
ELYZAが開発した革新的な日本語拡散言語モデル「ELYZA-LLM-Diffusion」とは?
株式会社ELYZAは、日本語の文章生成を高速化し、その品質を飛躍的に向上させる可能性を秘めた新しい大規模言語モデル(LLM)、「ELYZA-LLM-Diffusion」シリーズを開発し、商用利用可能な形で公開しました。このモデルは、日本語の理解力や指示に従う能力を評価するベンチマークにおいて、非常に高い性能を発揮しています。
AI技術、特に文章を生成する大規模言語モデル(LLM)は、私たちの生活やビジネスに大きな変化をもたらしています。しかし、より自然で、より速く、そしてより効率的に文章を生成する技術への期待は高まるばかりです。「ELYZA-LLM-Diffusion」は、まさにそのような次世代のニーズに応えるべく登場しました。本記事では、AI初心者の方にも分かりやすい言葉で、この画期的なモデルの仕組み、そのメリット、そして日本のAI技術の未来にどのような影響を与えるのかを詳しく解説していきます。

大規模言語モデル(LLM)の新たな潮流:拡散モデル(dLLM)を徹底解説
「ELYZA-LLM-Diffusion」の根幹をなすのは、「拡散大規模言語モデル(Diffusion Large Language Model、略称: dLLM)」という技術です。この「拡散モデル」という考え方は、もともと美しい画像を生成するAI(画像生成AI)の分野で注目されていました。
拡散モデルの基本的な仕組み
拡散モデルは、簡単に言うと「ノイズから元のデータを復元する」という考え方に基づいています。
- 拡散過程: まず、元のデータ(例えば、きれいな画像や文章)に少しずつノイズ(ざらつきやランダムな情報)を加えていき、最終的には完全にノイズだけの状態にまで変換します。
- 逆拡散過程: 次に、このノイズだけの状態から、ノイズを取り除いて元のデータを少しずつ再構築していく方法をAIに学習させます。この学習を繰り返すことで、AIはノイズから非常に高品質なデータを生成できるようになります。
従来のLLM(自己回帰モデル)との違い
これまでの多くのLLMは、「自己回帰モデル(Autoregressive Model、略称:ARモデル)」と呼ばれる方式で文章を生成していました。ARモデルは、まるで人が文章を書くように、左から右へと一語ずつ、あるいは一文字ずつ順番に生成していくのが特徴です。前の単語が次の単語の生成に影響を与えるため、非常に自然な文章が生成できる反面、生成には時間がかかります。
一方、dLLMはARモデルとは異なり、文章を逐次的に生成する必要がありません。ノイズから全体像を少しずつ明確にしていくため、設計によってはより少ない処理回数で文章全体を生成することが可能です。
上記の画像は、dLLMとARモデルの生成プロセスの違いを視覚的に示しています。dLLMは、ノイズの中から徐々に意味のあるテキストが浮かび上がってくる様子が表現されており、ARモデルの逐次的な生成とは異なるアプローチであることが見て取れます。
dLLMがもたらすメリットと現在の課題
dLLMの最大の利点は、その「効率性」にあります。少ない処理回数で文章を生成できるため、以下のようなメリットが期待されています。
-
生成速度の向上: より速く文章を作成できるようになります。
-
消費電力の低減: AIの運用にかかる電力コストを抑える可能性があります。
これは、AI技術の活用が広がる中で、電力消費量の増加が国際的な社会問題となっている現状において、非常に重要な進歩と言えます。
