生成AIの「安全性」を追求:Qlean Datasetが新サービスを開始
近年、急速な進化を遂げている生成AIは、私たちの生活やビジネスに大きな変革をもたらしています。しかし、その一方で、不適切な出力や誤情報、さらには社会的なコンプライアンスリスクといった「安全性」に関する課題も顕在化しています。このような状況に対応するため、Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、基盤モデル向けの安全性アライメント用データの提供を開始しました。
この新しいサービスは、特に日本固有の文化的背景や法規制、そして画像・動画・テキストが複合的に絡み合うマルチモーダルAIのリスクに焦点を当てています。生成AIの学習段階から「安全性」と「責任」を組み込む「Safety-by-Design」の実現を目指し、社会に信頼されるAIの普及を強力に支援します。

なぜ今、基盤モデルの「安全性設計」が求められるのか?
生成AIの性能向上と社会実装が進むにつれて、有害な表現や誤った情報の生成、さらには知的財産権侵害といったリスクへの対応が急務となっています。従来のAI開発では、モデルが完成した後に問題のある出力をフィルタリングする「事後的な対応」が主流でした。しかし、この方法では、AIの創造性を損なうことなく安全性を確保することが難しいという課題がありました。
そこで注目されているのが、「Safety-by-Design(Responsible AI)」という考え方です。これは、AIの設計や学習の初期段階から、安全性や倫理、責任といった要素を組み込むアプローチです。この「Safety-by-Design」を実現するためには、高品質で構造化されたデータセットが不可欠となります。
生成AIにおけるマルチモーダル化と社会実装の課題
特に、画像や動画、音声、テキストなど複数の種類のデータを組み合わせて処理する「マルチモーダルAI(VLMなど)」の発展は目覚ましく、その応用範囲も広がっています。しかし、これによりリスクも複雑化しています。例えば、単体では問題のない画像やテキストでも、それらが組み合わさることで不適切な意味合いを持つ出力を生み出す可能性があり、その判断は一層困難になります。
また、日本国内でのAI実運用においては、海外で開発されたAIモデルが抱える以下のような課題が顕在化しています。
-
日本特有の文脈理解不足: 海外のAIモデルは、日本の文化的背景や独自の法規制(著作権・肖像権など)への配慮が不十分であるリスクがあります。これにより、意図せず社会通念に反する出力や、法的な問題を引き起こす可能性があります。
-
複合モダリティのリスク: 「画像」と「プロンプト(AIへの指示)」の組み合わせなど、異なるモダリティが複合することで生じる多角的な不適切出力を正確に判定することが難しいという問題があります。英語圏中心の基準やテキストデータに偏った安全対策(ガードレール)では、これらの日本特有の、あるいはマルチモーダルなリスクを網羅しきれません。
Qlean Datasetは、アマナイメージズが長年培ってきた国内の権利・ビジュアルに関する専門知識を活かし、日本社会に適合した安全なAI設計をデータ面から支援します。
Qlean Datasetが提供する「安全性アライメント用データ」とは
Qlean Datasetが提供する安全性アライメント用データは、LLM(大規模言語モデル)、VLM(Vision-Language Model)、画像生成モデルなど、幅広い基盤モデルの学習段階におけるSafety Alignment(安全性アライメント)およびSafety-aware Model Training(安全性を意識したモデル学習)を目的としています。具体的には、以下のデータ作成・提供に対応します。
