Visual Bank株式会社が運営するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、AI開発に欠かせない新たなデータセットの提供を開始しました。
近年、AI技術の進化は目覚ましく、私たちの生活やビジネスのあらゆる場面でその恩恵を感じる機会が増えています。特に、文章を理解したり、画像から文字を読み取ったりするAI、さらには複数の情報を組み合わせて賢く判断するAI(マルチモーダルAI)の開発が注目されています。これらのAIを開発する上で、高品質で多様な学習データは不可欠です。
今回Qlean Datasetが提供を開始したのは、「様々なドキュメント・帳票データセット」です。これは、企業が日々扱う履歴書や領収書、申込書といった業務文書をAIの学習用に整理したもので、大規模言語モデル(LLM)、光学文字認識(OCR)、そしてマルチモーダルAIといった最先端のAI技術開発を強力に支援します。
AI開発における「ドキュメント・帳票データ」の重要性
AIが人間の言葉を理解したり、書類の内容を正確に読み取ったりするためには、大量の「お手本」となるデータが必要です。特に、企業内にはPDFや画像形式で保存された多種多様な業務文書が膨大に存在します。これらの文書は、AI開発において非常に価値のある情報源となりますが、その活用にはいくつかの大きな課題がありました。
業務文書特有の課題
- 非構造データの処理: 業務文書の多くは、単なるテキストデータではなく、複雑なレイアウトや多様な記載形式を持っています。例えば、履歴書一つとっても、書式は様々で、氏名や住所の記載位置が固定されているわけではありません。このような「非構造データ」をAIに正確に理解させるのは非常に難しいとされてきました。
- 個人情報・機密情報の取り扱い: 業務文書には、個人情報や企業の機密情報が多く含まれています。そのため、AI学習データとして利用する際には、情報の匿名化や権利処理など、厳格な管理と慎重な設計が求められます。
- データ収集・整備の負担: 必要なデータを一から集め、AIが学習しやすい形に整備するには、膨大な時間とコストがかかります。特に、多様な形式のドキュメントを網羅し、かつ品質の高いデータを用意することは、多くの企業にとって大きな負担となっていました。
Qlean Datasetの「様々なドキュメント・帳票データセット」は、これらの課題を解決するために開発されました。実際の業務文書が持つ「レイアウト構造のばらつき」や「文字情報の多様性」といった実務的な要素を反映しているため、より実践的なAIモデルの開発・検証が可能になります。
Qlean Datasetが提供する「様々なドキュメント・帳票データセット」の詳細
Qlean Datasetは、AI学習用データセットのラインナップ『AIデータレシピ』の新たな一員として、このドキュメント・帳票データセットを提供します。このデータセットは、AI開発用途を前提として整理されており、文書理解モデルや情報抽出モデルの学習・評価に役立ちます。
データセットの内容例
このデータセットには、以下のような実務で頻繁に利用される書類が含まれています。
-
履歴書
-
職務経歴書
-
領収書
-
申込書
-
アンケート
-
その他、様々な業務関連ドキュメント
データ形式は、PDF、JPEG、PNGといった画像・文書形式に対応しています。これにより、テキスト情報だけでなく、文書の視覚的なレイアウトや構造もAIに学習させることが可能になります。

