
Qlean Datasetが画期的な日本語音声データセットを提供開始
AI(人工知能)技術の進化は目覚ましく、私たちの日常生活やビジネスに深く浸透しつつあります。特に、人間と自然に会話できる「音声対話AI」は、スマートスピーカー、カスタマーサポート、教育システムなど、様々な分野での応用が期待されています。しかし、このような高度なAIを開発するためには、膨大で質の高い「学習データ」が不可欠です。AIは、この学習データを基に、言葉の意味を理解し、適切な応答を生成する能力を身につけます。
この度、Visual Bank株式会社(本社:東京都港区)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション『Qlean Dataset(キュリンデータセット)』において、「日本語・2話者・科学テーマトーク音声コーパスデータセット」の提供を開始しました。この新しいデータセットは、科学・技術領域におけるAIの音声認識(ASR)、対話理解、自然言語処理(NLP)、そして生成AI基盤の開発を強力に支援するものです。AI初心者の方にも分かりやすく、このデータセットがなぜ画期的なのか、そしてAI開発にどのような恩恵をもたらすのかを詳しくご紹介します。

Qlean Datasetとは?AI学習用データソリューションの最前線
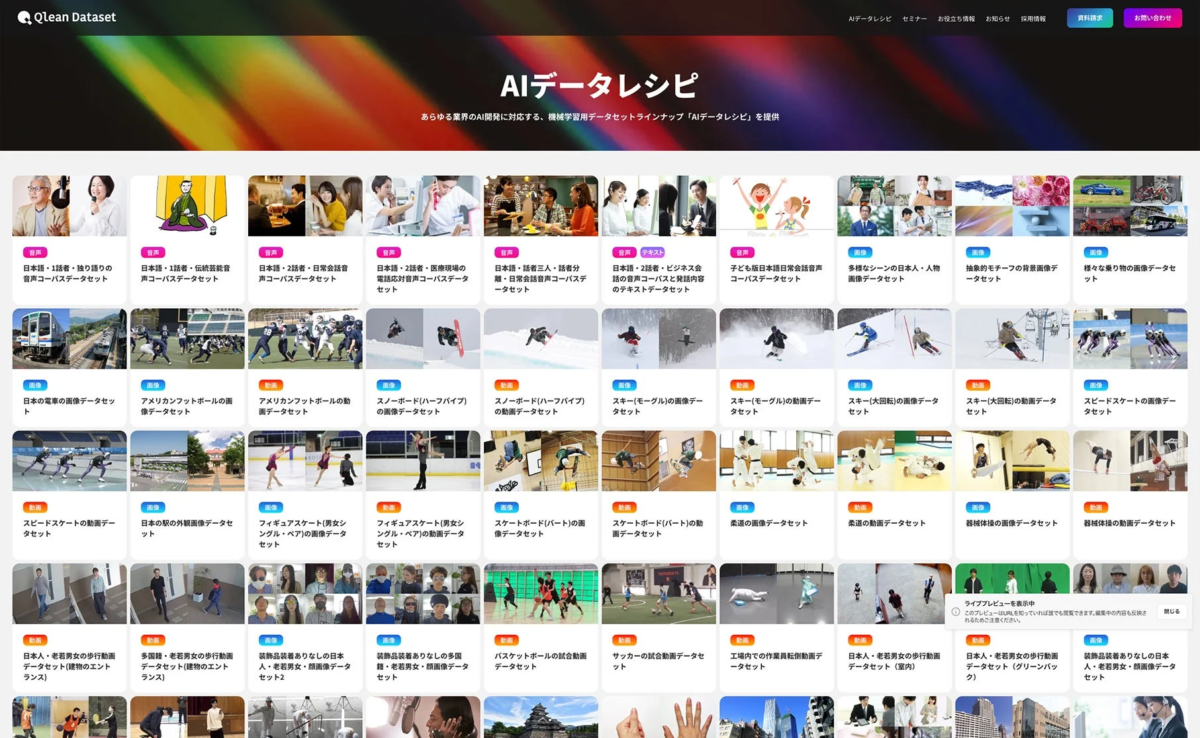
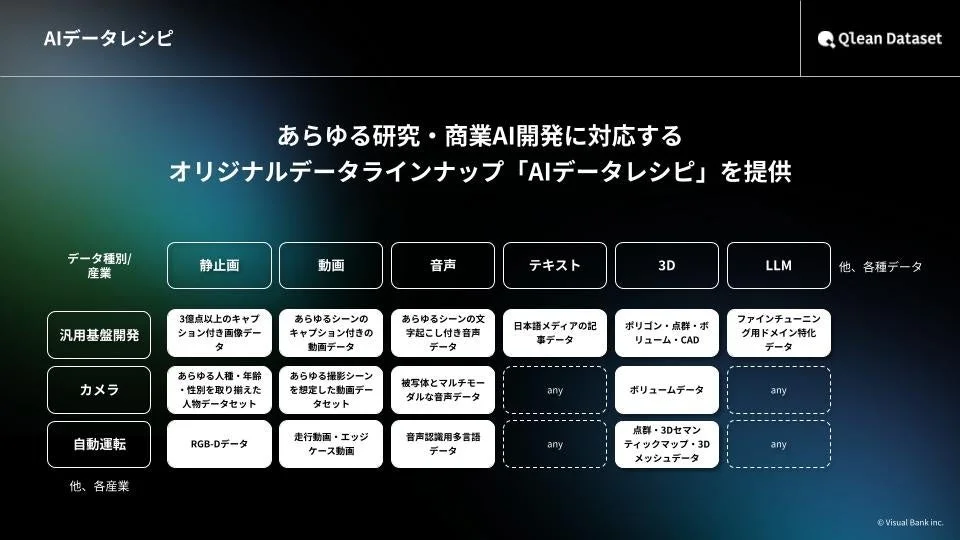
Qlean Datasetは、Visual Bank株式会社の子会社である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。AI開発には、画像、動画、音声、3D、テキストといった多岐にわたる種類のデータが必要となりますが、Qlean Datasetはこれらの多様な形式のデータに対応しています。その大きな特徴は、研究用途から商用利用まで、あらゆる目的に安全に利用できるよう、すべてのデータが「権利クリア」であるという点です。著作権や肖像権などの法的リスクを気にすることなく、安心してAI開発を進められる環境を提供しています。
さらに、Qlean Datasetは、機械学習用データセットのラインナップを「AIデータレシピ」と名付け、継続的に拡充しています。株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータを提供することで、AI開発現場におけるデータ収集・整備の負担を軽減し、より効率的で質の高いAI開発をサポートしています。
画期的な新データセット「日本語・2話者・科学テーマトーク音声コーパス」の全貌
今回提供が開始された「日本語・2話者・科学テーマトーク音声コーパスデータセット」は、AIデータレシピの新たなラインナップとして加わりました。このデータセットの最大の魅力は、その「リアルさ」と「専門性」にあります。
1. 自然でリアルな対話がAIの学習を深める
このデータセットに収録されている音声は、台本に依存せず、まるで実際の人間同士の会話のように自然な流れで進められています。具体的には、以下のような要素が含まれています。
-
発話の重なり: 相手の言葉に相槌を打ったり、少し被せて話し始めたりする、人間らしい会話の特徴。
-
言い換え: 同じ内容を別の言葉で説明し直すことで、より理解を深めるための表現。
-
説明の深掘り: 質問に対して、さらに詳しく掘り下げて説明する詳細な対話。
-
長時間の対話: 複数の科学テーマが連続して扱われる、まとまりのある長い会話。
このようなリアルな対話シーンは、AIが「実運用に近い条件」で学習し、その精度を検証するために非常に重要です。一問一答型ではない、文脈を理解し、柔軟に対応できるAIの開発には、このような複雑な対話構造を含むデータが不可欠と言えるでしょう。
