日本語・2話者・テレビ・映画テーマトーク音声コーパスとトランスクリプト」の詳細
Qlean Datasetが新たに提供するこのデータセットは、AI開発者が直面する「自然な対話データ不足」という課題に対し、具体的な解決策を提示します。その特徴と内容を詳しく見ていきましょう。

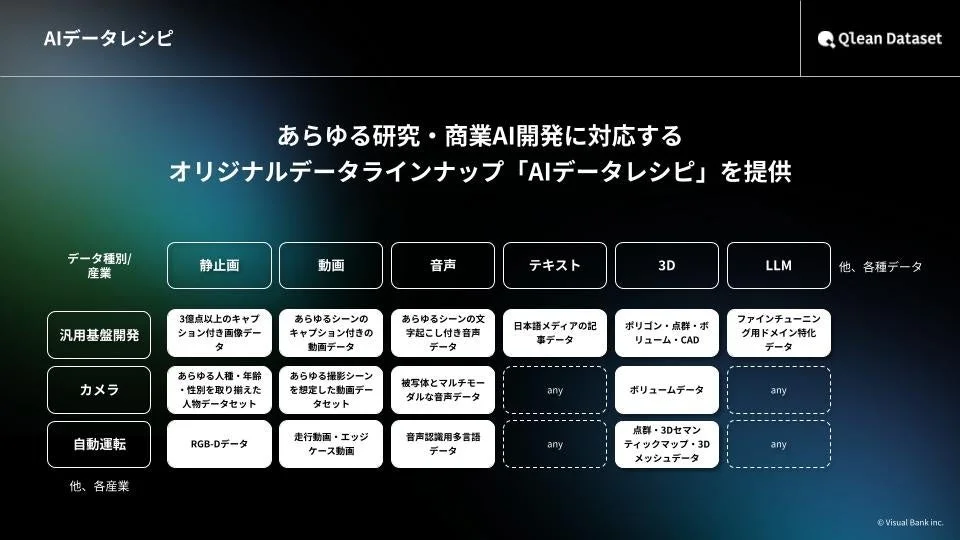
このデータセットは、Qlean Datasetが展開する機械学習用データセットラインナップ『AIデータレシピ』に加わるものです。
データセットの内容と特徴
-
テーマ: テレビドラマ、バラエティ番組、映画作品といった映像コンテンツ
-
話者: 日本人の男女2名
-
対話形式: 作品の内容や印象、登場人物への評価などを起点に意見を交わす会話
-
収録方法: 台本による制御を行わず、話者同士が自由なテンポで感想や考察を共有。相づちや話者交替、話題転換を含む自然な会話構造を反映。
-
データ種別: 音声、テキスト(トランスクリプト)
-
被写体属性: 日本人、20代〜50代の男女
-
データ形式: 音声データ:mp3 / wav
-
収録時間: 計約220時間(1音声あたり約5分〜60分)
-
音声レート: 44.1kHz / 48kHz
-
対象のシーン: 2名がテレビ番組やドラマ作品、映画作品について意見交換するシーン、台本のない自然な会話シーン
このデータセットの最大の強みは、その「自然さ」にあります。台本に縛られない自由な会話は、実際の人間同士のコミュニケーションに限りなく近く、AIがより実践的な対話能力を身につけるための理想的な学習素材となります。意見の賛成・反対、補足説明、話題の展開といった、現実の会話で頻繁に起こるやり取りが忠実に記録されているため、AIは多様な対話パターンを学習できるでしょう。
サンプル詳細はこちらで確認できます。
https://qleandataset.visual-bank.co.jp/lineup/pn-026
本データセットの具体的なユースケース
この新しいデータセットは、研究機関から企業まで、幅広い分野でのAI開発に活用が期待されます。
研究用途(アカデミア)
-
対話音声認識モデルの精度評価
-
活用方法: 自然対話中の発話の重なりや相づちを含む音声データは、日本語ASR研究において、認識精度の比較検証に非常に役立ちます。特に、独話データでは捉えにくい、対話特有の誤認識傾向を分析するのに適しています。
-
AI初心者向け解説: AIが人の声をテキストに変換する際、複数の人が同時に話したり、途中で「うん」と相づちを打ったりすると、うまく聞き取れないことがあります。このデータセットを使えば、AIがそういった複雑な状況でも正確に聞き取れるようになるか、どこで間違えやすいかを詳しく調べることができます。
-
-
対話構造を考慮した日本語言語モデル研究
-
活用方法: テレビ・映画という共通の知識を前提とした対話テキストは、話題の展開や応答関係を考慮した言語モデルの挙動分析や評価に利用できます。
-
AI初心者向け解説: AIが文章を作る際、ただ単語を並べるだけでなく、話の流れや前の発言とのつながりを理解する必要があります。このデータセットは、共通の話題について人がどう話し、どう話題が移っていくのかが分かるため、AIがもっと自然で意味の通じる会話を生成できるよう、その仕組みを研究するのに使えます。