サンプルデータでわかる具体例
データセットには、実際のアンケート用紙や塾の入塾時アンケートなど、具体的な業務文書のサンプルが含まれています。これにより、AIがどのように情報を認識し、抽出するかを詳細に検証できます。
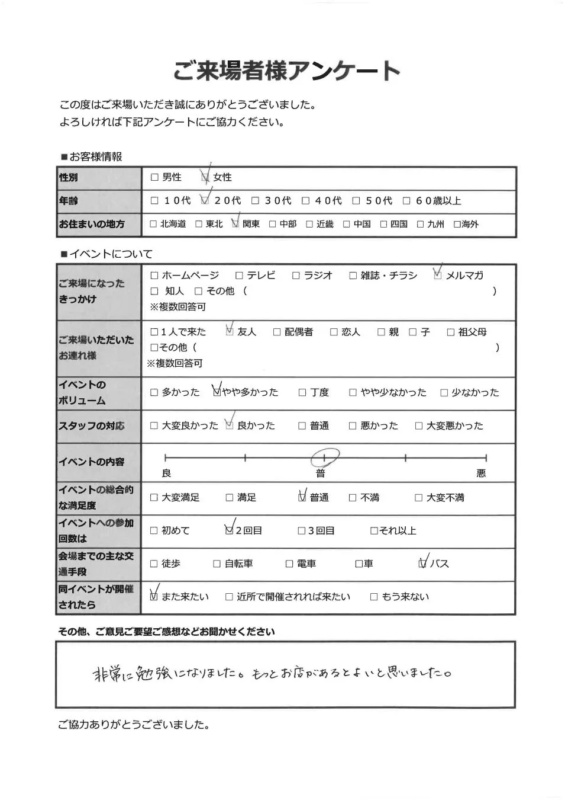

これらのサンプルは、手書き文字や多様な記入形式に対応するための学習データとして非常に有効です。
サンプルデータの詳細はこちらから確認できます。
https://qleandataset.visual-bank.co.jp/lineup/ds-047
データセットの幅広い活用事例:研究から産業まで
この「様々なドキュメント・帳票データセット」は、AIの研究開発から実際の業務への応用まで、幅広い分野での活用が期待されています。
【研究用途】
AI技術の基礎研究や新たなアルゴリズム開発において、このデータセットは貴重な資源となります。
-
文書理解モデルの構造解析研究
- 業務文書は、項目が配置されている場所や全体的なレイアウト構造が文書の種類によって異なります。このデータセットを利用することで、AIが文書の構造をどのように認識し、理解するかを研究できます。例えば、履歴書であれば「氏名」や「住所」の欄がどこにあるかをAIが自動で判別するモデルの開発・評価に役立ちます。
-
情報抽出・質問応答モデルの検証
- 特定の情報(例:履歴書からの氏名、生年月日、学歴、職務経歴。申込書からの氏名、住所、連絡先)を文書から正確に抽出するAIモデルや、文書の内容に関する質問にAIが適切に回答するモデルの精度を検証できます。大規模言語モデル(LLM)と組み合わせることで、より高度な情報抽出や質問応答システムの開発につながります。
【産業用途】
企業が抱える業務課題の解決や効率化、DX(デジタルトランスフォーメーション)推進に貢献します。
-
業務書類処理AI(OCR・IDP)の開発
- 領収書や申請書など、紙ベースや画像データで存在する書類から文字を読み取り(OCR)、さらにその文字がどのような意味を持つ情報なのか(例:金額、日付、支払先など)を理解して抽出するシステム(IDP: Intelligent Document Processing、インテリジェントドキュメント処理)の開発・検証に利用できます。これにより、手作業によるデータ入力の自動化や、処理速度の向上、ヒューマンエラーの削減が期待されます。
-
社内向けLLMの文書理解性能評価
- 社内の文書検索AIや、従業員の業務を支援するチャットボット(業務支援チャットボット)など、企業内で利用する大規模言語モデル(LLM)の性能評価にも活用できます。例えば、社内規定やマニュアルを学習させたLLMが、従業員からの質問に対して正確かつ適切な回答を生成できるか、業務文書の内容を深く理解しているかを検証するためのデータとして利用可能です。
『Qlean Dataset』とは? AI開発を支えるデータソリューション
「Qlean Dataset」は、Visual Bank株式会社のグループ会社である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。AI開発の現場で直面するデータに関する様々な課題を解決し、研究用途から商用開発まで、安全かつ効率的なAI開発環境の構築を支援しています。
