
Qlean Dataset、AI開発の新たな扉を開く日本語音声データセットを提供開始
近年、AI(人工知能)技術の進化は目覚ましく、私たちの生活やビジネスに大きな変化をもたらしています。特に、人間とAIが自然にコミュニケーションをとるための技術、例えばSiriやAlexaのような音声アシスタント、あるいはChatGPTのような対話型AIの開発は、ますますその重要性を増しています。これらのAIを賢くするためには、大量かつ高品質な「学習データ」が不可欠です。
そんなAI開発の現場に朗報です。AI学習用データソリューション「Qlean Dataset(キュリン データセット)」が、新たに「日本語・2話者・社会文化テーマトーク音声コーパスとトランスクリプト」の提供を開始しました。これは、私たちの日常に根ざした社会文化的トピックについて、日本人の男女2名が自然な対話形式で語り合う音声と、その会話内容を正確に文字に起こした(トランスクリプト)データセットです。この新しいデータセットは、ASR(自動音声認識)、NLP(自然言語処理)、LLM(大規模言語モデル)といった、音声や言語を扱うAIの開発を大きく前進させる可能性を秘めています。

Qlean Datasetとは?AI開発を支えるデータソリューション
「Qlean Dataset」は、Visual Bank株式会社の傘下である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。AIを開発する際には、そのAIが「何を学習すべきか」を示すためのデータが必要になります。例えば、画像を認識するAIを作るなら大量の画像データ、音声を理解するAIを作るなら大量の音声データが必要です。Qlean Datasetは、画像、動画、音声、3D、テキストなど、さまざまな形式のデータを、研究用途から商用用途まで安全に利用できる形で提供しています。
AI開発の現場では、学習データの収集や整備に大きな手間とコストがかかることが課題となっています。Qlean Datasetは、この課題を解決するために、権利処理済みの高品質なデータセットを提供し、開発者が安心してAI開発に集中できる環境を支援しています。
Qlean Datasetの詳細については、以下の公式サイトをご覧ください。
Qlean Dataset公式サイト
新データセット「日本語・2話者・社会文化テーマトーク音声コーパスとトランスクリプト」の魅力
今回提供が開始された「日本語・2話者・社会文化テーマトーク音声コーパスとトランスクリプト」は、Qlean Datasetが提供する機械学習用データセットラインナップ「AIデータレシピ」に加わる新たなデータです。このデータセットの最大の魅力は、その「自然さ」と「テーマの多様性」にあります。
日常の「生きた会話」を収録
このデータセットに収録されているのは、台本を使わずに、日本人の男女2名が自由に意見や感想を交わす「生きた会話」です。生活、人間関係、価値観、働き方、住環境など、私たちの日常に密着した社会文化的なトピックが題材となっています。個人の体験や考え方に基づいた対話が中心で、相づちや話者の交代、話題の転換といった、実際の会話で自然に起こるやり取りが忠実に再現されています。これにより、AIがより人間らしい会話の構造やニュアンスを学習できるようになります。
なぜ「自然な会話」がAI開発に重要なのか
ASR(自動音声認識)は、人間の音声をテキストに変換する技術です。NLP(自然言語処理)は、テキストの意味を理解し、分析する技術。そしてLLM(大規模言語モデル)は、これらの技術を統合し、人間のように自然な文章を生成したり、複雑な質問に答えたりするAIです。