-
日本固有の文脈・規範に即したテキスト/プロンプトの設計: 日本の文化的背景、社会通念、そして法規制に合致するよう、AIへの指示や学習用テキストを設計します。
-
マルチモーダル(画像・動画・音声×テキスト)な複合リスクデータの作成: 異なるモダリティが組み合わさることで生じるリスクを特定し、それに対応するための学習データを作成します。
-
知的財産権(著作権・商標)や人種的公平性に配慮した評価・ラベル付与: 著作権や商標の侵害リスク、さらにはAIが特定の属性に対して差別的な出力をしないよう、公平性を考慮した評価基準に基づきデータにラベルを付与します。
モダリティ別の学習データ提供イメージ
Qlean Datasetは、各モダリティの特性に応じた、安全性に特化した学習データを提供します。
テキスト(LLM)向け:日本特有の倫理・規範への適応
-
海外指標のローカライズ: Hate Speech(ヘイトスピーチ)などの海外で一般的な評価指標を、日本の法制度や文化的背景に即して再定義します。
-
Safety-focused Instruction Tuning: 「Jailbreak(ジェイルブレイク)」と呼ばれる、AIを意図的に危険な出力に誘導しようとする攻撃的なプロンプトに対し、AIが適切に拒絶・誘導する応答ペアを学習データとして提供します。
-
Policy Decision: 医療や法務といった専門領域において、国内のガイドラインに抵触しない回答をAIが判断できるよう、その基準となるラベルを提供します。
画像生成モデル向け:知的財産保護と日本基準の倫理性
-
著作権(IP)リスク評価: 特定の作家性を想起させるプロンプトと、それによって生成された出力の類似性や依拠性を多段階で評価したデータを提供します。これにより、AIが既存の著作物を模倣するリスクを低減します。
-
日本基準のNSFW検知ラベル: 国内のプラットフォームの倫理規範に準拠し、文脈的な不適切さまでカバーするようなタグ付け(NSFW:Not Safe For Work、職場での閲覧に不適切な内容)を行います。
-
Safe Image Completion: 武器や過度な露出といったリスク要素を含む画像を、安全かつ自然な描画に置き換えるための教師データを提供し、AIが安全な画像を生成できるよう支援します。
VLM(Vision-Language Model)向け:マルチモーダルな複合リスク
-
Cross-modal Risk Understanding: 「特定の建造物」の画像と「爆破方法」を解説するテキストなど、画像とテキストの組み合わせによって顕在化する複合的なリスクを特定し、それに対応するデータを提供します。
-
視覚情報に基づく著作物・商標管理: 画像内のロゴや意匠をAIが認識し、不適切な言及を避けるための判断ロジックを学習させるデータを提供します。
-
公平性(Fairness)確保: AIが人種・性別・年齢などの属性に対してバイアス(偏見)を持たないよう、多様な属性を網羅したアノテーションデータを提供します。
-
Multi-turn Safety: 複数回の対話を経て不適切な方向へAIが誘導されるシナリオに対応するためのデータを提供し、対話の安全性も確保します。
安全性データ整備における高度なハードルとQlean Datasetの解決策
マルチモーダルAIの安全性を高めるためのデータ整備には、いくつかの高度なハードルが存在します。
-
日本独自の倫理・法的基準: 海外のデータセットでは対応が難しい、日本の著作権法や社会通念に即した微細な調整が必要です。
-