『AIデータレシピ』で多様なニーズに対応
Qlean Datasetは、画像、動画、音声、3D、テキストなど、多岐にわたるデータ形式に対応した学習用データセットを『AIデータレシピ』として提供しています。
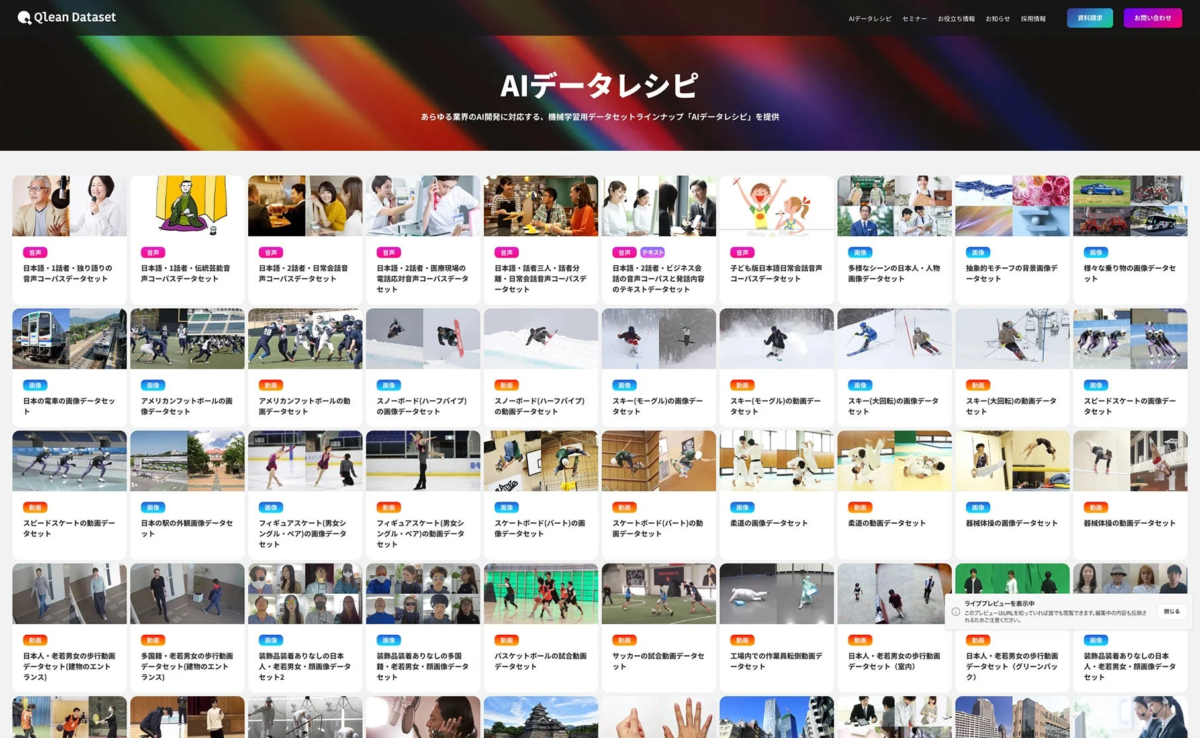
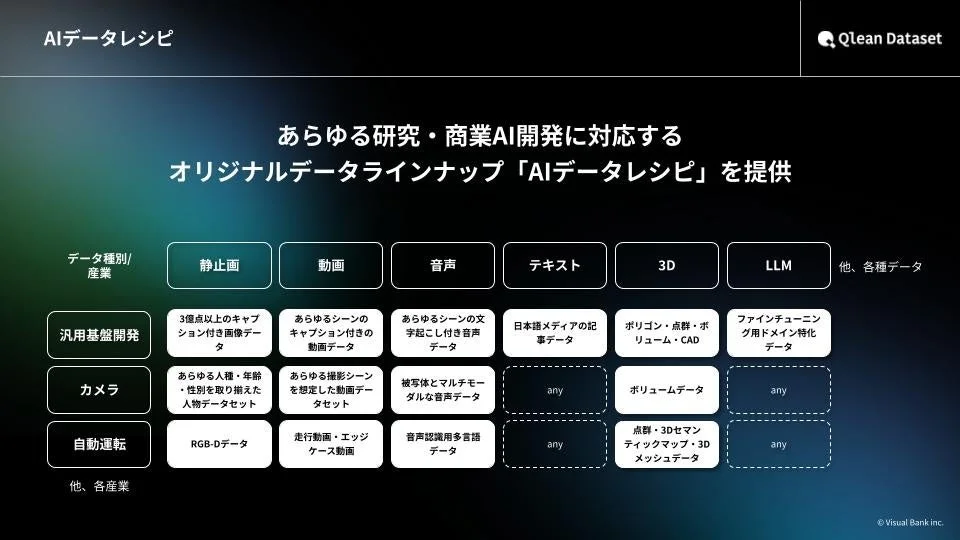
これらのデータセットは、以下の特徴を持っています。
-
すべての被写体から同意取得: 肖像権や著作権などの権利処理が適切に行われているため、商用利用においても法的リスクを心配することなく安心して利用できます。
-
既存データは最短1日で納品可能: 既に用意されているデータセットであれば、迅速に提供されるため、AI開発のスピードを落とすことなく進められます。
-
カスタム撮影・収録・収集による独自データ構築にも対応: 既存のデータセットでは対応できない、特定の要件に合わせた独自のデータが必要な場合でも、個別のニーズに応じてデータを収集・作成することが可能です。

Qlean Datasetは、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社など、様々なデータパートナーとの協業を通じて、業界特化型の最新トレンドに即したデータラインナップを継続的に拡充しています。
Qlean Datasetサイトはこちらから。
https://qleandataset.visual-bank.co.jp/
AIデータレシピのラインナップはこちらから。
https://qleandataset.visual-bank.co.jp/lineup
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。
同社は、漫画家の創作活動を支援するAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。また、国の研究開発プログラム「GENIAC」にも採択されるなど、AI技術の社会実装に向けた取り組みを積極的に推進しています。
Visual Bank株式会社の企業情報はこちらから。
https://visual-bank.co.jp/
株式会社アマナイメージズの企業情報はこちらから。
https://amanaimages.com/about/
まとめ:AI開発の未来を拓くデータソリューション
Qlean Datasetが提供を開始した「様々なドキュメント・帳票データセット」は、大規模言語モデル(LLM)、OCR、マルチモーダルAIといった先進的なAI技術の開発・研究にとって、非常に価値のある基盤となります。
業務文書特有の複雑さや機密性といった課題をクリアし、権利処理済みの高品質なデータを迅速に提供することで、AI開発者はデータの収集や整備にかかる負担を大幅に軽減し、より本質的なモデル開発に集中できるようになります。これにより、企業の業務自動化やDX推進がさらに加速し、AIが社会の様々な分野で活躍する未来がより一層現実のものとなるでしょう。
AI技術の進化は、データの質と量に大きく依存します。Qlean Datasetのようなデータソリューションは、AI開発の根幹を支え、新たなイノベーションの創出に不可欠な存在と言えます。今後も、Qlean Datasetのデータラインナップ拡充と、AI開発への貢献に注目が集まります。