2. 専門性の高い科学テーマがAIの知識を広げる
データセットのもう一つの大きな特徴は、科学分野の概念や現象について語り合っている点です。2人の話者が、質問、補足、比較、例示を交えながら対話を進めます。これにより、AIは専門用語や複雑な概念の理解、さらにはそれらを分かりやすく説明する能力を学習できます。
例えば、医療分野の診断支援AIや、技術的なトラブルシューティングを行うAIアシスタントなど、専門知識を扱うAIの開発において、このデータセットは非常に価値のある学習材料となります。AIが単に情報を羅列するだけでなく、人間のように質問に答え、さらに深い説明を求められたときにも対応できるようになる可能性を秘めています。
3. 多様な対話構造が高度なAIモデル構築に貢献
収録されている対話音声は、発話の切り替わりや相互説明を含む構成となっています。これは、単なる「質問と回答」の繰り返しではなく、「理解を前提とした対話構造」が含まれていることを意味します。AIが対話の文脈を正確に把握し、話者の意図を深く理解するためには、このような多様な対話パターンを学習することが不可欠です。これにより、より高度な対話理解モデルや、自然な応答を生成するAI基盤の開発が期待できます。
「日本語・2話者・科学テーマトーク音声コーパスデータセット」概要
| 項目 | 内容 |
|---|---|
| データ種別 | 音声 |
| 被写体属性 | 日本人20代〜50代の男女 |
| データ形式 | mp3 / wav |
| 収録時間 | 計約400時間(1音声約5分〜60分) |
| 音声レート | 44.1kHz |
| 対象のシーン | ・科学分野の概念や話題について、2者が説明や質疑を交えながら対話するシーン |
| ・台本に依存せず、例示や比較を含めて自然に会話が展開される対話 | |
| ・複数の科学テーマが連続して扱われる対話シーン |
このデータセットのサンプルは、以下のリンクから詳細を確認できます。
このデータセットがAI開発にもたらす具体的なメリットと活用シーン
今回提供開始されたデータセットは、研究用途から商用利用を想定した開発まで、幅広いAI開発環境で活用が期待されています。具体的な活用シーンを見ていきましょう。
1. 研究開発の加速
-
科学分野における対話理解モデルの研究
科学・技術テーマに関する2話者対話音声は、AIが発話の交替(話者が入れ替わること)や説明の構造を理解するための学習に役立ちます。これにより、より人間らしい対話の流れを把握し、応答できるAIモデルの研究が進むでしょう。 -
専門領域における音声言語処理研究
専門用語や概念説明を含む日本語対話音声は、音声認識(ASR)や自然言語処理(NLP)モデルが、特定の専門領域の言葉をどれだけ正確に認識・処理できるかを検証するために利用できます。例えば、医療用語や法律用語に特化したAIの精度向上に貢献します。
2. 産業応用とビジネス価値の創出
-
対話型AI・音声アシスタントの高度化
科学・技術分野の質問応答や説明対話を想定した音声対話AIの開発において、自然な対話構造を含むこのデータセットは非常に有効です。例えば、企業の技術サポートチャットボットが、顧客の複雑な技術的な質問に対して、より的確で分かりやすい説明を提供できるようになるかもしれません。また、医療機関での患者への説明支援システムなどにも応用が可能です。 -
生成AIにおける音声入力インターフェース開発
専門知識を含む対話音声を活用することで、音声入力型の生成AIや知識提供システムの対話精度が向上します。例えば、研究者が口頭で質問した内容から、関連する論文を検索し、その要点をまとめて音声で答えるようなAIシステムや、専門家向けのナレッジベースAIなどが開発できるでしょう。これにより、専門的な情報へのアクセスがより直感的で効率的になります。
3. 教育分野での新たな可能性
- 教育向け音声対話教材・システム開発