-
産業用途(企業)
-
対話型AI・チャットボットの会話理解検証
-
活用方法: エンターテインメント領域の話題を含む自然対話データを用いることで、ユーザー同士の会話を想定した対話AIの理解性能や応答生成の検証に利用できます。
-
AI初心者向け解説: 例えば、映画の感想を言い合うようなチャットボットを作る場合、ユーザーが話す内容をAIがどれだけ正確に理解し、適切な返答ができるかをテストできます。このデータセットは、エンタメという身近な話題なので、より実用的なチャットボットの開発に役立ちます。
-
-
音声入力型アプリケーションの実運用テスト
-
活用方法: 複数話者が自由に会話する音声を用いることで、音声入力を前提としたサービスやアプリケーションにおけるASR処理の挙動確認や改善検討に利用できます。
-
AI初心者向け解説: 音声で操作するアプリやサービスを開発する際、実際に複数の人が同時に話したり、会話が途切れたりする状況で、AIがどれだけ正確に音声を聞き取れるかを試すことができます。これにより、実際の利用シーンでスムーズに動くアプリを作るための改善点を見つけられます。
-
Qlean Dataset(キュリンデータセット)とは
『Qlean Dataset』は、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、商用利用可能なAI学習用データソリューションです。AI開発の現場では、高品質な学習データの収集・整備が大きな課題となることが少なくありません。Qlean Datasetは、この課題を解決し、権利的にクリアで法的なリスクのないAI開発環境の構築を支援しています。
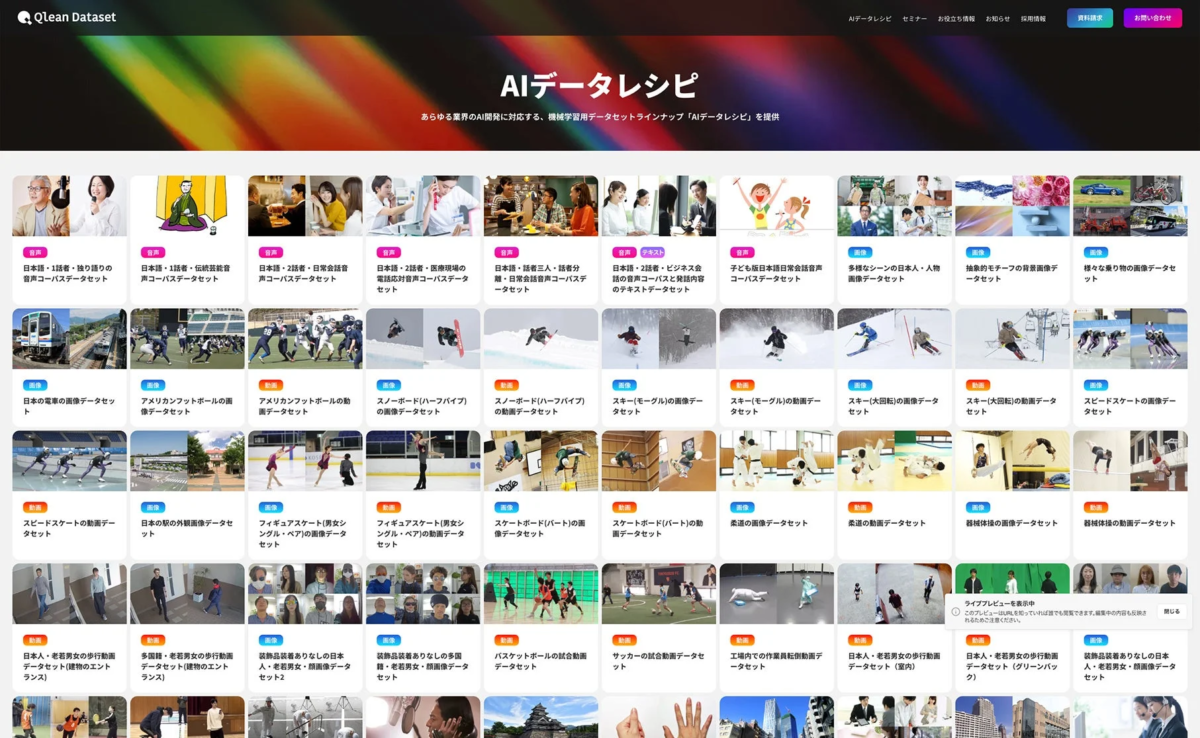
多様なデータ形式と『AIデータレシピ』
Qlean Datasetは、画像、動画、音声、3D、テキストといった多様な形式のデータに対応しています。これらのデータは、『AIデータレシピ』というラインナップを通じて提供され、研究用途から商用利用まで、幅広いニーズに応えます。
『AIデータレシピ』には、今回の音声データセット以外にも、以下のような多種多様なデータセットが含まれています。
-
日本語・1話者・独り語りの音声コーパスデータセット
-
日本語・2話者・日常会話音声コーパスデータセット
-
日本の電車の画像データセット
-
アメリカンフットボールの動画データセット
-
日本人・老若男女の歩行動画データセット
これらのデータは、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社などのデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したものが継続的に拡充されています。
Qlean Datasetの強み
Qlean Datasetは、AI開発を強力にサポートするためのいくつかの重要な強みを持っています。
-
すべての被写体から同意取得済み: 提供されるデータは、すべての被写体から事前に同意を得ているため、著作権や肖像権といった法的リスクを気にすることなく、安心して商用利用が可能です。