技術的・倫理的制約: 暴力や性的表現などの不適切コンテンツを収集する際には、適正なプロセスと厳格な管理体制が求められます。
-
「複合リスク」の定義: 画像とテキストの組み合わせで発生するリスク(例:悪用方法の解説)を網羅的に設計することは非常に困難です。
-
品質管理とメンタルケア: センシティブな内容を扱う作業者の精神的負担を軽減し、判断基準の一貫性を保持するための体制構築も重要となります。
Qlean Datasetは、公的機関や大手メーカーとの豊富な実績に基づいて作業設計を提供することで、AI開発者がモデル構築に集中できる環境を支援します。
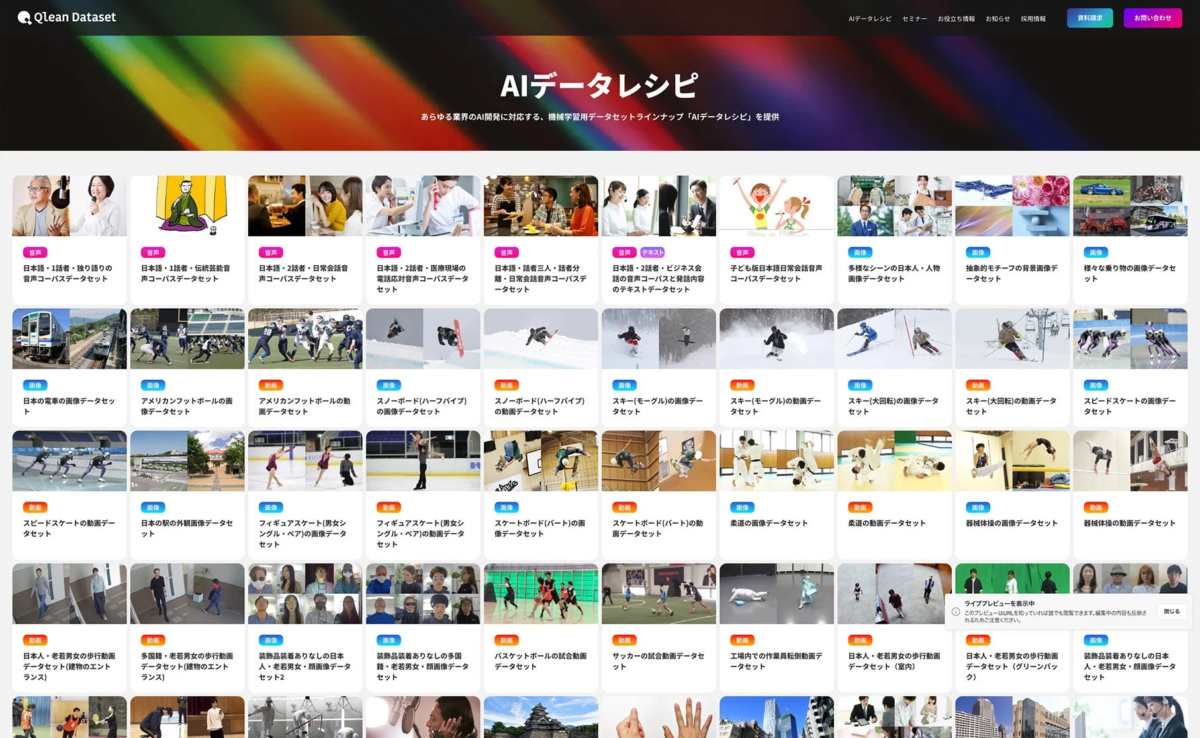
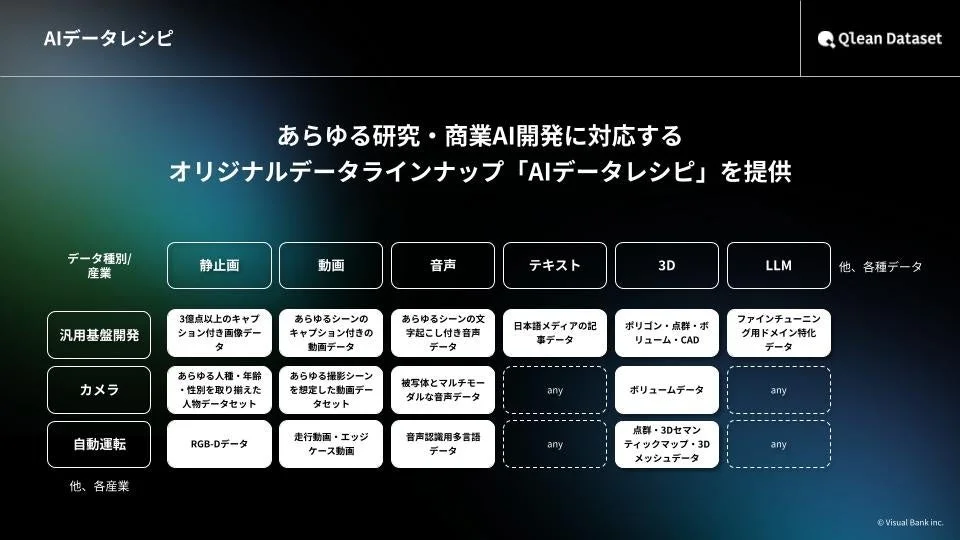


『Qlean Dataset』について
『Qlean Dataset』は、株式会社アマナイメージズ(Visual Bankグループ)が提供する、商用利用可能なAI学習用データソリューションです。音声・画像・動画・3D・テキストなど、あらゆる形式のデータに対応しており、研究・商用いずれの目的でも安全に利用できる環境を整備しています。
国内外のメディアやデータホルダーとの協業を通じて、AI開発の最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。これにより、著作権や肖像権といった法的リスクがクリアされた、AI開発に特化したデータの収集・整備を支援しています。
Qlean Datasetは、単なるデータ収集に留まらず、属性の公平性まで考慮した「実効性のあるデータ設計」を通じて、基盤モデル開発におけるSafety Alignmentを強力に支援します。国立研究開発法人などとのプロジェクトで培った知的財産保護や攻撃的プロンプトへの対応ノウハウを基に、日本固有の文脈や倫理、マルチモーダル領域のリスク定義など、高度な安全性データを提供しています。
Qlean Dataset関連リンク
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社について
Visual Bank株式会社は、AI開発力を最大化するデータインフラ事業を展開しています。漫画家の作画支援AI補助ツール『THE PEN』の提供や、AI学習用データソリューション『Qlean Dataset』を提供する株式会社アマナイメージズを運営しています。同社は、国主導の研究開発プログラム「GENIAC」にも採択されており、次世代AI技術の社会実装に向けた取り組みを強化しています。
Visual Bank株式会社 企業情報
-
代表取締役CEO:永井 真之
-
所在地:〒107-0062 東京都港区南青山7-1-7 C-Cube南青山ビル6F
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/
まとめ:実運用を見据えたAI開発をデータ整備から支援
生成AIの社会実装が加速する中で、「安全性」と「信頼性」の確保は不可欠な要素となっています。Qlean Datasetが提供する日本固有の文脈とマルチモーダルAIに対応した安全性アライメント用データは、この課題を解決するための重要な一歩です。
AI開発者は、Qlean Datasetの高品質なデータセットを活用することで、有害な出力を抑制し、知的財産権を保護し、社会的に公平なAIモデルを構築することが可能になります。これにより、AIがより安全で信頼性の高い存在として、社会の様々な分野で安心して活用される未来が期待できるでしょう。Qlean Datasetは、実運用を見据えたAI開発をデータ整備の側面から強力に支援し、AI技術の健全な発展に貢献していきます。