科学分野の説明や質疑応答を含む対話音声を活用し、教育支援向けの音声対話型システムや教材開発に利用できます。例えば、生徒が科学の疑問をAIに投げかけ、AIが分かりやすく解説したり、さらに質問を促したりするようなインタラクティブな学習ツールが実現するかもしれません。これは、生徒の学習意欲を高め、深い理解を促す新しい教育の形を切り開く可能性を秘めています。
Qlean Dataset『AIデータレシピ』の信頼性と特長
Qlean Datasetは、AI開発を強力に後押しするための様々な強みを持っています。

1. 権利処理済みで安心の商用利用
AI開発において最も重要な課題の一つが、学習データの権利問題です。Qlean Datasetは、すべての被写体から同意を取得しており、著作権や肖像権などの権利処理が完了しています。これにより、研究用途だけでなく、商用利用を想定した開発においても、法的リスクを心配することなく安心してデータを利用できます。
2. スピーディーなデータ提供と柔軟なカスタム対応
既存のデータセットは最短1日で納品可能であり、AI開発のスピードを加速させます。また、AIデータレシピにない、特定の要件に合致するデータが必要な場合でも、カスタム撮影・収録・収集による独自データ構築にも柔軟に対応します。これにより、AI開発者は、データ収集や整備にかかる時間や労力を大幅に削減し、本来のAIモデル開発に集中できます。
3. 多様なデータ形式と拡充されるラインナップ
Qlean Datasetは、画像・動画・音声・3D・テキストといった多様なデータ形式に対応し、あらゆる業界のAI開発ニーズに応えています。前述の通り、データパートナーとの協業を通じて、業界特化型や最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しており、常に最先端のAI開発をサポートする体制を整えています。

Visual Bank株式会社が描くAIの未来
Qlean Datasetを提供するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家の「もっと描きたい!」をサポートするAI補助ツール『THE PEN』の提供など、多岐にわたるAI関連事業を展開しています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、AI技術の社会実装に向けた取り組みを加速させています。同社のこのような取り組みは、AI技術が社会の様々な課題を解決し、新たな価値を創造していく未来を形作る上で重要な役割を担っています。
まとめ:AI開発の新たな扉を開く「日本語・2話者・科学テーマトーク音声コーパス」
Qlean Datasetが提供を開始した「日本語・2話者・科学テーマトーク音声コーパスデータセット」は、音声認識(ASR)、対話理解、自然言語処理(NLP)、生成AI基盤といった、音声対話AIのあらゆる領域における研究・開発に大きな進歩をもたらす画期的なデータセットです。
台本に依存しない自然な会話、専門性の高い科学テーマ、そして多様な対話構造を持つこのデータセットは、AIがより人間らしい対話を学習し、専門知識を正確に扱い、文脈を理解した上で柔軟な応答を生成する能力を向上させるための強力な基盤となります。これにより、科学・技術分野における対話型AI、専門知識を扱う説明支援AI、音声入力型の生成AIシステムなど、多岐にわたる応用が加速されるでしょう。
AI開発におけるデータの重要性は、今後ますます高まります。Qlean Datasetのような権利クリアで質の高いデータソリューションは、AI開発者が安心して、そして効率的に開発を進めるための不可欠な存在です。今回の新データセットの提供は、日本のAI技術が世界をリードしていくための一歩となり、私たちの社会に新たな価値と可能性をもたらすことにきっと貢献するでしょう。AIの未来に、ますます期待が高まります。