従来のAI学習データは、特定の指示に基づいた会話や、単一話者の音声が多かったかもしれません。しかし、実際の人間同士の会話は、台本通りに進むことはほとんどありません。話者は途中で言葉に詰まったり、相手の意見に共感したり、時には意見をすり合わせたりします。このような複雑で自然な会話の構造をAIが学習することで、より人間らしく、より状況に応じた適切な応答ができるAIの開発が可能になります。
例えば、AIが単に質問に答えるだけでなく、「そうですね、私もそう思います」といった共感の言葉を挟んだり、相手の曖昧な発言の意図を汲み取ったりできるようになるでしょう。これは、ユーザー体験を劇的に向上させることに繋がります。
データセットの概要
このデータセットの具体的な内容は以下の通りです。
-
データ種別: 音声、テキスト(音声の書き起こし)
-
被写体属性: 日本人、20代〜50代の男女
-
データ形式: 音声データ:mp3 / wav
-
収録時間: 計約450時間(1音声あたり約5分〜60分)
-
音声レート: 44.1kHz / 48kHz
-
対象のシーン: 社会や文化をテーマに、2名の話者が意見を交わす日本語対話
サンプル詳細はこちらから確認できます。
サンプル詳細
幅広い活用シーン:AI開発から教育まで
この新しいデータセットは、様々な分野でのAI開発や研究、さらには教育現場での活用が期待されています。具体的なユースケースを見ていきましょう。
研究用途:言語学・情報学領域の深化
研究者にとっては、日本語の対話における価値観の表現や、意見交換の構造を詳細に分析するための貴重な資源となります。
- 価値判断・意見形成プロセスの分析: 私たちが日常生活でどのように価値観を表現し、意見の対立から合意形成に至るのか、そのプロセスを言語学や情報学の観点から深く研究できます。対話の文脈を踏まえた発話の理解や、意味の解析に関する検証に適しています。
例えば、「〜だよね」「〜だと思う」といった表現が、どのような状況で、どのような意図で使われているのか、あるいは相手の意見に対して「なるほど」「確かに」と相づちを打つ行為が、会話の流れにどう影響するかなどを分析することで、より高度な言語理解モデルの開発に繋がるでしょう。
産業用途:対話型AI・LLMの性能向上
企業や開発者にとっては、対話型AIやLLMの性能を飛躍的に向上させるための基盤データとして活用できます。
-
対話型AIにおける日常会話・価値観応答の検証: チャットボットや音声アシスタントが、単に情報を伝えるだけでなく、ユーザーの感情や価値観に寄り添った応答ができるようになるかどうかの検証に役立ちます。一般的なFAQ(よくある質問)応答とは異なり、意見交換を伴う、より人間らしい対話シナリオの評価に適しています。
-
日本語LLMの会話文脈理解・応答生成性能評価: 大規模言語モデル(LLM)は、膨大なテキストデータから学習しますが、このデータセットは、個人の体験や考え方が語られる自然な対話テキストを提供します。これにより、LLMが会話の文脈を正確に保持し、話題の転換に適切に追従し、さらには価値観を含む発話に対して、より自然で適切な応答を生成できるかどうかの性能検証や、特定の目的に合わせてLLMを調整する「ファインチューニング」に活用できます。
例えば、ユーザーが「最近仕事で悩んでいるんだ」と話しかけた際に、単に「お疲れ様です」と返すだけでなく、「それは大変でしたね。どのようなことにお悩みですか?」と共感を示し、さらに踏み込んだ会話ができるようになるかもしれません。
その他実需要:コミュニケーション設計・対話分析の教材