一方で、dLLMはまだ新しい技術であるため、いくつかの課題も抱えています。学習に高いコストがかかることや、性能面での改善の余地があること、そして推論基盤などのエコシステム(関連技術やツール)がまだ十分に成熟していない点が挙げられます。しかし、基礎研究は着実に進展しており、将来的に実用化が進む可能性のある技術として、世界中で注目されています。特に、これまでに公開されてきたdLLMの多くは英語データを中心に学習されてきたため、日本語に特化したモデルの開発は日本のAI分野にとって大きな意義を持ちます。
ELYZAが開発した日本語特化型dLLM「ELYZA-LLM-Diffusion」シリーズ
このような背景の中、株式会社ELYZAは、日本語における知識や指示追従能力を強化した「ELYZA-LLM-Diffusion」シリーズを開発しました。このモデルは、HKU NLP Groupが開発・公開しているdLLM「Dream-org/Dream-v0-Instruct-7B」をベースにしています。
ELYZAは、このベースモデルに対し、さらに日本語データによる追加の事前学習と、特定の指示に従って文章を生成する「指示学習」を行うことで、日本語の特性に最適化されたモデルを構築しました。現在、以下の2つのモデルが公開されています。
-
ELYZA-Diffusion-Base-1.0-Dream-7B: 「Dream-v0-Instruct-7B」に日本語データの追加事前学習を行った基本モデルです。
-
ELYZA-Diffusion-Instruct-1.0-Dream-7B: 「ELYZA-Diffusion-Base-1.0-Dream-7B」に指示学習を行った、より実用的なモデルです。
これらのモデルは、Hugging Face Hub上で公開されており、誰でもアクセスしてその性能を試すことができます。また、chatUI形式のデモも公開されており、実際にモデルと対話しながらその能力を体験することが可能です。
-
デモページ: https://huggingface.co/spaces/elyza/ELYZA-Diffusion-Instruct-Dream-7B-Demo
- ※アクセス過多により、リクエスト処理に待ち時間が発生する場合があります。
モデルの開発プロセスや技術的な詳細、各種ベンチマークの解説を含む評価の詳細情報については、公式テックブログで詳しく解説されています。より専門的な内容に興味がある方は、ぜひこちらも参照してください。
日本語タスクで示された高い性能
「ELYZA-LLM-Diffusion」シリーズが、実際の日本語タスクにおいてどのような性能を発揮するのかは、多くの人が気になるところでしょう。ELYZAは、このモデルの性能を検証するため、日本語タスクを中心とした評価を行いました。比較対象には、他の拡散モデル(dLLM)や従来の自己回帰モデル(ARモデル)が用いられています。
ベンチマーク評価の結果
評価の結果、「ELYZA-Diffusion-Instruct-1.0-Dream-7B」は、一般的な日本語能力を問われるタスクにおいて、既存のオープンなdLLMと比較して同等か、それよりも優れた性能を発揮することが確認されました。
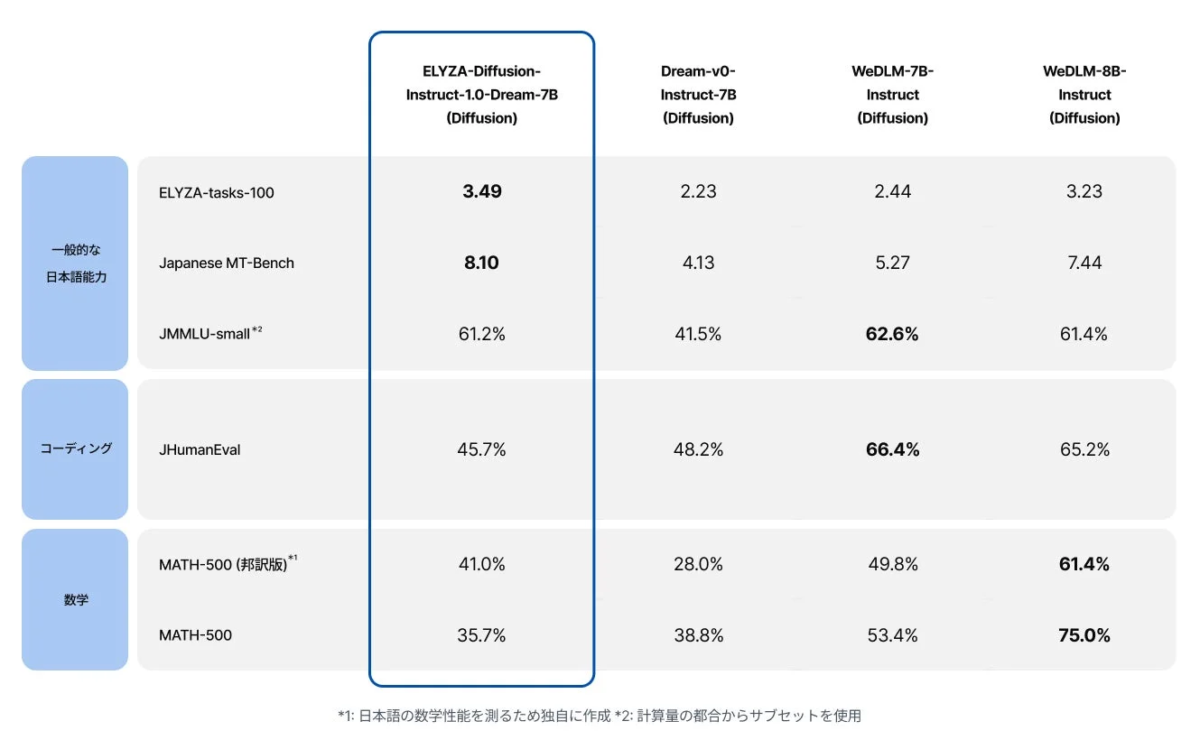