- AI初心者向け解説: AIに人の顔や声を使わせる場合、その人たちから「使ってもいいですよ」という許可(同意)をもらっておく必要があります。Qlean Datasetのデータは、この許可がきちんと取れているので、後でトラブルになる心配なくAI開発に使えます。
-
既存データは最短1日で納品可能: 必要なデータが既にラインナップにある場合、迅速に提供されるため、AI開発のスピードを落とすことなくプロジェクトを進められます。
- AI初心者向け解説: AI開発では、必要なデータがすぐに手に入らないと、開発が遅れてしまいます。Qlean Datasetにはたくさんのデータが用意されており、必要なデータがあれば最短1日で手に入るので、開発をスピーディーに進めることができます。
-
カスタム撮影・収録・収集による独自データ構築にも対応: 『AIデータレシピ』にない、特定の要件に合わせたデータが必要な場合でも、個別のニーズに応じてデータ収集や撮影、収録を請け負い、独自のデータセットを構築できます。
- AI初心者向け解説: もし、特別なAIを作りたい場合で、Qlean Datasetにぴったりのデータがなくても大丈夫です。Qlean Datasetは、お客様の要望に合わせて、新しいデータを集めたり、撮影・録音したりして、オリジナルのデータを作ってくれます。

Qlean Datasetは、AI開発の現場におけるデータ収集・整備の負担を大幅に軽減し、開発者が本来のAIモデル開発に集中できる環境を提供しています。
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。同社は、漫画家の創作活動を支援するAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。このような背景を持つ企業が提供するデータセットは、AI業界の発展に大きく貢献するでしょう。
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/
まとめ:AI開発の未来を拓く自然対話データ
Qlean Datasetが提供を開始した「日本語・2話者・テレビ・映画テーマトーク音声コーパスとトランスクリプト」は、AI開発、特に自動音声認識(ASR)、自然言語処理(NLP)、大規模言語モデル(LLM)の分野に大きな進歩をもたらす可能性を秘めています。台本なしの自然な対話データは、AIがより人間らしいコミュニケーションを学習するための貴重な資源であり、研究者や企業が直面するデータ不足の課題を解決するものです。
このデータセットを活用することで、AIは現実世界での複雑な会話をより正確に理解し、人間にとって自然な応答を生成する能力を高めることが期待されます。これにより、より高性能な音声アシスタント、チャットボット、そして多様な音声入力型アプリケーションの開発が加速し、私たちの生活やビジネスにおけるAIの活用範囲がさらに広がっていくでしょう。
AI技術が社会に深く浸透していく中で、Qlean Datasetのような高品質で権利クリアなデータセットの提供は、安全で倫理的なAI開発を支える基盤となります。今後もQlean Datasetが提供する『AIデータレシピ』の拡充に注目し、AIがもたらす新たな価値創造に期待が高まります。