研究や産業用途だけでなく、教育現場での活用も期待されます。
- コミュニケーション設計・対話分析の教材: 日常的な社会的話題を扱う対話音声と書き起こしは、対話の構造や意見交換の進行を分析するための教材として非常に有効です。音声と書き起こしを比較することで、話し言葉の特性や、非言語的な要素(声のトーン、間など)が会話に与える影響などを学ぶことができ、コミュニケーション能力の向上にも寄与するでしょう。
Qlean Datasetの「AIデータレシピ」と強み
Qlean Datasetは、AI開発に必要なデータを「AIデータレシピ」というラインナップで提供しています。このレシピには、今回発表された音声データセット以外にも、多種多様なデータが揃っています。
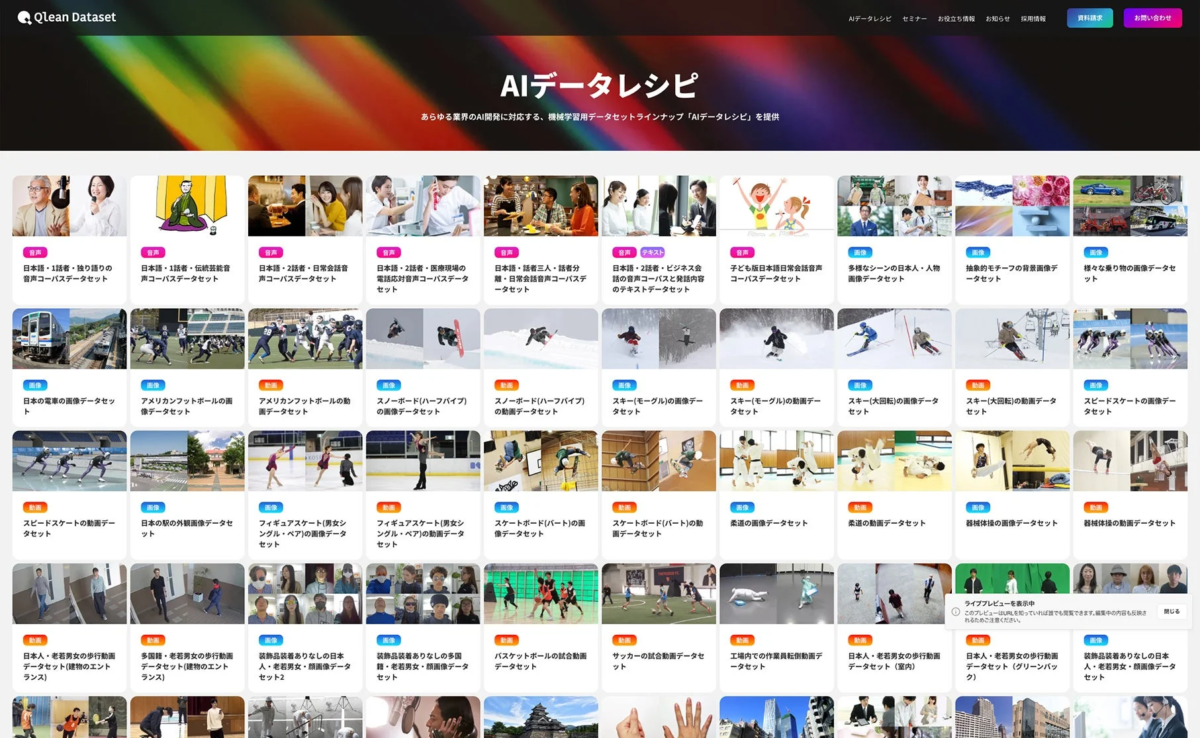
「AIデータレシピ」の主な特徴
-
あらゆる被写体から同意取得済み: 提供されるすべてのデータは、被写体からの同意を適切に取得しているため、著作権や肖像権などの法的リスクを心配することなく、商用利用を含めた幅広い用途で安心して利用できます。
-
既存データは最短1日で納品可能: 既存のデータセットであれば、迅速なデータ調達が可能で、AI開発のスピードを加速させることができます。
-
カスタム撮影・収録・収集による独自データ構築にも対応: 既存のデータでは要件を満たせない場合でも、顧客の要望に応じて、独自のデータを撮影、収録、収集し、提供することも可能です。
これらの特徴により、Qlean DatasetはAI開発におけるデータ収集・整備の負担を軽減し、開発者がより創造的な作業に集中できる環境を提供しています。
Qlean DatasetのAIデータレシピについては、以下のページをご覧ください。
AIデータレシピ
Visual Bank株式会社について
Qlean Datasetを運営するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラの構築・提供を行っているスタートアップ企業です。漫画家をサポートするAI補助ツール「THE PEN」の提供や、AI学習用データセット開発サービス「Qlean Dataset」を提供する株式会社アマナイメージズを100%子会社に持つなど、多角的に事業を展開しています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、その技術力と社会実装への取り組みは高く評価されています。
Visual Bank株式会社の詳細については、以下の企業URLをご覧ください。
Visual Bank企業URL
アマナイメージズ企業URL
まとめ:AIと人間のより豊かな対話の実現へ
Qlean Datasetが提供を開始した「日本語・2話者・社会文化テーマトーク音声コーパスとトランスクリプト」は、AI開発の現場において、特にASR、NLP、LLMといった音声・言語系AIの性能向上に大きく貢献する画期的なデータセットです。日常の自然な会話を忠実に再現したこのデータは、AIがより人間らしいコミュニケーションを学習し、共感や意見交換を伴う複雑な対話に対応できるようになるための重要な一歩となるでしょう。
このデータセットの活用により、研究分野では言語の奥深さがさらに解明され、産業分野では私たちの生活に寄り添う、より賢く、より自然な対話型AIが生まれることが期待されます。AI初心者の私たちにとっても、身近なAIがさらに進化し、私たちの生活をより豊かにしてくれる未来が、きっと訪れることでしょう。Qlean Datasetの今後の取り組みにも注目が集まります。