上記の表は、ELYZA-tasks-100、Japanese MT-Bench、JMMLU-smallといった日本語能力のベンチマークや、JHumanEval(コーディング)、MATH-500(数学)といった応用タスクにおける各モデルのスコアを示しています。特に日本語能力の項目では、「ELYZA-Diffusion-Instruct-1.0-Dream-7B」が高いスコアを記録していることが分かります。これは、日本語のニュアンスを理解し、複雑な指示にも適切に応答できる能力が強化されていることを示唆しています。
この結果は、ELYZAが日本語データによる追加学習と指示学習に注力した成果と言えるでしょう。日本語は、その構造や表現の多様性から、AIにとって特に学習が難しい言語の一つとされています。その中で、高い性能を実現したことは、日本のAI研究開発において大きな一歩となります。
電力効率とLLMの未来:ELYZAの研究が目指すもの
AI技術の進化と普及は目覚ましいものがありますが、その一方で、AIの運用に必要な電力消費量の増加が、世界的な課題となっています。発電量の不足や、AI用データセンターの不足は、国際的な社会問題として認識されており、今後の生成AIのさらなる活用には、LLMを含む基盤モデルの効率的な推論(AIが答えを導き出すプロセス)と学習が不可欠です。
省電力化への貢献
「ELYZA-LLM-Diffusion」シリーズが採用するdLLMは、少ない処理回数で文章を生成できるという特徴を持っています。この特性により、従来のARモデルと比較して、文章生成に必要な時間が短縮され、それに伴い消費電力も抑えられる可能性があります。
ELYZAの研究は、このdLLMの可能性をさらに深く追求することで、電力効率の良い高性能な日本語LLMの開発を加速させることを目指しています。これは、単に技術的な進歩に留まらず、持続可能なAI社会の実現に向けた重要な取り組みと言えるでしょう。
日本のAI技術の発展と社会実装を支援
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに焦点を当てた最先端の研究開発に取り組んでいます。今回の「ELYZA-LLM-Diffusion」シリーズの公開も、その一環です。
同社は、今後もLLMを中心とした研究成果を可能な限り公開・提供していくことで、日本国内におけるLLMの社会実装を推進し、自然言語処理技術全体の発展を支援していく方針を示しています。企業との共同研究やクラウドサービスの開発を通じて、先端技術の研究開発とコンサルティングを行い、企業の成長に貢献する形で大規模言語モデルの導入実装を推進しています。
- 株式会社ELYZA 公式サイト: https://elyza.ai/
まとめ
株式会社ELYZAが開発・公開した日本語拡散言語モデル「ELYZA-LLM-Diffusion」シリーズは、日本語の文章生成をより高速に、そしてより高品質に行うための新たな道を切り開くものです。拡散モデルという革新的なアプローチを採用することで、従来のモデルにはない効率性と省電力の可能性を秘めています。
このモデルが日本語タスクにおいて高い性能を発揮したことは、日本のAI技術の進歩を示すとともに、今後のAI活用における電力問題への解決策の一つとなる期待も寄せられます。AI技術が社会に深く浸透していく中で、このような効率的で高性能なモデルの開発は、持続可能な未来を築く上で不可欠です。
「ELYZA-LLM-Diffusion」は、まだ発展途上の技術ではありますが、その潜在能力は計り知れません。今後、この技術がどのように進化し、私たちの生活やビジネスを豊かにしていくのか、その動向に注目していきましょう。日本のAI技術の未来が、この革新的なモデルによってさらに明るく照らされることに期待が高まります。

